操作系统用于协同或控制硬件之间进行工作,常见的操作系统有哪些
windows
linux
centos[公司上线一般用]
mac
编程语言的开发者写的一个工具,将用户写的代码转换成010101交给操作系统去执行。
解释型语言就类似于: 实时翻译,代表: Python/PHP/Ruby/Perl
编译型用于类似于: 说完之后,整体再进行翻译,代表:C/C++/java/GO
软件又称为应用程序,就是我们在电脑上使用的工具,类似于:记事本/图片查看/游戏
对于计算机而言无论是文件存储/网络传输输入本质上都是: 二进制(010101010101),如:电脑上存储视频/视图/文件都是二进制;QQ/微信聊天发送的表情/文字/语言/视频也全部都是二进制.
进制:
2进制,计算机内部
8进制
10进制,人来进行使用,一般情况下计算机可以获取10进制,然后在内部会自动转换为二进制并操作。
16进制,一般用于表示二进制(ong更短的内容表示更多的数据),一般是: \x开头.
解释器: py2/py3 (环境变量)
开发工具: pycharm
ASCII
Unicode
utf-8
gbk
gb2312
对于Python默认解释器编码:
py2: ascii
py3: utf-8
如果想要修改默认编码,则可以使用:
#!/usr/bin/env python # -*- coding:utf-8 -*-
注意: 对于操作文件时,要按照:以什么编码写入,就要用什么编码去打开。
为了复用,才有变量,只用一次的没有必要用变量
python2 : int 和 long python3 : int
# python2 中使用除法,只能保留整数位,如果要保留小数位: from __future__ import division value = 3/2 print(value) # python3 中/是保留小数的,想要只保留整数位,则使用//
| python语法 | 人类语言 | 计算机语言 |
|---|---|---|
| True | 真 | 1 |
| False | 假 | 0 |
除了None,"",0,[],{},()转换为布尔值为False外,其他数据都为True
Python的字符串是按照
Unicode编码存储的;字符串不可变;
# 转为大写 v = ‘nbchen‘ print(v.upper()) # NBCHEN
v = ‘NBchen‘ print(v.lower()) # nbchen
python3 引入了另一个更强的方法。 casefold()
lower() 方法只对ASCII编码,也就是‘A-Z’有效,对于其他语言(非汉语或英文)中把大写转换为小写的情况只能用 casefold() 方法
S2 = "ß" # 德语 print(S2.casefold()) # 德语的"ß"正确的小写是"ss"
v = ‘NBCHEN‘ print(v.isupper()) # True
v = ‘nbchen‘ print(v.islower()) # True
v = ‘nbchen‘ print(v.capitalize()) # Nbchen
v = ‘NBchen‘ print(v.swapcase()) # nbCHEN
v = ‘NBchen‘ print(v.startswith(‘NB‘)) # True
v = ‘NBchen‘ print(v.endswith(‘chen‘)) # True
v = ‘NBchen‘ print(v.count(‘n‘)) # 1
v = ‘nbchen‘ print(v.find(‘n‘),v.find(‘s‘),v.rfind(‘n‘)) # 0[默认从左开始找] -1[未找到] 5[从右开始找]
v1 = ‘1‘ v2 = ‘二‘ v3 = ‘②‘ print(v1.isdigit(),v1.isdecimal(),v1.isnumeric()) print(v2.isdigit(),v2.isdecimal(),v2.isnumeric()) print(v3.isdigit(),v3.isdecimal(),v3.isnumeric()) """ 方法/变量 isdigit isdecimal isnumeric ‘1‘ True True True ‘二‘ False False True ‘②‘ True False True """ # 所以推荐用 isdecimal 判断是否为 10 进制的数
除了判断数字外,还有方法:
判断是不是数字和字母
v = "nbchen2019" print(v.isalnum()) # True
判断是不是纯字母和汉字
v = "nbchen陈老大的猫" print(v.isalpha()) # True
# ps: \n 换行符 \t制表符 v = ‘ NBchen\t\n‘ print(v.strip()) # NBchen
strip除了可以去除空白,还有换行,制表符,还可以指定字符去除
v = ‘nbchen‘ print(v.strip(‘n‘),v.strip(‘nb‘)) # bche che
v = ‘nbchen‘
print(v.replace(‘n‘,‘c‘)) # cbchec
v = "陈老大的猫" print(v.encode(‘utf-8‘)) # b‘\xe9\x99\x88\xe8\x80\x81\xe5\xa4\xa7\xe7\x9a\x84\xe7\x8c\xab‘
v = "陈老大,的猫" print(v.split(‘,‘)) # [‘陈老大‘, ‘的猫‘]
除了上面,还有分区方法:
v = "陈,老,大,的,猫" print(v.split(‘,‘)) # [‘陈‘, ‘老‘, ‘大‘, ‘的‘, ‘猫‘] print(v.partition(‘,‘)) # (‘陈‘, ‘,‘, ‘老,大,的,猫‘) print(v.rpartition(‘,‘)) # (‘陈,老,大,的‘, ‘,‘, ‘猫‘)
v = "陈老大的猫:{}" print(v.format (‘任建宁‘)) # 陈老大的猫:任建宁
还可以用这种方法:
v = "{master}的猫:{sweeter}" print(v.format_map({‘master‘: ‘陈老大‘, ‘sweeter‘: ‘任建宁‘})) # 陈老大的猫:任建宁
v = "陈老大的猫" print(len(v)) # 5
v = "陈老大的猫" print(‘,‘.join(v)) # 陈,老,大,的,猫
v = "陈老大的猫" print(v.center(20,‘*‘)) # *******陈老大的猫********
填充除了居中,
还有居左
v = "nbchen" print(v.ljust(20,‘*‘)) # nbchen**************
居右
v = "nbchen" print(v.rjust(20,‘*‘)) # **************nbchen
还有别的方法:
v = "nbchen" print(v.zfill(20)) # 00000000000000nbchen # 比上面的方法要弱,只能补0
\t制表符v = "n\tb\tchen" print(v.expandtabs(tabsize=0)) # nbchen [tabsize默认为8]
v = "\t" print(v.isprintable()) # False
v = " " print(v.isspace()) # Truev.isprintable()
v = "Nbchen Is Nb" print(v.istitle()) # True
a = "chen" b = "1234" table = str.maketrans(a,b) # 将c映射为1,h映射为2,e映射为3,n映射为4 print(table) # {99: 49, 104: 50, 101: 51, 110: 52} ? v = ‘nbchen‘ print(v.translate(table)) # 根据上面的映射表,转为为最终的字符串: 4b1234
len
索引
切片
步长
for循环
# 打开 -> 操作-> 关闭 obj = open(‘路径‘,mode=‘模式‘,encoding=‘编码‘) obj.write() obj.read() obj.close()
r / w / a
r+ / w+ / a+
rb / wb / ab
r+b / w+b / a+b
read() : 全部读到内存
read(1)
1 表示一个字符

# log.txt 文件内容: ‘‘‘ 测试文件读取 ‘‘‘ obj = open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) data = obj.read(1) # read(1)在r模式下: 读一个字符 obj.close() print(data) # 测
1 表示一个字节
obj = open(‘log.txt‘,mode=‘rb‘) data = obj.read(3) # read(1)在rb模式下: 读一个字节 obj.close() print(data) # b‘\xe6\xb5\x8b‘ print(data.decode(‘utf-8‘)) # 测
write(字符串) :
obj = open(‘log.txt‘,mode=‘w‘,encoding=‘utf-8‘) data = obj.write(‘插进去‘) # write(字符串)在w模式下写入 obj.close() # log.txt 被插入后 : ‘‘‘ 插进去 ‘‘‘
write(二进制) :
obj = open(‘log.txt‘,mode=‘wb‘) data = obj.write(‘再插进去‘.encode(‘utf-8‘)) # write(字符串编码为二进制)在wb模式下写入 obj.close() # log.txt 被插入后 : ‘‘‘ 再插进去 ‘‘‘
seek : 光标字节位置, 无论模式是否带b,都是按照字节进行处理
tell :获取当前光标所在的字节位置
# log.txt 内容: ‘‘‘ 再插进去 ‘‘‘ obj = open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) obj.seek(3) # 光标在第三个字节的位置 position = obj.tell() # 获取当前光标所在的字节位置 data = obj.read() obj.close() print(data, position) # 插进去 3 # ps : 断点续传,本质上是根据seek,tell
flush : 强制将内存中的数据写入硬盘
# log.txt 内容: ‘‘‘ 再插进去 ‘‘‘ obj = open(‘log.txt‘,mode=‘a‘,encoding=‘utf-8‘) while True: v = input("请输入: ") # 输入: 我插入、 我再插入 obj.write(v) obj.flush() # 结果 : 再插进去我插入、我再插入 obj.close()
# 文艺 obj = open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) data = obj.read() obj.close() # 二逼 with open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) as v: data = v.read() # with as 操作完后自动关闭文件
# log.txt 内容: ‘‘‘ 再插进去 ‘‘‘ with open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) as obj: data = obj.read() print(data) # 再插进去 new_data = data.replace(‘再‘,‘第一次‘) with open(‘log.txt‘,mode=‘w‘,encoding=‘utf-8‘) as obj: obj.write(new_data) # log.txt 修改后的内容: ‘‘‘ 第一次插进去 ‘‘‘ # ps: 上面这种,全部读到内存,如果文件太大,就会撑爆内存
大文件修改:
# log.txt 内容: ‘‘‘ 第一次插进去 ‘‘‘ f1 = open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) f2 = open(‘log2.txt‘,mode=‘w‘,encoding=‘utf-8‘) for line in f1: new_line = line.replace(‘一‘,‘二‘) f2.write(new_line) f1.close() f2.close() # log2.txt 内容: ‘‘‘ 第二次插进去 ‘‘‘ # 简写: with open(‘log.txt‘,mode=‘r‘,encoding=‘utf-8‘) as f1, open(‘log2.txt‘,mode=‘w‘,encoding=‘utf-8‘) as f2: for line in f1: new_line = line.replace(‘一‘, ‘二‘) f2.write(new_line)
传参:位置参数>关键字传参
函数不被调用,内部的代码永远不会执行
每次调用函数时,都会为此次调用开辟一块内存,内存可以保存自己以后想要用的值
函数是作用域,如果自己作用域中没有,则往上级作用域找
if 条件:
v = ‘前面‘
else:
v = ‘后面‘
?
# 转为三目运算:
v = 前面 if 条件 else 后面
?
# 让用户输入值,如果是整数,则转为整数,饭后则赋值为None
data = input(‘>>‘)
v = int(data) if data.isdecimal() else None
print(v)
面向过程编程可读性和可重用性差
# 发送邮件封装 import smtplib from email.mime.text import MIMEText from email.utils import formataddr ? def send_email(): # 定义 msg = MIMEText(‘我爱你‘, ‘plain‘, ‘utf-8‘) msg[‘Form‘] = formataddr(["发送人的名字",‘发送人的邮箱‘]) msg[‘To‘] = formataddr(["被发送人名字","被发送人的邮箱"]) msg[‘Subject‘] = "主题" server = smtplib.SMTP("smtp@163.com", 25) server.login("发送人的邮箱", "密码") server.sendmail("发送人的邮箱", [‘被发送人的邮箱‘, ], msg.as_string()) server.quit() ? send_email() # 调用 # 如果发送不成功,可能是网易开了客户端授权密码,关闭即可
网上的案例
形参,实参
函数参数传递是内存地址(引用/值)
def join_list(a1, a2): result = [] result.extend(a1) result.extend(a2) # extend 拼接 print(result) # [11, 22, 33, 44, 55, 66] join_list([11, 22, 33], [44, 55, 66])
def join_list(a1, a2): result = [] result.extend(a1) result.extend(a2) return result # return 返回值; 不写默认return None v = join_list([11, 22, 33], [44, 55, 66]) print(v) # [11, 22, 33, 44, 55, 66] ? # 练习1.让用户输入一段字符串,计算字符串中有多少A字符的个数,有多少个就在文件a.txt中写多少个‘嘻‘ def get_char_count(data): sum = 0 for i in data: if i == ‘A‘: sum += 1 return sum ? def write_file(line): if len(line) == 0: return False with open(‘temp.txt‘,mode=‘w‘,encoding=‘utf-8‘) as f: f.write(line) return True ? content = input("请输入:") count = get_char_count(content) write_data = ‘嘻‘ * count status = write_file(write_data) if status: print("写入成功") # 特殊,返回元组 def test(): return 1,‘3‘,[‘43‘,‘ni‘] v = test() print(v) # (1, ‘3‘, [‘43‘, ‘ni‘])
5.2.4 函数的练习
# 3.读取文件,将文件的内容构造成指定格式的数据,并返回 """ a.log nbchen|23|175 Chen老大的猫|3|61 目标: a. [‘nbchen|23|175‘,‘Chen老大的猫|3|61‘]并返回 b. [[‘nbchen‘,‘23‘,‘175‘],[‘Chen老大的猫‘,‘3‘,‘61‘]] c. [ {‘name‘:‘nbchen‘,‘age‘:‘23‘,‘height‘:‘175‘}, {‘name‘:‘Chen老大的猫‘,‘age‘:‘3‘,‘height‘:‘61‘} ] """ ? print("开始读取文件") def get_str_2_list(): with open(‘a.log‘,mode=‘r‘,encoding=‘utf-8‘) as f: list = [] for line in f: print("每一行的内容%s" % (line, )) list.append(line.strip()) return list v = get_str_2_list() print("读取的集合:",v,"\n=======================") a = v # 第一题 ? def get_list_format(list): new_list = [] for i in range(0,len(list)): t = list[i].split(‘|‘) print("切割后得到数据:",t) new_list.append(t) return new_list v = get_list_format(v) print("格式化的集合:", v , "\n=======================") b = v # 第二题 ? def list_format_map(list): v = [‘name‘,‘age‘,‘height‘] list_dic = [] for item in range(0,len(list)): dic = {} print("集合中的每一项:", list[item]) for i in range(0, len(list[item])): print("集合中的子集合的每一项:", list[item][i]) print("字典的每个key:",v[i]) dic[v[i]]= list[item][i] print("集合中的子集合的每一项映射到字典:",dic) list_dic.append(dic) return list_dic v = list_format_map(v) print("格式化后的字典: ",v) c = v # 第三题 ? # 耗时:35分钟
python中一个函数是一个作用域;
java中一个代码块是一个作用域;
5.2.4.1 作用域赋值
子作用域中只能找到父级中的值,无法重新为父级的变量进行赋值
name = ‘nbchen‘ def func(): name = ‘陈老大的猫‘ # 在自己的作用域在创建一个这个的值 print(name) # 陈老大的猫 func() print(name) # nbchen ? # 列表修改的是里面的,字符串不可变. name = [‘nbchen‘, ‘陈老大的猫‘] def func(): name.append(‘陈某某‘) print(name) # [‘nbchen‘, ‘陈老大的猫‘, ‘陈某某‘] func() print(name) # [‘nbchen‘, ‘陈老大的猫‘, ‘陈某某‘]
如果非要对全局的变量进行赋值
name = ‘nbchen‘ def func(): global name name = ‘陈老大的猫‘ print(name) # 陈老大的猫 func() print(name) # 陈老大的猫 ? # 注意global改的是全局的,nolocal改的是上一级的.如果函数嵌套的时候,就要注意下
# 默认函数参数按顺序的, # 如果想要不按顺序传参,可以指定关键字即可 def func(a1,a2): print(a1,a2) # 2 1 func(a2=1,a1=2) ? # 传参和位置传参混用的时候,必须关键字传参在后面,而且,注意顺序 def func(a1,a2,a3): print(a1,a2,a3) # 1 3 4 func(1,a2=3,a3=4)
# 设置默认值后,参数可传可不传 # 看open源码: def open(file, mode=‘r‘, buffering=None, encoding=None, errors=None, newline=None, closefd=True): # ps: 默认参数如果是不可变类型,随便玩,如果是可变类型,这里会有个坑
# 动态接收位置参数 def eat(*args): print(‘我想吃‘,args) eat(‘大米饭‘,‘中米饭‘,‘小米饭‘) # 收到的结果是一个tuple元祖 ? # 不确定要接收多少个参数的时候,可以用动态参数 # 动态参数必须放在位置参数,默认参数后面 ? # 最终顺序: # 位置参数 > args(动态位置参数) > 默认值参数 > *kwargs(动态默认参数) ? # 综合使用: def func(*args,**kwargs): print(args,kwargs) func(1,23,5,a=1,b=6) func(1,*[23,5],**{a=1,b=6})
def func(): print(123) v1 = func func() v1() ? # 也可以放到列表[]里面,还可以放到集合{}里面,但是也注意去重的效果。 func_list = [func,func,func] for item in func_list: item() # 也可以放到字典{}里面 def func(): print(‘1‘) dic = {‘k1‘:func,‘k2‘:func} dic[‘k1‘]() ? # 函数名可以当做变量使用,当前参数传递
优雅的根据输入的参数执行函数的方式
def test1(): print(‘test1‘) def test2(): print(‘test2‘) def test3(): print(‘test3‘) def test4(): print(‘test4‘) info = { ‘f1‘: test1, ‘f2‘: test2, ‘f3‘: test3, ‘f4‘: test4 } choice = input("请选择要选择功能:") function_name = info.get(choice) if function_name: function_name() else: print("输入错误")
# 关键: 函数是由谁创建的,就从哪里开始找 """ name = ‘nbchen‘ def base(): print(name) # nbchen def func(): name = ‘陈老大的猫‘ base() func() """ ? """ name = ‘nbchen‘ def func(): name = ‘陈老大的猫‘ def base(): print(name) # 陈老大的猫 base() func() """
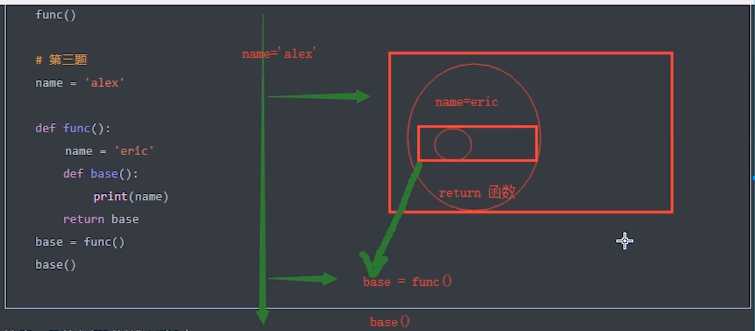
‘‘‘ info = [] def func(): print(item) for item in range(10): info.append(func) info[0]() # 9 ‘‘‘ ? info = [] def func(i): def inner(): print(i) return inner for item in range(10): info.append(func(item)) info[0]() # 0
def func(a1,a2): return a1 + a2 # 使用lambda func = lambda a1,a2 : a1 + a2 # 默认将运算的结果return回来 func = lambda : 100 # 无参,返回100 func1 = lambda x1: x1 * 100 func2 = lambda *args,**kwargs: len(args)+len(kwargs) ? print(func()) # 100 print(func1(2)) # 200 print(func2(1, 2, 3)) # 3
ps: lambda内部不能自己创建变量,只能用传递过来你的,或者找父级的变量
python lambda和java中的不太一样,别混淆了。
输入输出
print()
input()
强制转换
dict()
list()
set()
tuple()
int()
str()
bool()
数学
abs()
min()
max()
round()
float()
sum()
pow()
divmod() : 2个数相除,得商和余数
a,b = divmod(100,3) print(a,b) # 33,1 ? # 分页小李子 USER_LIST = [] for i in range(1,16): temp = {‘name‘: ‘插入第%s次‘%i,‘count‘:‘嗯*%s‘%i} USER_LIST.append(temp) ? # 数据总条数 total_count = len(USER_LIST) ? # 每页显示10条 per_page_count = 10 ? # 总页码数 max_page_num,a = divmod(total_count,per_page_count) if a > 0: max_page_num += 1 while True: pager = int(input(‘要查看第几页(1 ~ %s):‘%max_page_num)) if pager < 1 or pager > max_page_num: print(‘页码不合法,必须是1 ~ %s‘%max_page_num) else: start = (pager - 1) * per_page_count end = pager * per_page_count data = USER_LIST[start:end] for item in data: print(item)
进制
bin() : 将10进制转为2进制
oct() : 将10进制转为8进制
int() : 将2/8/16进制转为10进制
hex() : 将10进制转为16进制
编码
chr() : 将十进制数字转换成Unicode编码中的对应字符串
ord() : 根据字符在Unicode编码中找到其对应的十进制
import random
?
# 随机生成验证码
def get_random_code(length = 6):
data = []
for i in range(length):
v = random.randint(65,90)
data.append(chr(v))
return ‘‘.join(data)
?
print(get_random_code())
高级
map() :
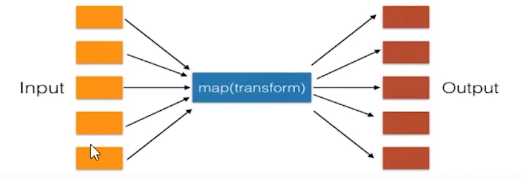
# v = [11,22,33,44] 将v每个数据+100 map(x,v) # 第一个参数必须是一个函数 # 第二个参数必须可迭代(可被for循环)

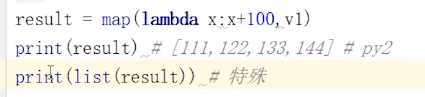
filter() :
v = [11,22,44,55,‘aa‘] def func(x): if type(s)==int: return True return False result = filter(func,v) print(list(result)) ? # lambda: v = [11,22,44,55,‘aa‘] result = filter(lambda x:type(x) == int,v) print(list(result))
reduce() :
python2在,python3被从内置中移除。
import functools v = [11,22,44] result = functools.reduce(lambda a,b:a+b,v) print(result)
其他
type()
len()
id()
range()
open()
?
# 1字节等于8位 # IP:192.168.17.151 -> 01010101. 00101010 . 00101011 . 00101011 ? # 1.请将ip = "192.168.17.151"中的每个十进制数转换成二进制并通过,连接起来生成一个新的字符串 ip = "192.168.17.151" ip_list = ip.split(‘.‘) # [‘192‘,‘168‘,‘17‘,‘151‘] result = [] for item in ip_list: result.append(bin(int(item))) print(‘,‘.join(result)) ? # 2.请将ip= "192.168.17.151"中的每个十进制数转换成二进制: # 0010101010101010010101010 -> 十进制的值
def get_md5(data): return hashlib.md5().update(data.encode(‘utf-8‘)).hexdigest()
虽然MD5不可逆,但是为了防止撞库破解,可以加盐
def get_md5(data): return hashlib.md5(‘salt‘).update(data.encode(‘utf-8‘)).hexdigest()
ps : 盐越长破解越难
# 应用场景: 登录注册加盐加密
import hashlib ? USER_LIST= [] ? def get_md5(data): obj = hashlib.md5() obj.update(data.encode(‘utf-8‘)) return obj.hexdigest() ? def register(): print(‘**********用户注册**********‘) while True: user = input(‘请输入用户名:‘) if user ==‘N‘: return pwd = input(‘请输入密码:‘) temp = {‘username‘:user,‘password‘:get_md5(pwd)} USER_LIST.append(temp) ? def login(): print(‘**********用户登录**********‘) user = input(‘请输入用户名:‘) pwd = input(‘请输入密码:‘) ? for item in USER_LIST: if item[‘username‘] == user and item[‘password‘]== get_md5(pwd): return True ? register() print(USER_LIST) result = login() if result: print(‘登录成功‘) else: print(‘登录失败‘) ? # import getpass 模块作用: 终端输入密码不显示
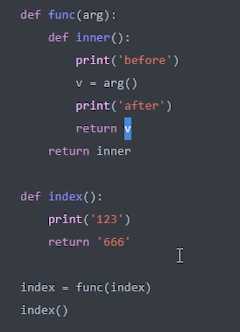

在不改变原来代码的前提下,在函数执行之前之后做操作。
import time ? # 计算函数执行时间 # 装饰器的编写 def get_time(arg): def inner(): start_time = time.time() # 执行之前 v = arg() end_time = time.time() # 执行之后之间 print(end_time - start_time) # 计时 return v return inner ? @get_time # 装饰器的应用 def func(): time.sleep(2) # 睡一下,执行时间 print(123) ? func()
对于要装饰有参数的函数,装饰器可以这样 写:
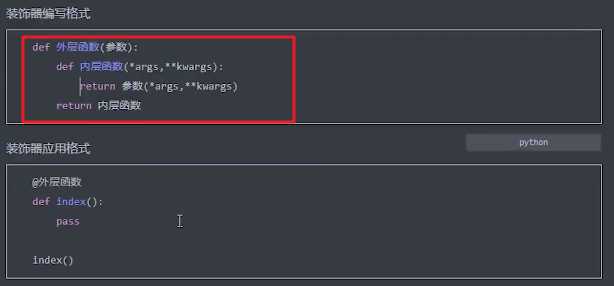
# 格式 vals = [i for i in ‘alex‘] # 变量 = [for循环的变量 for循环一个可迭代对象] ? # 例子 v1 = [i+100 for i in range(10)] # [100,101,....] ? # 面试题 def num(): return [lambda x:i*x for i in range(4)] # num() -> [函数,函数,函数,函数] print([m(2) for m in num()]) # [6, 6, 6, 6] # 完整的格式 v = [i for i in 可跌代对象] v = [i for i in 可跌代对象 if 条件] # 可筛选
v = {i for i in ‘alex‘}
v = {‘k‘+str(i):i for i in range(10)}
第十三章 博客系统
第十四章 权限管理
第十五章 CRM客户关系管理软件
第十六章 restful-framework框架
第十七章 前端框架VUE
第十八章 Django+vue视频网站项目
第十九章 算法与设计模式
第二十章 web环境部署和上线流程
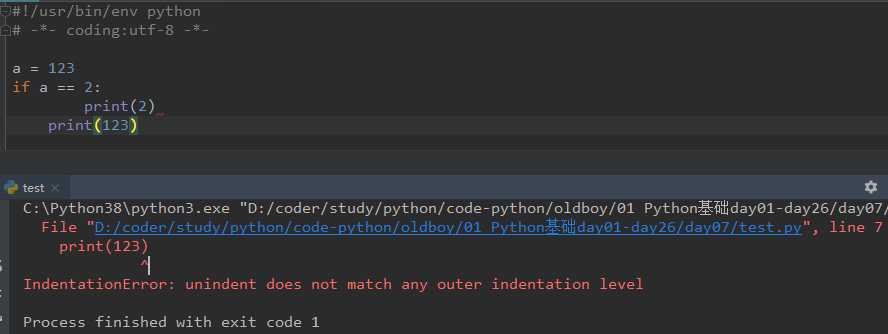
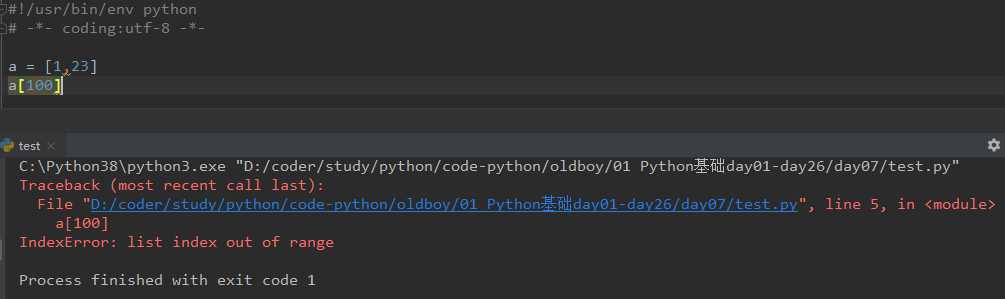
少了
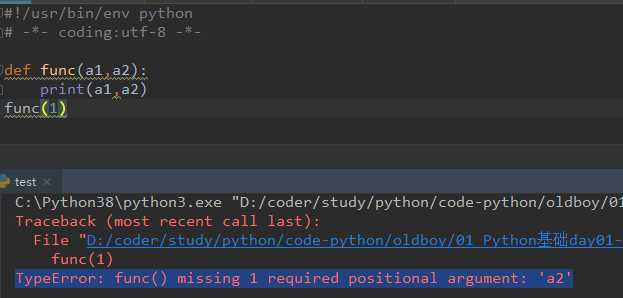
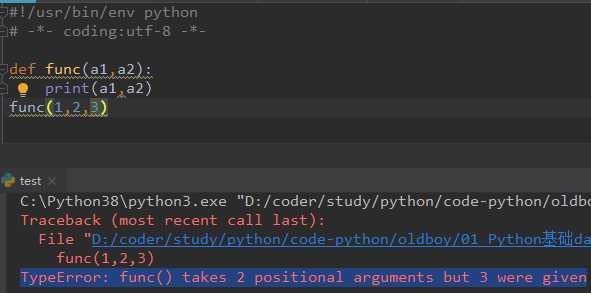
多了
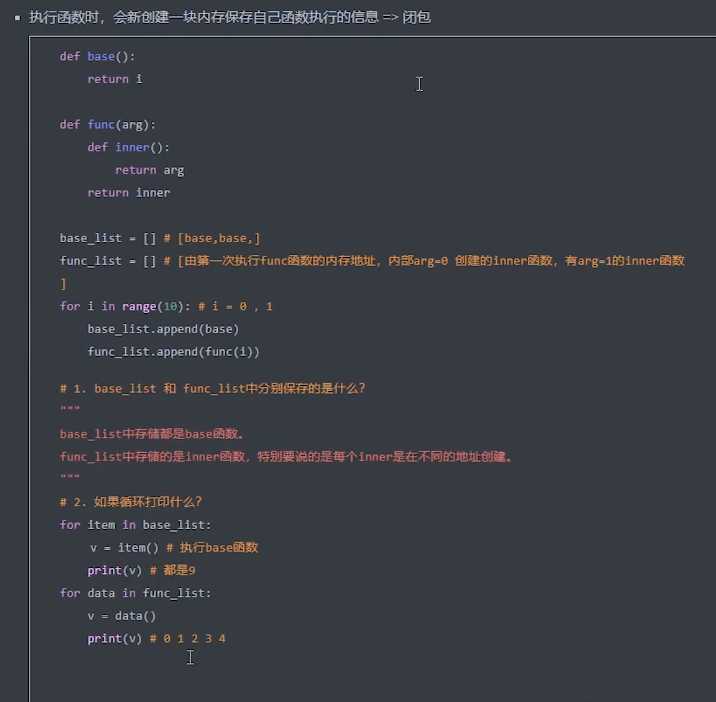
闭包
原文:https://www.cnblogs.com/nbchen/p/12148216.html
