1.背景
项目需求中有一个是记录人员出勤数据,在此数据的基础上找到7天未打卡的人员.分析实现:首先找到人员进出数据中最近的那条,根据人员id进行分组,对分组后的数据进行筛选.
2.原始sql长这样
SELECT MAX(ar.clock_time) as clock_time, ar.inout_type, ar.person_id, pi.person_name, pi.id, pi.phone, pc.card_no, sec.section_id sectionId, sec.section_name, pc.persion_position, pc.person_type, sec.section_state FROM cp_attend_record ar LEFT JOIN cp_person_info pi ON ar.person_id= pi.id LEFT JOIN cp_person_card pc on pi.id = pc.person_id LEFT JOIN cp_proj_section sec ON sec.section_id = ar.section_id GROUP BY ar.person_id HAVING (SELECT DATEDIFF(NOW(),MAX(ar.clock_time)) AS DiffDate)>7 AND section_state = ‘01‘ AND clock_time > IFNULL((SELECT max(clock_time) from cp_attend_abnormal_log),‘0‘) ORDER BY clock_time desc
语句关联了3个表,执行时间再2点多秒左右,时间有点长,在接口中体现更为明显,前后台交互总时间达到7s以上
3.优化思路
参考网上给出的内联表查询的一般执行过程是:
(1 ) 执行from语句
(2) 执行on过滤
(3) 添加外部行
(4) 执行where条件过滤
(5) 执行group by分组语句
(6) 执行having
(7) select列表
(8) 执行distinct去重复数据
(9)执行order by字句
(10)执行limit字句
3.1 分析
explain一下,发现关联的表中都添加了索引.
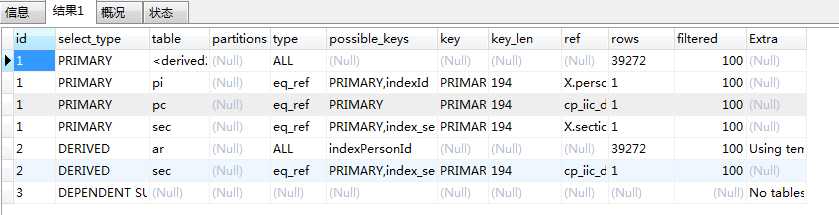
从执行顺序可以看的出来,原来的sql语句是先进行关联,在从关联后的表中进行分组,进而筛选数据,这样就造成内联表数据冗余,执行效率缓慢.所以优化的思路就是先将目标数据查询出来,在与其他表进行关联
4.优化后的语句
SELECT
X.clock_time as clock_time,
X.person_id,
pi.person_name,
pc.card_no,
sec.section_id sectionId,
sec.section_name,
pc.persion_position,
pc.person_type,
sec.section_state
FROM(
SELECT
person_id,
MAX(ar.clock_time) as clock_time,
sec.section_state,
ar.section_id
FROM cp_attend_record ar
LEFT JOIN cp_proj_section sec ON sec.section_id = ar.section_id
GROUP BY ar.person_id
HAVING
(SELECT DATEDIFF(NOW(),MAX(ar.clock_time)) AS DiffDate)>7
and section_state = ‘01‘
and clock_time > IFNULL((SELECT max(clock_time) from cp_attend_abnormal_log),‘0‘)
ORDER BY clock_time desc
)X
LEFT JOIN cp_person_info pi ON X.person_id= pi.id
LEFT JOIN cp_person_card pc on pi.id = pc.id
LEFT JOIN cp_proj_section sec ON sec.section_id = X.section_id
优化后的语句执行顺序大概为先进行分组查询出7天未打卡的人员,作为新建的临时表,再去关联其他表.
执行时间大概为0.6s左右,优化效率并没有提高很多,与之前相比,仅有一点改进.
猜测原因可能是查询的字段涉及在不同的表中,导致在新建临时表是也关联的其他表,最后又关联了一次,数据仍然产生了冗余.
end!
原文:https://www.cnblogs.com/fyy151617/p/12132179.html