import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier#展示一张数图。
img_arr = plt.imread("./data/3/3_140.bmp")
img_arr.shape
plt.imshow(img_arr)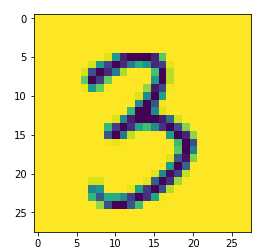
feature = []
target = []
for file in range(10):
for img in range(1,501):#./data/3/3_140.bmp
img_path = "./data/%s/%s_%s.bmp"%(str(file),str(file),str(img))
img_arr = plt.imread(img_path)
feature.append(img_arr)
target.append(file)feature = np.array(feature)
target = np.array(target)feature = feature.reshape((5000,784))
feature.shapenp.random.seed(10)
np.random.shuffle(feature)
np.random.seed(10)
np.random.shuffle(target)#训练集4980,测试集数据20
x_train = feature[:4980]
y_train = target[:4980]
x_test = feature[4980:]
y_test = target[4980:]#创建训练模型
#n_neighbors可以适当调整
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)print('模型分类的结果:',knn.predict(x_test))
print('真实的分类结果:',y_test)
"""
模型分类的结果: [6 6 4 4 0 8 5 8 2 2 4 3 3 9 4 1 6 2 9 2]
真实的分类结果: [6 6 4 4 0 8 5 8 2 2 4 3 3 9 4 2 6 2 9 2]
"""
#倒数第5个不一样,剩下都一样。ex_img_arr = plt.imread('./数字.jpg')
plt.imshow(ex_img_arr)img_two_arr = ex_img_arr[80:150,140:190,:]
plt.imshow(img_two_arr)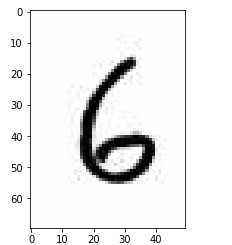
img_two_arr.shape
"""
(70, 50, 3)
"""img_two_arr = img_two_arr.mean(axis=2)import scipy.ndimage as ndimage
img_two_arr = ndimage.zoom(img_two_arr,zoom=(28/70,28/50))plt.imshow(img_two_arr)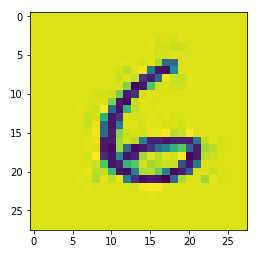
img_two_arr.shape#(28, 28)
img_two_arr = img_two_arr.reshape((1,-1))#(1, 784)knn.predict(img_two_arr)
"""
array([6])
"""github源码和数据:点击此处
原文:https://www.cnblogs.com/xujunkai/p/12130187.html