分布式系统面临的问题
服务分布式体系结构中的应用程序有很多依赖关系,每个依赖关系在某西厄时候将遇到不可避免的失败。
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的”扇出“,如果扇出的链路上某个微服务的调用响应时间过长或不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的”雪崩效应“。
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份列表,线程和其他系统资源紧张,导致整个系统发生更多的级联故障,这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
什么是Hystrix
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可壁面的会调用失败,比如超时,异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提供分布式系统的弹性。
”断路器“本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个服务预期的,可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方法无法处理的异常,这样就可以保证了服务调用方的线程不会被长时间,不必要的占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
Hystrix可以做什么?
Hystrix的内部逻辑
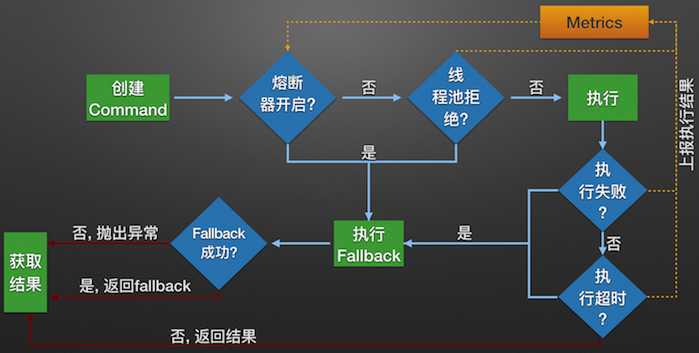
服务熔断
熔断机器是对应雪崩效应的一种微服务链路保护机制。
当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该点微服务调用响应正常恢复调用链路。在SpringCloud框架里熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况。当失败的调用达到一定的阙值,默认是5s内20次调用失败就会启动熔断机制。熔断机制的注解是@HystrixCommand。
更多参考:https://blog.csdn.net/Michaelwubo/article/details/81357349https://blog.csdn.net/Michaelwubo/article/details/81357349
原文:https://www.cnblogs.com/DejaVu-F/p/12151846.html