1 import requests 2 from bs4 import BeautifulSoup 3 4 r1 = requests.get( 5 url = ‘https://www.16pic.com/sucai/7597253.html‘, 6 headers = { 7 # ‘‘:‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘, 8 ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36‘ 9 } 10 ) 11 12 soup = BeautifulSoup(r1.text,‘lxml‘) 13 #print(soup) 14 div = soup.find(name = ‘div‘,attrs={‘class‘:‘flex_grid masonry‘}) 15 #print(div) 16 17 li_list = div.find_all(name = ‘a‘,attrs={‘class‘:‘image‘}) 18 print(li_list) 19 for li in li_list: 20 img = li.find(name = ‘img‘) 21 print(img) 22 src = img.get(‘data-original‘) 23 src = ‘http:‘+src 24 print(src) 25 26 #再次发起请求,下载图片 27 file_name = src.rsplit(‘/‘,maxsplit=1)[1] # 设/后面的文字为文件名 分割完 取后面的 28 ret = requests.get(src) 29 with open(file_name,‘wb‘) as f: 30 f.write(ret.content) #.content 表示返回的是二进制 图片的内容是二进制
注意点:
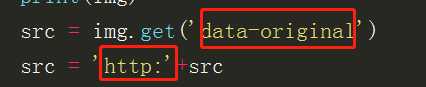

这是一种反爬虫机制,如果选取 属性 src 则获取的数据是空或者是乱码 所以要选属性为 data-original
其次是图片的链接是没有 http: 故代码中要加上 否则获取不到数据
原文:https://www.cnblogs.com/cfancy/p/12148930.html