parse定义了处理URL的标准接口,实现URL的拆分,合并以及转换。
1.urlparse() url拆分
urlparse(urlstring,scheme=‘’,allow_ragments=True)
将url拆分为6部分:
结果为元组,可用参数或索引取值。
代码:

运行结果:
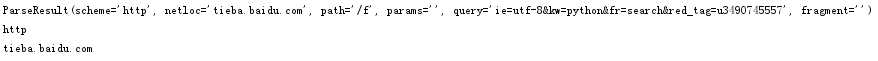
2.urlunparse() url合并
urlunparse([scheme,netloc,path,params,query,frament])
代码:

运行结果:

3.urlsplit()
和urlparse()相似,只是不再单独拆分params部分,将params合并到path中
4.urlunsplit()
和urlunparse()相似,唯一区别传入参数为5个
5.urljoin()
base_url作为第一个参数,新连接作为第二个参数,该方法会分析base_url中的scheme,netloc,path三部分内容,并对新链接确实的部分予以补充。
如果新链接中有这三部分,怎用新链接的,没有则用base_url中的。
而base_url中params,query,fragment不起作用。
6.urlencode()
在构造请求参数时非常有用,将字典类型的参数,序列化为url可用的参数。
7.parse_qs()
与urlencode()相反,把url参数反序列化为字典。
8.parse_qsl()
将url参数转化为元组组成的列表,运行结果为列表,列表的每一个元素为元组。
9.quote()
将url中中文参数转化为url编码的格式,避免因中文参数导致乱码。
10.unquote()
和quote()相反
原文:https://www.cnblogs.com/rong1111/p/12143001.html