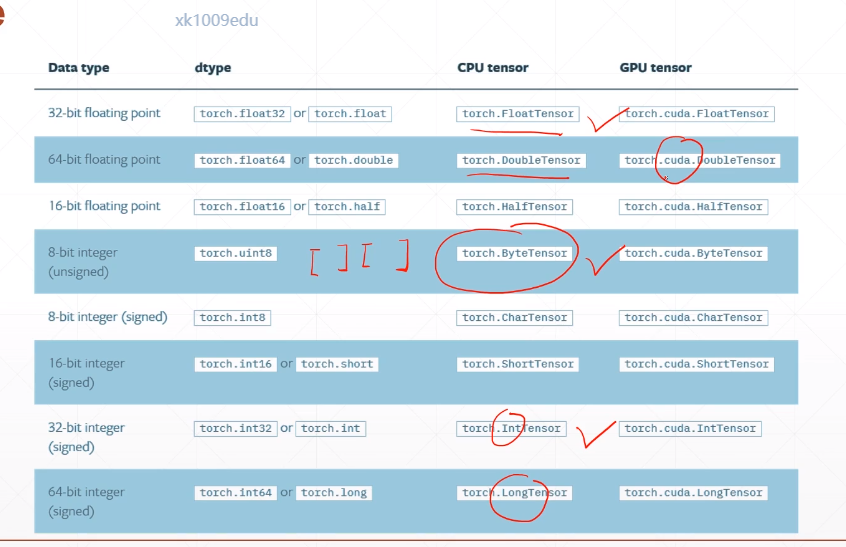
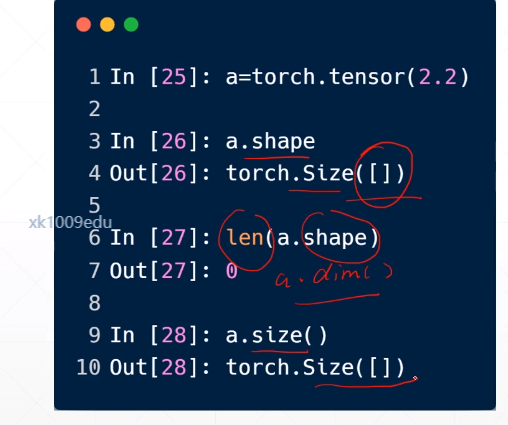
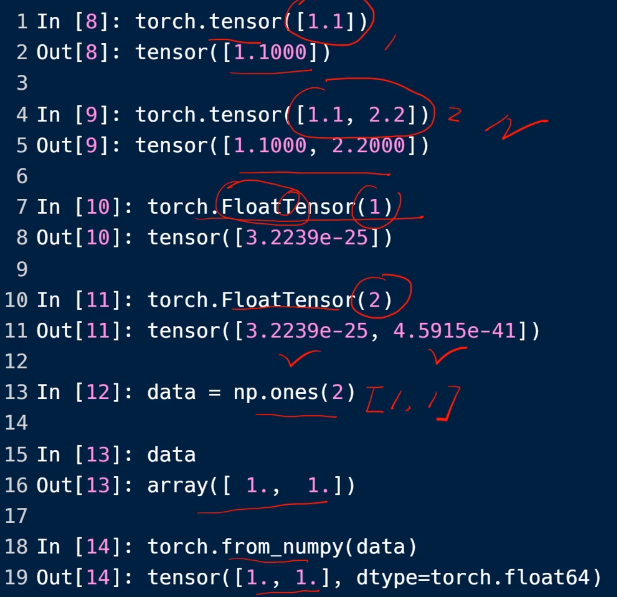
dim是几行
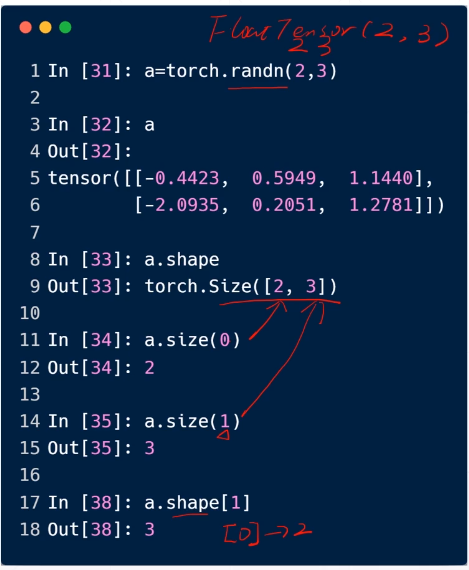
randn:随机正态分布
rand:随机0-1均值分布
randint(m, n):从m到n的随机化,但不包含n
使用:
torch.full([2,3], 7)
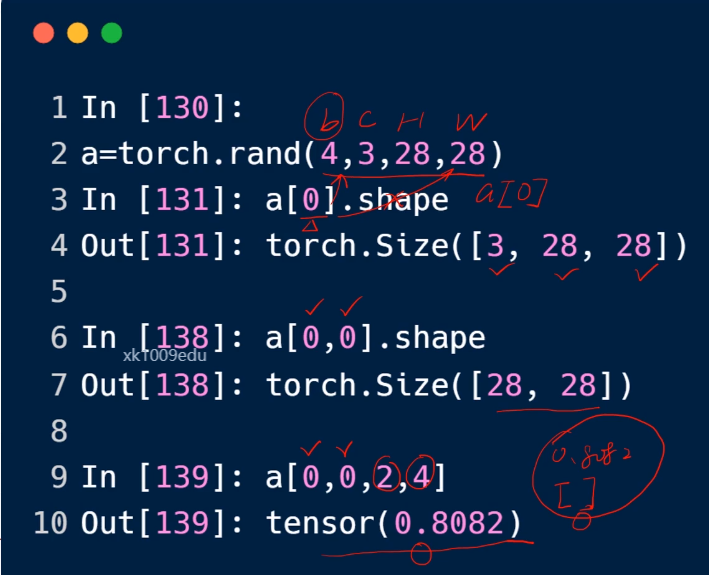
a[0].shape:表示第0个维度数据
a[0, 0, 2, 4]:具体的某个标量
a[:2]:从0到2的索引,但不包含2
‘a[: 1]‘:从第一个到索引为1
a[-1:]:从最后一个到最后一个(-1表示倒数第一个)
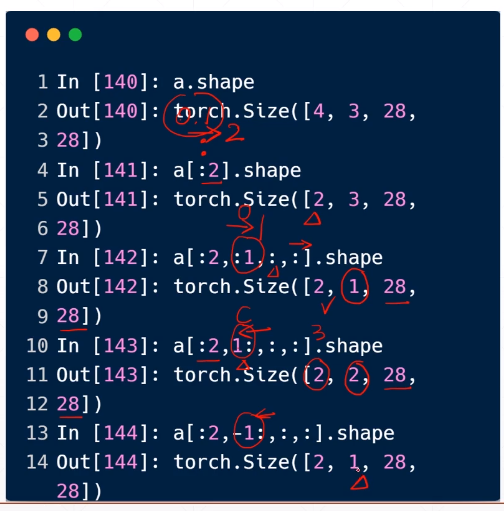
a[0 : 28 : 2]
a[: : 2]
out.shape = torch.Size([2, 3 ,28, 28])
a.index_select(2,torch.arange(8)).shape
表示在第二个维度上取0:8,输出
torch.Size([4,2,8,28])
三个.
a[... , : 2].shape
torch.Size([4, 3, 28, 2])
take先将几行几列变成一行n列
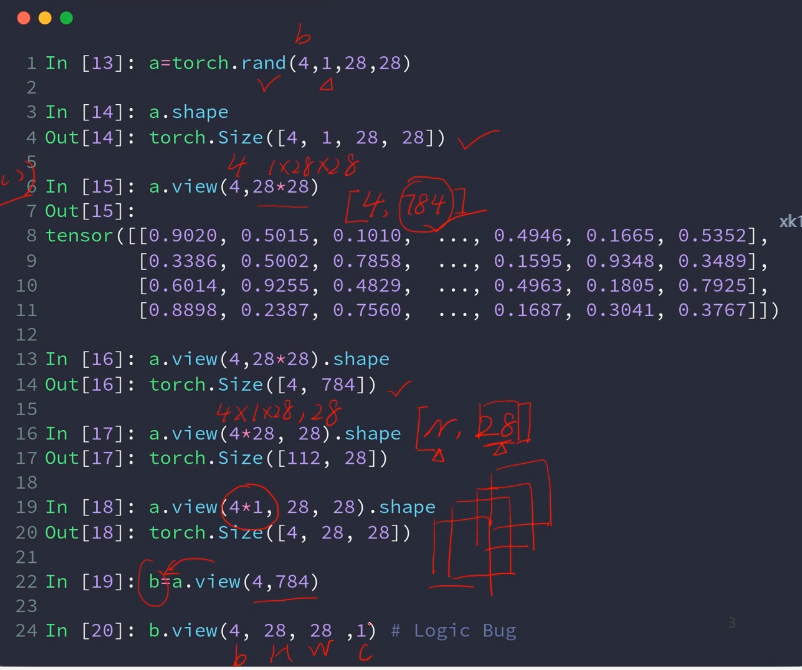
可插入的位置为[-5, 5)。
0为第一个位置,-1为最后一个数的后面,和4相同,5会报错
a.unsqueeze(4)

实例
将b的维度扩展到f相同维度
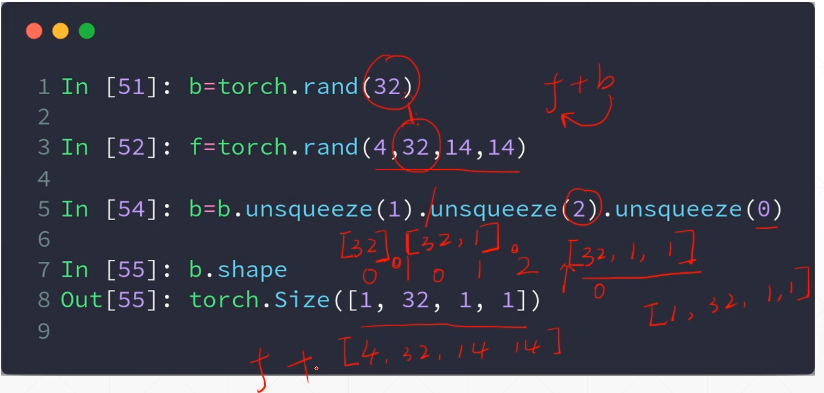
b.squeeze():能压缩的都压缩(压缩为1的通道)
b.squeeze(0)压缩第0个通道
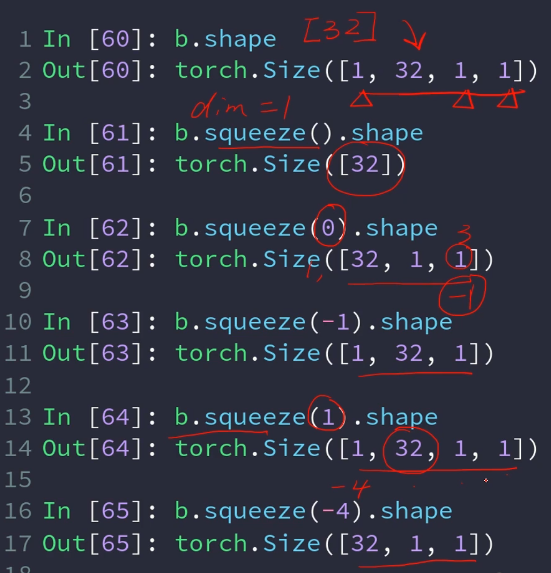
区别:
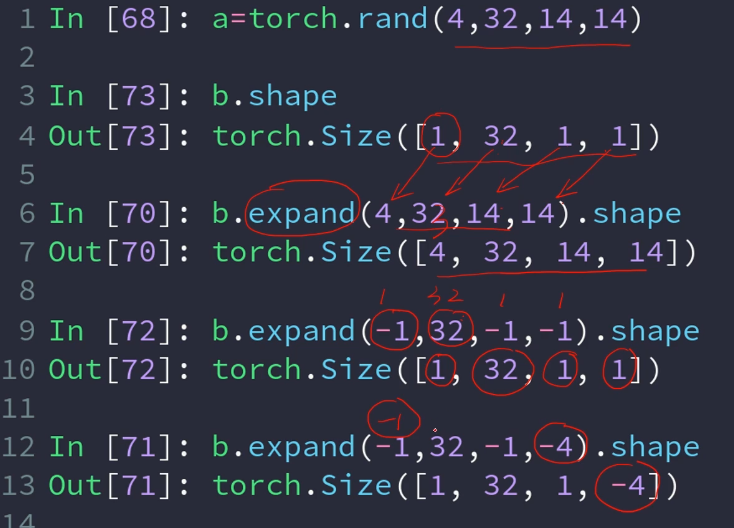
表示复制的此处,如32表示复制32次
不推荐使用
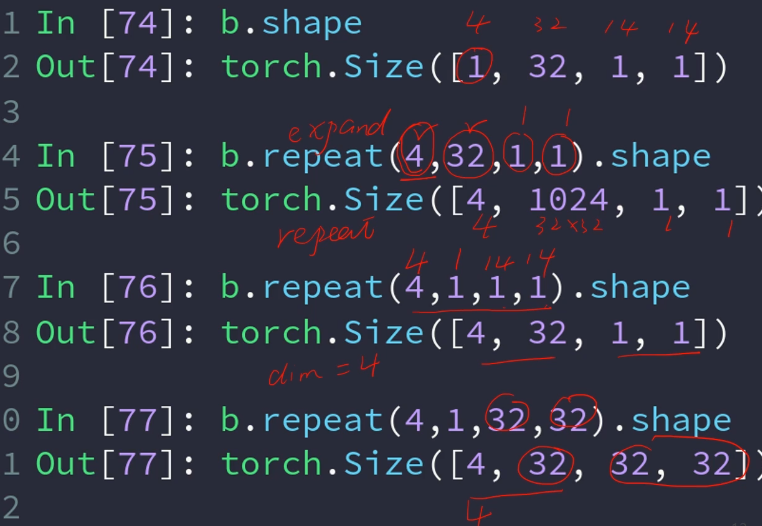
只针对2维的tensor,其他的不行
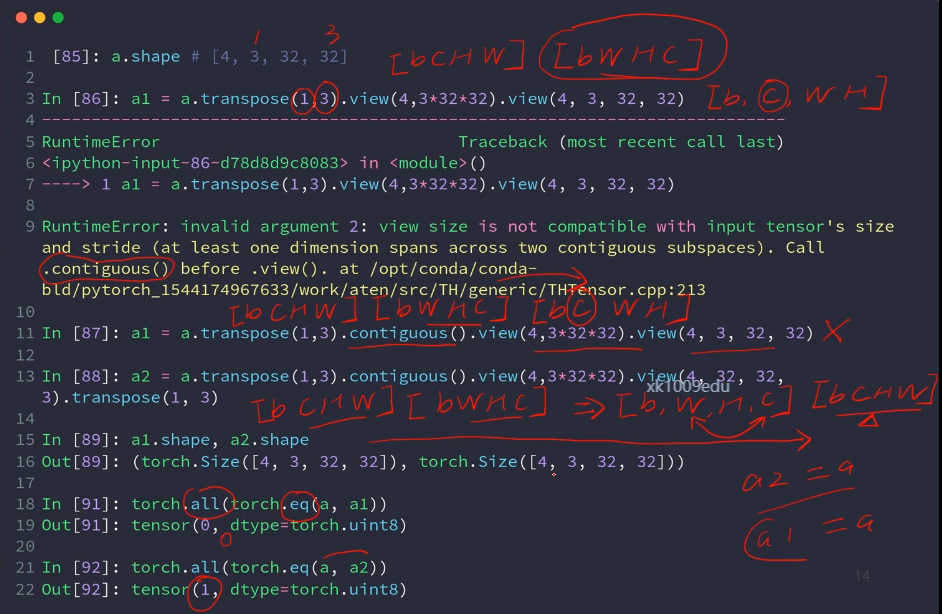
内部自己调用transport,直接用先前的位置标号来重组现在的维度。
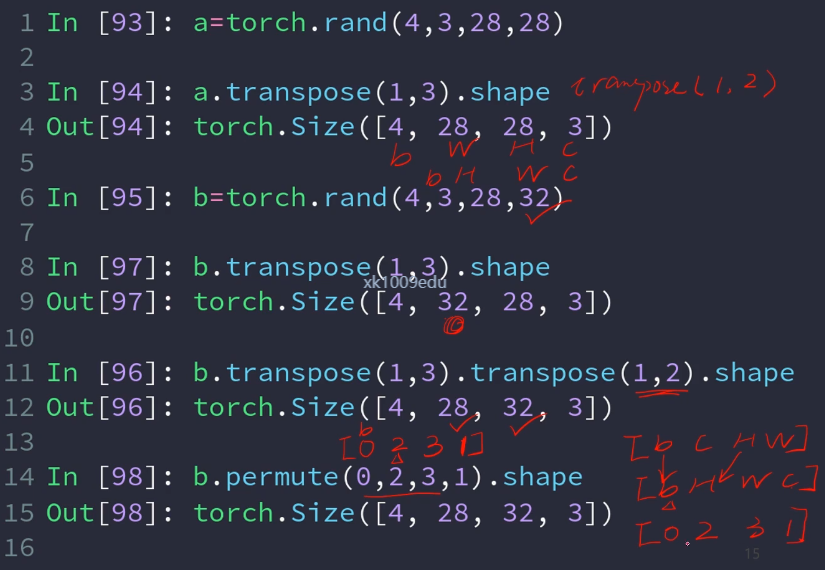
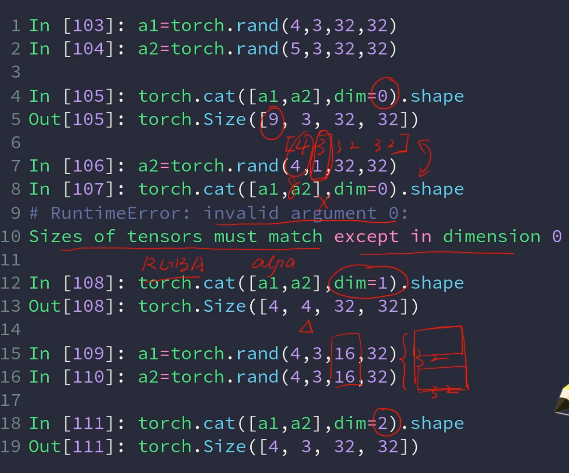
某个维度上进行合并,必须保证其他维度一致,否则会出错
将两个相同维度的tensor扩展为成2维,必须保证两个tensor维度相同
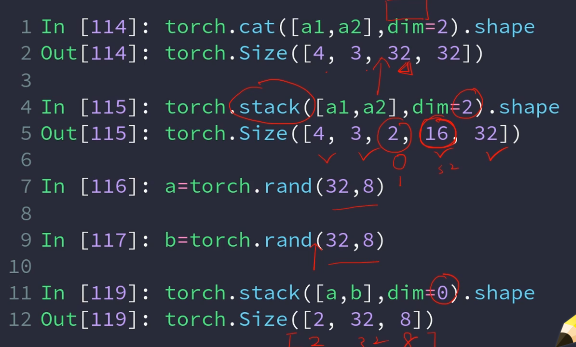
两种方式:
注意:
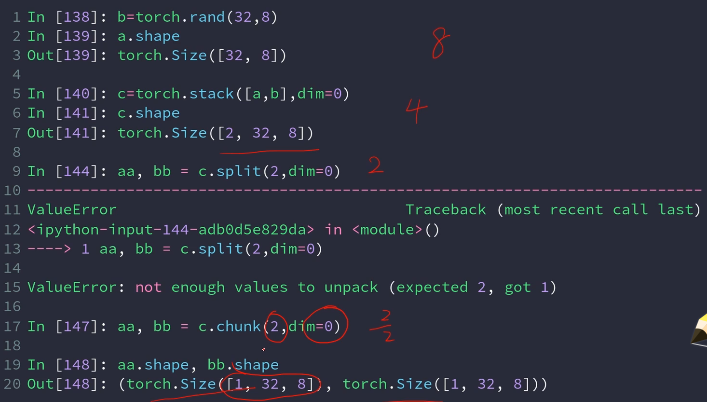
2不能被2拆分
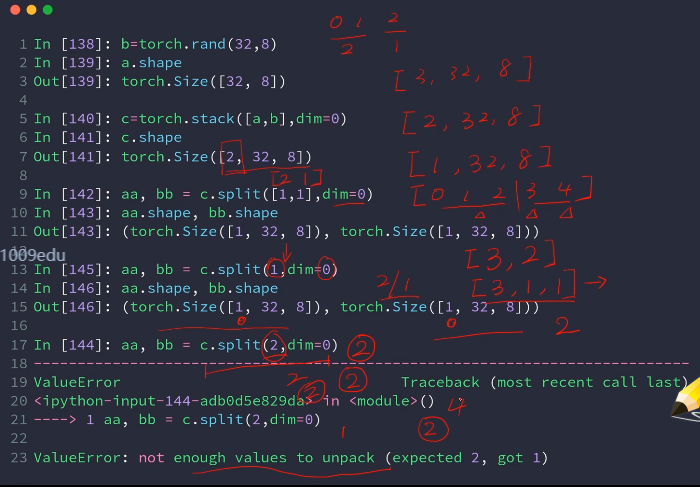
指定拆分为多少块,和split中的第二种方法一致
重载符号:+-* /
或者:add,sub,mul,div
注意:这里的乘是元素相乘
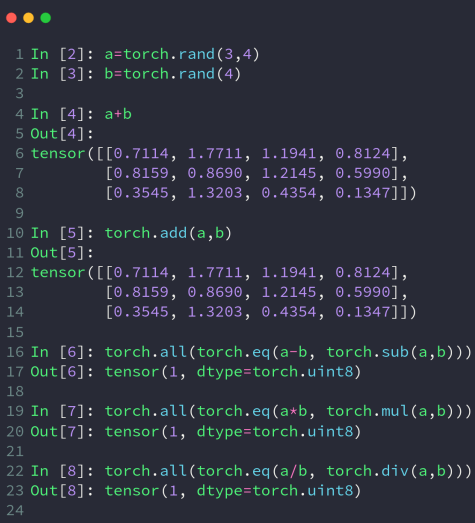
4种相加
x = torch.rand(5, 3)
y = torch.rand(5, 3)
#第一种
print(x + y)
#第二种
print(torch.add(x, y))
#第三种
result = torch.empty(5, 3)
torch.add(x, y, out=result)
print(result)
#第四种
y.add_(x)
print(y)torch.mm针对2维
torch.matmul所有维度(推荐使用)
@是上述matmul的重载使用
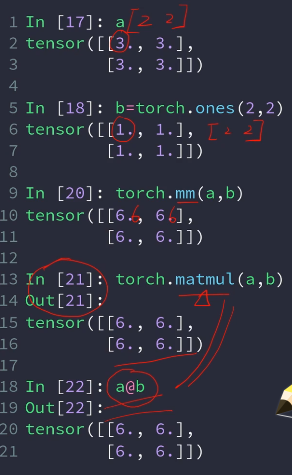
多于2维相乘

用法:
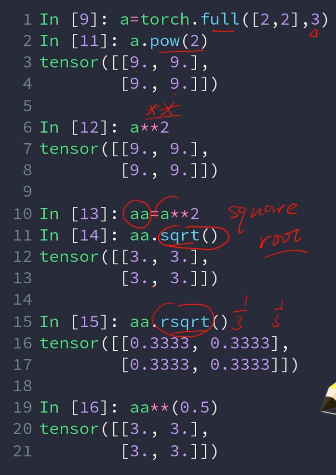
exp()
log():默认e为低,可以换,log2()
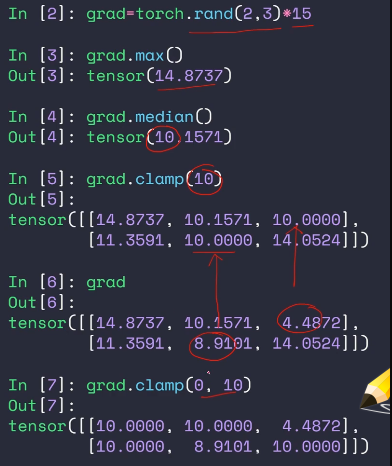

prod:返回所有元素乘积
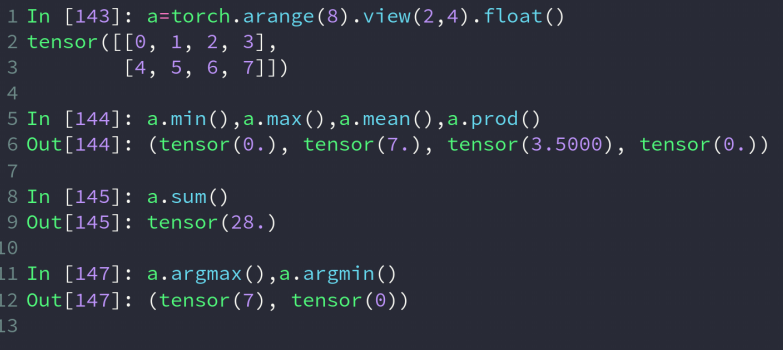
默认为把所有数据打平后再来计算最大最小值所在位置
可以指定某个维度上来计算,如右侧例子中,在1维上,那么是对每行中找出列最大的值,返回4个数,同理在0维时
max(dim = n)会返回一个在n维上的最大值,并将索引一起返回
argmax只会返回索引
keepdim = true,会保留先前的维度,比如这里保留为4, 1

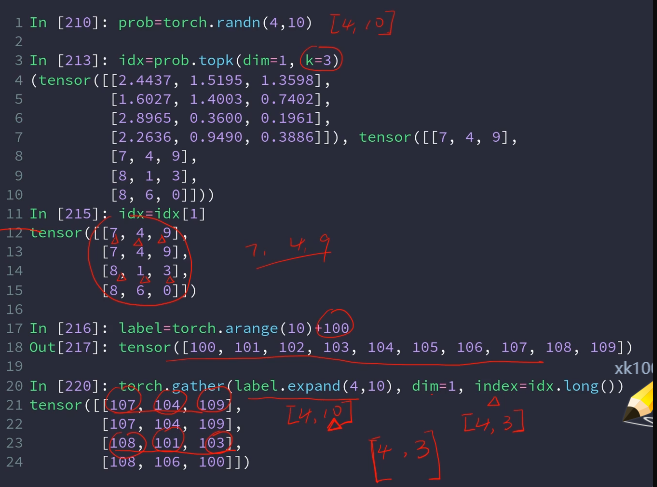
topk:前几个大的,返回数值和索引
kthvalue:第几小,默认从小到大排序,返回值和索引
>和gt一样
eq是比较每一个元素
equal是比价两个是否全等
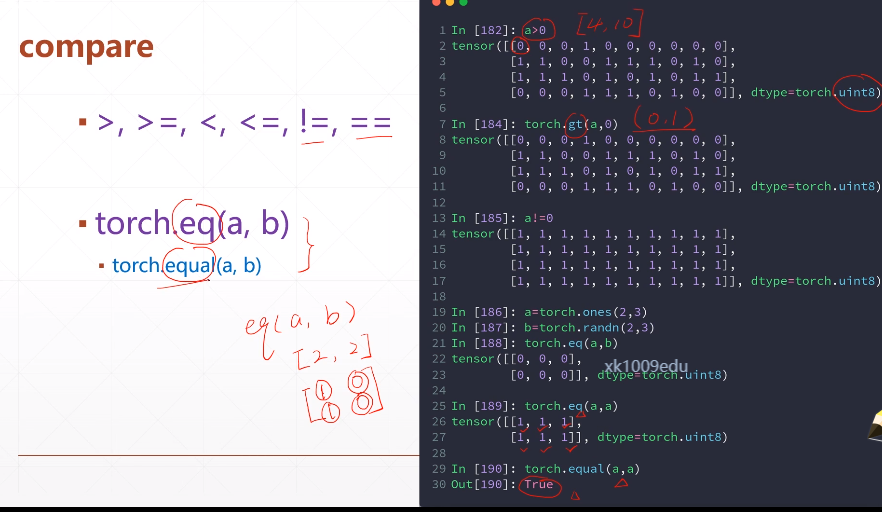
方便GPU调用
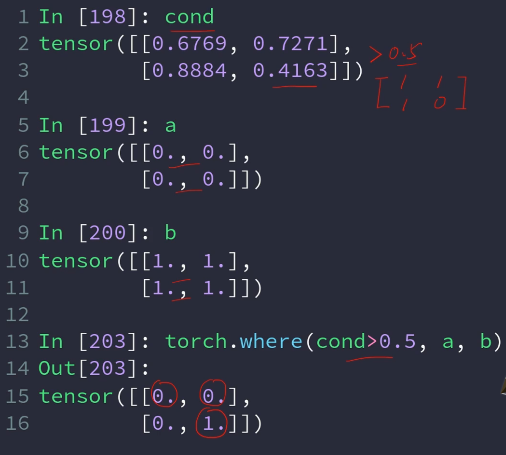
查表:从局部的到全局的转变,利用GPU进行

先把要查的对象扩展到和表一样的大小
凯明初始化
learning rate要合适小
逃离最小值:在局部极小值的时候,需要一个惯性逃离极小值,具体还不是很懂
tanh在RNN中经常使用
线性划分十个单元和各个激活函数表示:
a = torch.linspace(-1,1,10)
torch.sigmoid(a)
torch.tanh(a)
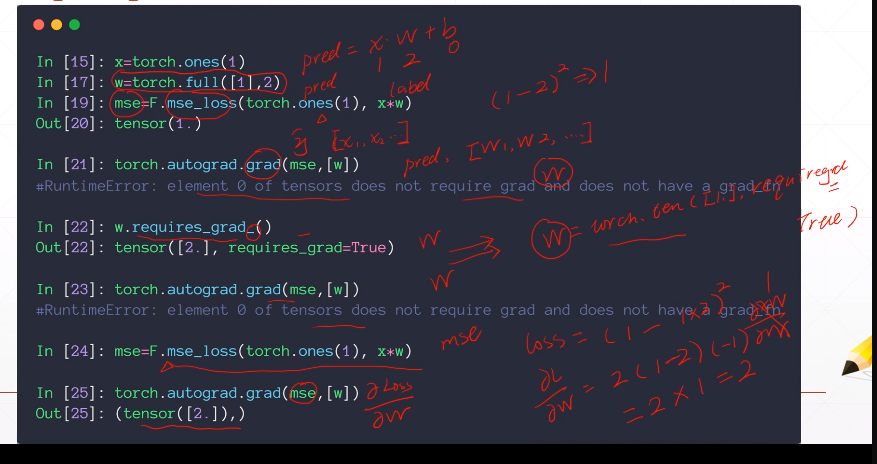
torch.relu(a)torch.norm(y- pred, 2).pow(2)
autograd.grad
loss.backward
mse.backward()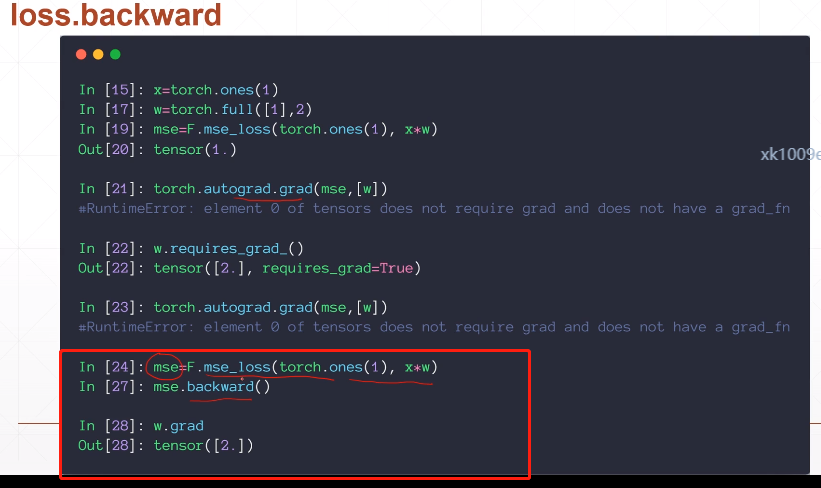
总结:

对于backward类型:如果Tensor是一个标量(即它包含一个元素数据)则不需要为backward()指定任何参数, 但是如果它有更多的元素,你需要指定一个gradient 参数来匹配张量的形状。
注意,要想使x支持求导,必须让x为浮点类型,也就是我们给初始值的时候要加个点:“.”。不然的话,就会报错。
loss.backward()在调用前需要清除已存在的梯度,否则梯度将被累加到已存在的梯度
net.zero_grad() # 清除梯度


从输出到前面每一层的迭代然后链式法则计算
学习率优化
第一步初始化,lr为学习率
每一次迭代需要将上一步的梯度先清0
optimizer.step()是更新x、y的梯度
optimizer = torch.optim.Adam([x], lr=1e-3)
optimizer.zero_grad()
pred.backward()
optimizer.step()
逻辑:因为用了sigmoid函数
regression:默认MSE为这个问题,最小均方差
量化分布的概率,如果某个概率确定,那么确定性越高
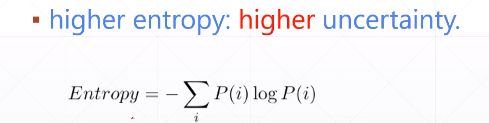
对两个或者多个的概率分布,统计两个概率重合程度(或者散度)
越小越好
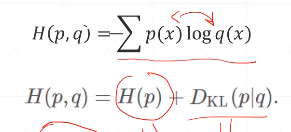
对于P = Q
H(p,q) = H(p)
对于one-hot分类
H(p,q) = D(p|q)
y为某个对象的概率的真实值,p为网络学习到的值(自己的计算值)
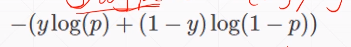
不使用MSE而使用交叉熵
交叉熵下降更大
MSE更加简单,也需要尝试
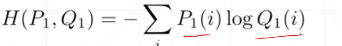
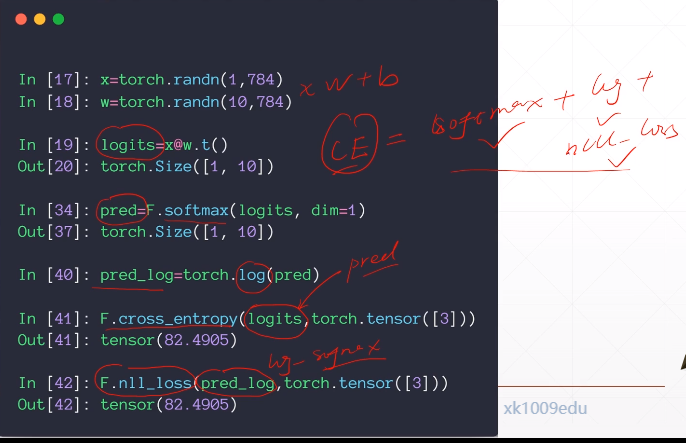
关键:初始化很重要,用凯明初始化,不要乱随机初始化
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)nn.Linear(in, out) : 全连接层
能用relu的地方要用relu,除非RGB像素重建
inplace的操作,会节省内存

类风格和函数风格调用
类风格中的参数都封装起来了,需要另外调用,但更安全。

不用自己管理参数,直接在net.parameters()中
net = MLP()
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss()SELU和softplus
第一步:device = torch.device(‘cuda:0‘)
第二步:把需要加速的放到GPU中,加.to(device)
如net = MLP().to(device)
data, target = data.to(device), target.cuda()
criteon = nn.CrossEntropyLoss().to(device)
注意:.cuda()不推荐使用,cuda:0是使用那张显卡
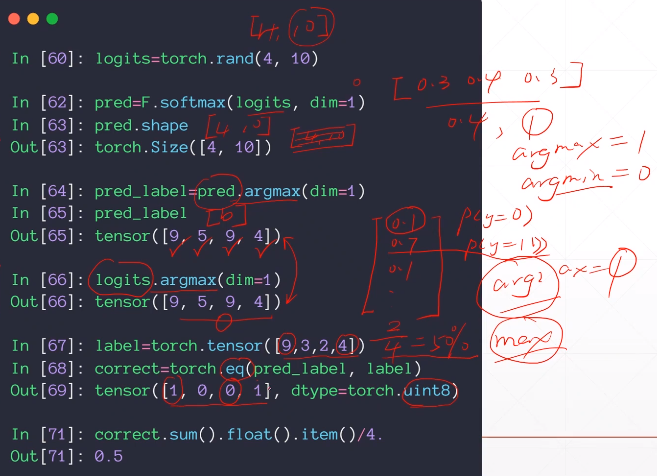
求出softmax后的最大值索引
与目标进行比较
相同的为1,并求多少个1
最后求比例
pip install -e .cd ../..python -m visdom.serverviz.line([0.], [0.], win=‘train_loss‘, opts=dict(title=‘train loss‘))
viz.line([loss.item()], [global_step], win=‘train_loss‘, update=‘append‘)双曲线
第一个定义有几根曲线,后面定义横坐标
viz.line([[0.0, 0.0]], [0.], win=‘test‘, opts=dict(title=‘test loss&acc.‘,
legend=[‘loss‘, ‘acc.‘]))
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win=‘test‘, update=‘append‘)可视化图
viz.images(data.view(-1, 1, 28, 28), win=‘x‘)
viz.text(str(pred.detach().cpu().numpy()), win=‘pred‘,
opts=dict(title=‘pred‘))过拟合:因为模型大小有限,而构建的模型太过复杂,导致过分拟合数据,测试的时候效果则反而不行
欠拟合:模型太过简单,不能很好的抽象出现在的模型
泛化能力:能够找到合适的模型来描述现在的数据集模型,且能迁移
关键:如何检测过拟合,如何降低欠拟合
把数据集分成三份,train set val set test set
前两个是自己拿到的,后面一个是客户或者其他人持有用来验证的
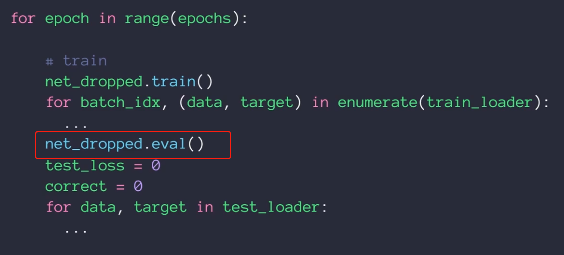
如何检测已经过拟合
在测试数据集出现准确率下降时,这个时候需要保存这个模型,防止进一步的数据过拟合
pytorch只能分成两份,因此需要人为的自己分开
train_db = datasets.MNIST(‘../data‘, train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
test_db = datasets.MNIST(‘../data‘, train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_loader = torch.utils.data.DataLoader(test_db,
batch_size=batch_size, shuffle=True)
print(‘train:‘, len(train_db), ‘test:‘, len(test_db))
train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000])
print(‘db1:‘, len(train_db), ‘db2:‘, len(val_db))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(
val_db,
batch_size=batch_size, shuffle=True)在代价函数中加入一项:
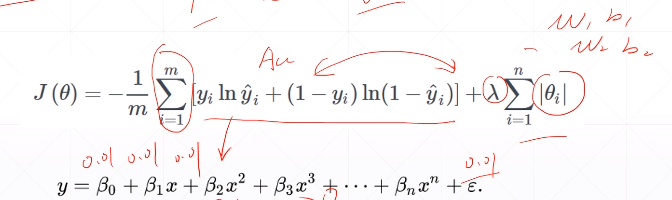
这个也叫weight Decay
常用两种方法

λ是一个超参数,θ为w或者b,下面是2范数情形,1范数时需要人为的自己写一下。


减小随机性,跳过局部极小点
一开始选用比较大的学习率,后面减小,有两个方案
有个经验选择在这里面,当准确率不再上升,或者下降一定程度时就停掉学习,输出模型

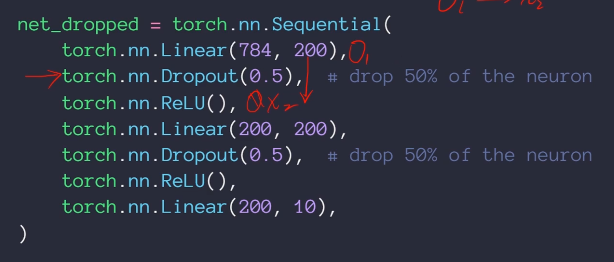
将一个完整的数据集分成多个batch输入训练,因为把所有数据集放进去这个不大可能,显存不够大。
pytorch调用
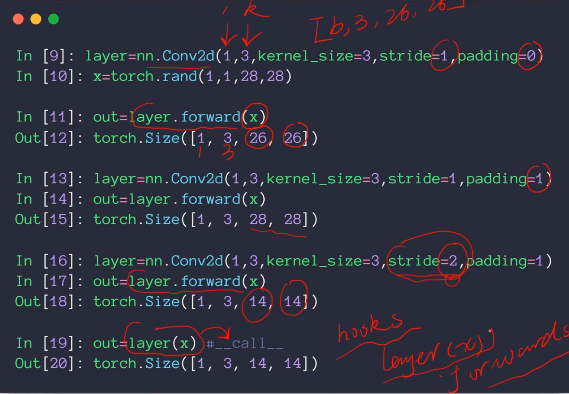
nn.Conv2d(in, out, kernel_size = n, stride = m, padding = l)
可以直接用layer(x),pytorch帮助完成forward操作
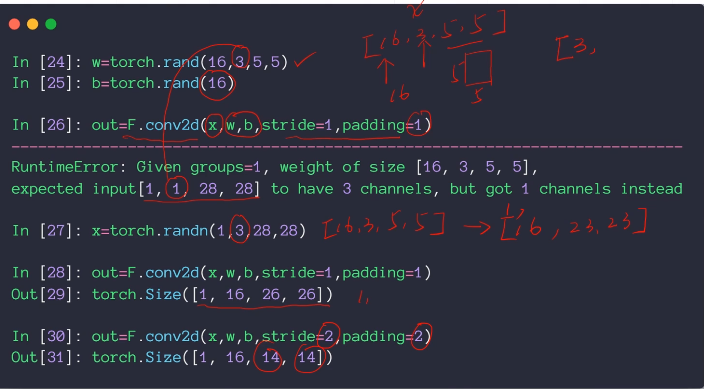
另外一种调用方法,通过函数类型
注意:通道的数目要注意
最大池化和平均池化,优先使用最大池化

上采样:是pytorch中特有的,不再使用upSample函数,而是F.interpolate

过滤掉为负值的点,增加非线性化
inplace一般设置为true,这样替换掉前者,节省空间

当使用sigmoid函数时,为了保证梯度下降更快,不出现梯度离散现象,对现有的数据进行N(0~1)c操作。
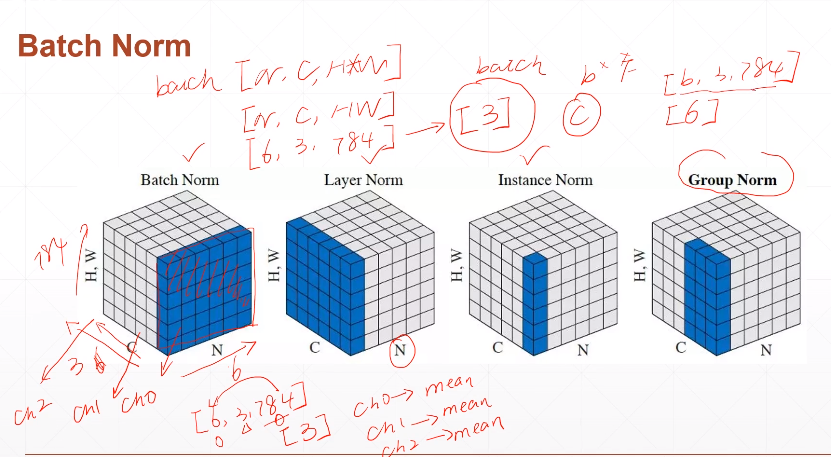
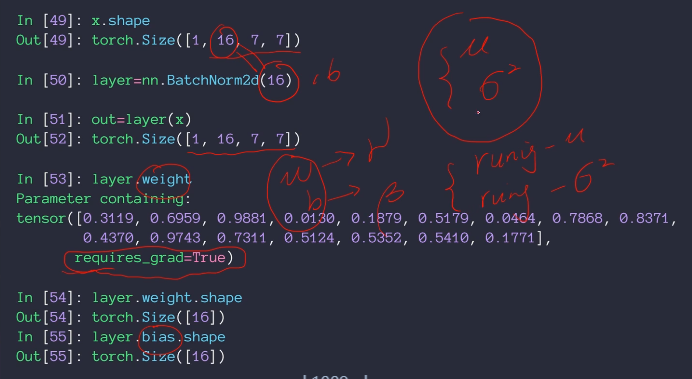
做法:找出平均值,然后当前值减去平均值除以最大最小值差,pytorch调用BatchNorm2d
写网络时,直接继承这个类,就可以方便的管理网络参数训练。
自定义继承这个类时也可以加到parameter中去。
后面再回过头来补充
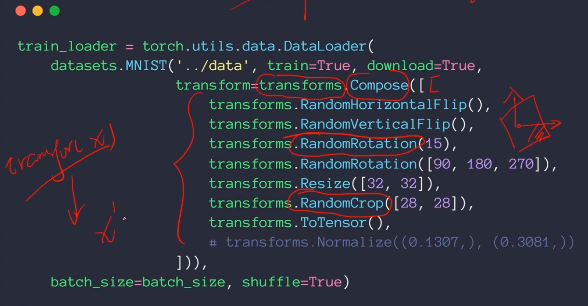
pytorch可以直接自己做一些简单的数据增强,不需要自己生成一些图片。
包括旋转,镜像,随机剪切等几何操作
这里主要是针对RNN,梯度离散在CNN中也同样存在,在网络结构层数变多时,梯度下降会导致最前面的网络权值基本不变,导致层数增加也不会使网络效果变好。
RNN优化方法是LSTM
数据集需要reshape到同一个尺寸,网络才好训练
然后将reshape的图进行数据增强
增强后归一到一个比例上
最后转换为tensor
torch.lerp(star, end, weight) : 返回结果是out= start+ (end-start) * weight
torch.rsqrt(input) : 返回平方根的倒数
torch.mean(input) : 返回平均值
torch.std(input) : 返回标准偏差
torch.prod(input) : 返回所有元素的乘积
torch.sum(input) : 返回所有元素的之和
torch.var(input) : 返回所有元素的方差
torch.tanh(input) :返回元素双正切的结果
torch.equal(torch.Tensor(a), torch.Tensor(b)) :两个张量进行比较,如果相等返回true,否则返回false
torch.ge(input,other,out=none) 、 torch.ge(torch.Tensor(a),torch.Tensor(b)) 比较内容:
ge: input>=other 也就是a>=b, 返回true,否则返回false
gt: input> other 也就是a>b, 返回true,否则返回false
lt: input<other 也就是a<b, 返回true,否则返回false
torch.max(input): 返回输入元素的最大值
torch.min(input) : 返回输入元素的最小值
element_size() :返回单个元素的字节
引用连接
原文:https://www.cnblogs.com/muche-moqi/p/12131603.html