名称 Kubernetes 源于希腊语,意为 “舵手” 或 “飞行员”。Google 在 2014 年开源了 Kubernetes 项目,Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。
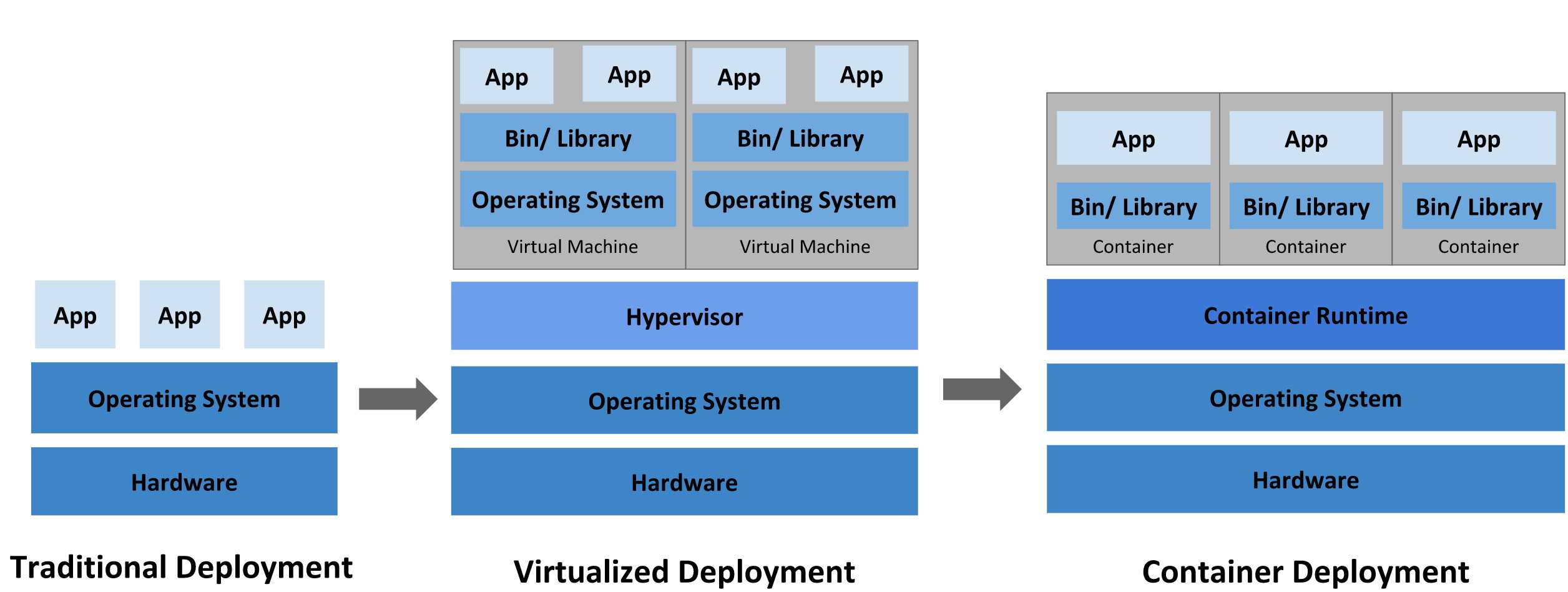
传统部署时代: 早期,组织在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况,结果可能导致其他应用程序的性能下降。一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展,并且组织维护许多物理服务器的成本很高。
虚拟化部署时代: 作为解决方案,引入了虚拟化功能,它允许您在单个物理服务器的 CPU 上运行多个虚拟机(VM)。虚拟化功能允许应用程序在 VM 之间隔离,并提供安全级别,因为一个应用程序的信息不能被另一应用程序自由地访问。
因为虚拟化可以轻松地添加或更新应用程序、降低硬件成本等等,所以虚拟化可以更好地利用物理服务器中的资源,并可以实现更好的可伸缩性。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代: 容器类似于 VM,但是它们具有轻量级的隔离属性,可以在应用程序之间共享操作系统(OS)。因此,容器被认为是轻量级的。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。由于它们与基础架构分离,因此可以跨云和 OS 分发进行移植。
Master 组件提供集群的控制平面。Master 组件对集群进行全局决策(例如,调度),并检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)
从逻辑上讲,每个控制器都是一个单独的进程,但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。kubelet 不会管理不是由 Kubernetes 创建的容器。
kube-system 命名空间。在 Kubernetes 中,节点(Node)是执行工作的机器,以前叫做 minion。根据你的集群环境,节点可以是一个虚拟机或者物理机器。每个节点都包含用于运行 pods 的必要服务,并由主控组件管理。节点上的服务包括 容器运行时、kubelet 和 kube-proxy
节点状态
地址
这些字段组合的用法取决于你的云服务商或者裸机配置。
--hostname-override 参数覆盖。conditions 字段描述了所有 Running 节点的状态。条件的示例包括
| 节点条件 | 描述 |
|---|---|
OutOfDisk |
True 表示节点的空闲空间不足以用于添加新 pods, 否则为 False |
Ready |
表示节点是健康的并已经准备好接受 pods;False 表示节点不健康而且不能接受 pods;Unknown 表示节点控制器在最近 40 秒内没有收到节点的消息 |
MemoryPressure |
True 表示节点存在内存压力 – 即节点内存用量低,否则为 False |
PIDPressure |
True 表示节点存在进程压力 – 即进程过多;否则为 False |
DiskPressure |
True 表示节点存在磁盘压力 – 即磁盘用量低,否则为 False |
NetworkUnavailable |
True 表示节点网络配置不正确;否则为 False |
节点条件使用一个 JSON 对象表示。例如,下面的响应描述了一个健康的节点
"conditions": [ { "type": "Ready", "status": "True", "reason": "KubeletReady", "message": "kubelet is posting ready status", "lastHeartbeatTime": "2019-06-05T18:38:35Z", "lastTransitionTime": "2019-06-05T11:41:27Z" } ]
如果 Ready 条件处于状态 Unknown 或者 False 的时间超过了 pod-eviction-timeout(一个传递给 kube-controller-manager 的参数),节点上的所有 Pods 都会被节点控制器计划删除。默认的删除超时时长为5 分钟。某些情况下,当节点不可访问时,apiserver 不能和其上的 kubelet 通信。删除 pods 的决定不能传达给 kubelet,直到它重新建立和 apiserver 的连接为止。与此同时,被计划删除的 pods 可能会继续在分区节点上运行。
在 1.5 版本之前的 Kubernetes 里,节点控制器会将不能访问的 pods 从 apiserver 中强制删除。但在 1.5 或更高的版本里,在节点控制器确认这些 pods 已经在集群停止运行前不会强制删除它们。你可以看到这些处于 Terminating 或者 Unknown 状态的 pods 可能在无法访问的节点上运行。为了防止 kubernetes 不能从底层基础设施中推断出一个节点是否已经永久的离开了集群,集群管理员可能需要手动删除这个节点对象。从 Kubernetes 删除节点对象将导致 apiserver 删除节点上所有运行的 Pod 对象并释放它们的名字。
节点生命周期控制器会自动创建代表条件的污点。 当调度器将 Pod 分配给节点时,调度器会考虑节点上的污点,但是 Pod 可以容忍的污点除外。
描述节点上的可用资源:CPU、内存和可以调度到节点上的 pods 的最大数量。
capacity 块中的字段指示节点拥有的资源总量。allocatable 块指示节点上可供普通 Pod 消耗的资源量。
关于节点的通用信息,例如内核版本、Kubernetes 版本(kubelet 和 kube-proxy 版本)、Docker 版本(如果使用了)和操作系统名称。这些信息由 kubelet 从节点上搜集而来。
与 pods 和 services 不同,节点并不是在 Kubernetes 内部创建的:它是被外部的云服务商创建,例如 Google Compute Engine 或者你的集群中的物理或者虚拟机。这意味着当 Kubernetes 创建一个节点时,它其实仅仅创建了一个对象来代表这个节点。创建以后,Kubernetes 将检查这个节点是否可用。
节点控制器是一个 Kubernetes master 组件,管理节点的方方面面。
节点控制器在节点的生命周期中扮演了多个角色。第一个是当节点注册时为它分配一个 CIDR block(如果打开了 CIDR 分配)。
第二个是使用云服务商提供了可用节点列表保持节点控制器内部的节点列表更新。如果在云环境下运行,任何时候当一个节点不健康时节点控制器将询问云服务节点的虚拟机是否可用。如果不可用,节点控制器会将这个节点从它的节点列表删除。
第三个是监控节点的健康情况。节点控制器负责在节点不能访问时(也即是节点控制器因为某些原因没有收到心跳,例如节点宕机)将它的 NodeStatus 的 NodeReady 状态更新为 ConditionUnknown。后续如果节点持续不可访问,节点控制器将删除节点上的所有 pods(使用优雅终止)。(默认情况下 40s 开始报告 ConditionUnknown,在那之后 5m 开始删除 pods。)节点控制器每隔 --node-monitor-period 秒检查每个节点的状态。
描述节点上的可用资源:CPU、内存和可以调度到节点上的 pods 的最大数量。
capacity 块中的字段指示节点拥有的资源总量。allocatable 块指示节点上可供普通 Pod 消耗的资源量。
可以在学习如何在节点上保留计算资源的同时阅读有关容量和可分配资源的更多信息。
关于节点的通用信息,例如内核版本、Kubernetes 版本(kubelet 和 kube-proxy 版本)、Docker 版本(如果使用了)和操作系统名称。这些信息由 kubelet 从节点上搜集而来。
与 pods 和 services 不同,节点并不是在 Kubernetes 内部创建的:它是被外部的云服务商创建,例如 Google Compute Engine 或者你的集群中的物理或者虚拟机。这意味着当 Kubernetes 创建一个节点时,它其实仅仅创建了一个对象来代表这个节点。创建以后,Kubernetes 将检查这个节点是否可用。例如,如果你尝试使用如下内容创建一个节点:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}Kubernetes 会在内部创一个 Node 对象(用以表示节点),并基于 metadata.name 字段执行健康检查,对节点进行验证。如果节点可用,意即所有必要服务都已运行,它就符合了运行一个 pod 的条件;否则它将被所有的集群动作忽略直到变为可用。
注意: Kubernetes 保留无效节点的对象,并继续检查它是否有效。必须显式删除 Node 对象以停止此过程。
当前,有 3 个组件同 Kubernetes 节点接口交互:节点控制器、kubelet 和 kubectl。
节点控制器是一个 Kubernetes master 组件,管理节点的方方面面。
节点控制器在节点的生命周期中扮演了多个角色。第一个是当节点注册时为它分配一个 CIDR block(如果打开了 CIDR 分配)。
第二个是使用云服务商提供了可用节点列表保持节点控制器内部的节点列表更新。如果在云环境下运行,任何时候当一个节点不健康时节点控制器将询问云服务节点的虚拟机是否可用。如果不可用,节点控制器会将这个节点从它的节点列表删除。
第三个是监控节点的健康情况。节点控制器负责在节点不能访问时(也即是节点控制器因为某些原因没有收到心跳,例如节点宕机)将它的 NodeStatus 的 NodeReady 状态更新为 ConditionUnknown。后续如果节点持续不可访问,节点控制器将删除节点上的所有 pods(使用优雅终止)。(默认情况下 40s 开始报告 ConditionUnknown,在那之后 5m 开始删除 pods。)节点控制器每隔 --node-monitor-period 秒检查每个节点的状态
Kubernetes 节点发送的心跳有助于确定节点的可用性。 心跳有两种形式:NodeStatus 和 Lease 对象。 每个节点在 kube-node-lease命名空间 中都有一个关联的 Lease 对象。 Lease 是一种轻量级的资源,可在集群扩展时提高节点心跳机制的性能。
kubelet 负责创建和更新 NodeStatus 和 Lease 对象。
NodeStatus。 NodeStatus 更新的默认间隔为 5 分钟(比无法访问的节点的 40 秒默认超时时间长很多)。Lease 对象。Lease 更新独立于 NodeStatus 更新而发生在 Kubernetes 1.4 中我们更新了节点控制器逻辑以更好地处理大批量节点访问 master 出问题的情况(例如 master 的网络出了问题)。从 1.4 开始,节点控制器在决定删除 pod 之前会检查集群中所有节点的状态。
大部分情况下,节点控制器把驱逐频率限制在每秒 --node-eviction-rate 个(默认为 0.1)。这表示它每 10 秒钟内之多从一个节点驱逐 Pods。
当一个可用区域中的节点变为不健康时,它的驱逐行为将发生改变。节点控制器会同时检查可用区域中不健康(NodeReady 状态为 ConditionUnknown 或 ConditionFalse)的节点的百分比。如果不健康节点的部分超过 --unhealthy-zone-threshold (默认为 0.55),驱逐速率将会减小:如果集群较小(意即小于等于 --large-cluster-size-threshold 个 节点 - 默认为 50),驱逐操作将会停止,否则驱逐速率将降为每秒 --secondary-node-eviction-rate 个(默认为 0.01)。在单个可用区域实施这些策略的原因是当一个可用区域可能从 master 分区时其它的仍然保持连接。如果你的集群没有跨越云服务商的多个可用区域,那就只有一个可用区域整个集群)。
在多个可用区域分布你的节点的一个关键原因是当整个可用区域故障时,工作负载可以转移到健康的可用区域。因此,如果一个可用区域中的所有节点都不健康时,节点控制器会以正常的速率 --node-eviction-rate 进行驱逐操作。在所有的可用区域都不健康(也即集群中没有健康节点)的极端情况下,节点控制器将假设 master 的连接出了某些问题,它将停止所有驱逐动作直到一些连接恢复。
从 Kubernetes 1.6 开始,NodeController 还负责驱逐运行在拥有 NoExecute 污点的节点上的 pods,如果这些 pods 没有容忍这些污点。此外,作为一个默认禁用的 alpha 特性,NodeController 还负责根据节点故障(例如节点不可访问或没有 ready)添加污点。请查看这个文档了解关于 NoExecute 污点和这个 alpha 特性。
从版本 1.8 开始,可以使节点控制器负责创建代表节点条件的污点。
当 kubelet 标志 --register-node 为 true (默认)时,它会尝试向 API 服务注册自己。这是首选模式,被绝大多数发行版选用。
集群管理员可以创建及修改节点对象。
如果管理员希望手动创建节点对象,请设置 kubelet 标记 --register-node=false。
管理员可以修改节点资源(忽略 --register-node 设置)。修改包括在节点上设置 labels 及标记它为不可调度。
节点上的 labels 可以和 pods 的节点 selectors 一起使用来控制调度,例如限制一个 pod 只能在一个符合要求的节点子集上运行。
节点的容量(cpu 数量和内存容量)是节点对象的一部分。通常情况下,在创建节点对象时,它们会注册自己并报告自己的容量。如果你正在执行手动节点管理,那么你需要在添加节点时手动设置节点容量。
Kubernetes 调度器保证一个节点上有足够的资源供其上的所有 pods 使用。它会检查节点上所有容器要求的总和不会超过节点的容量。这包括由 kubelet 启动的所有容器,但不包括由 container runtime 直接启动的容器,也不包括在容器外部运行的任何进程。
原文:https://www.cnblogs.com/zyxnhr/p/12180537.html