1.在hello-koa这个目录下创建一个package.json,这个文件描述了我们的hello-koa工程会用到哪些包。完整的文件内容如下:
{ "name": "hello-koa2", "version": "1.0.0", "description": "Hello Koa 2 example with async", "main": "app.js", "scripts": { "start": "node app.js" }, "keywords": [ "koa", "async" ], "author": "Michael Liao", "license": "Apache-2.0", "repository": { "type": "git", "url": "https://github.com/michaelliao/learn-javascript.git" }, "dependencies": { "koa": "2.0.0" } }
其中,dependencies描述了我们的工程依赖的包以及版本号。其他字段均用来描述项目信息,可任意填写。
C:\...\hello-koa> npm install
2.创建koa2工程
// 导入koa,和koa 1.x不同,在koa2中,我们导入的是一个class,因此用大写的Koa表示: const Koa = require(‘koa‘); // 创建一个Koa对象表示web app本身: const app = new Koa(); // 对于任何请求,app将调用该异步函数处理请求: app.use(async (ctx, next) => { await next(); ctx.response.type = ‘text/html‘; ctx.response.body = ‘<h1>Hello, koa2!</h1>‘; }); // 在端口3000监听: app.listen(3000); console.log(‘app started at port 3000...‘);
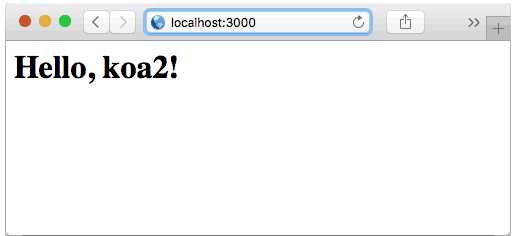
还可以直接用命令node app.js在命令行启动程序,或者用npm start启动。npm start命令会让npm执行定义在package.json文件中的start对应命令:
"scripts": { "start": "node app.js" }
让我们再仔细看看koa的执行逻辑。核心代码是:
app.use(async (ctx, next) => { await next(); ctx.response.type = ‘text/html‘; ctx.response.body = ‘<h1>Hello, koa2!</h1>‘; });
每收到一个http请求,koa就会调用通过app.use()注册的async函数,并传入ctx和next参数。
我们可以对ctx操作,并设置返回内容。但是为什么要调用await next()?
原因是koa把很多async函数组成一个处理链,每个async函数都可以做一些自己的事情,
然后用await next()来调用下一个async函数。我们把每个async函数称为middleware,这些middleware可以组合起来,完成很多有用的功能。
例如,可以用以下3个middleware组成处理链,依次打印日志,记录处理时间,输出HTML:
// 导入koa,和koa 1.x不同,在koa2中,我们导入的是一个class,因此用大写的Koa表示: const Koa = require(‘koa‘); // 创建一个Koa对象表示web app本身: const app = new Koa(); app.use(async (ctx, next) => { console.log(`${ctx.request.method} ${ctx.request.url}`); // 打印URL await next(); // 调用下一个middleware }); app.use(async (ctx, next) => { const start = new Date().getTime(); // 当前时间 await next(); // 调用下一个middleware const ms = new Date().getTime() - start; // 耗费时间 console.log(`Time: ${ms}ms`); // 打印耗费时间 }); app.use(async (ctx, next) => { console.log(‘我开始了‘) await next(); // 当下面没有use 后将不执行 ctx.response.type = ‘text/html‘; ctx.response.body = ‘<h1>Hello, koa2!</h1>‘; console.log(‘我结束了‘) }); // 在端口3000监听: app.listen(3000); console.log(‘app started at port 3000...‘);
middleware的顺序很重要,也就是调用app.use()的顺序决定了middleware的顺序。
此外,如果一个middleware没有调用await next(),会怎么办?答案是后续的middleware将不再执行了。
这种情况也很常见,例如,一个检测用户权限的middleware可以决定是否继续处理请求,还是直接返回403错误:
app.use(async (ctx, next) => { if (await checkUserPermission(ctx)) { await next(); } else { ctx.response.status = 403; } });
理解了middleware,我们就已经会用koa了!
最后注意ctx对象有一些简写的方法,例如ctx.url相当于ctx.request.url,ctx.type相当于ctx.response.type。
正常情况下,我们应该对不同的URL调用不同的处理函数,这样才能返回不同的结果。例如像这样写:
// 导入koa,和koa 1.x不同,在koa2中,我们导入的是一个class,因此用大写的Koa表示: const Koa = require(‘koa‘); // 创建一个Koa对象表示web app本身: const app = new Koa(); app.use(async (ctx, next) => { //ctx.request.path 判断访问路径 if (ctx.request.path === ‘/‘) { ctx.response.body = ‘index page‘; //如果就有 就执行下一个use } else { await next(); } }); app.use(async (ctx, next) => { if (ctx.request.path === ‘/test‘) { ctx.response.body = ‘TEST page‘; } else { await next(); } }); app.use(async (ctx, next) => { if (ctx.request.path === ‘/error‘) { ctx.response.body = ‘ERROR page‘; } else { await next(); } }); // 在端口3000监听: app.listen(3000); console.log(‘app started at port 3000...‘);
这么写是可以运行的,但是好像有点蠢。
应该有一个能集中处理URL的middleware,它根据不同的URL调用不同的处理函数,这样,我们才能专心为每个URL编写处理函数。
为了处理URL,我们需要引入koa-router这个middleware,让它负责处理URL映射。
先在package.json中添加依赖项:
{ "name": "hello-koa2", "version": "1.0.0", "description": "Hello Koa 2 example with async", "main": "app.js", "scripts": { "start": "node app.js" }, "keywords": [ "koa", "async" ], "author": "Michael Liao", "license": "Apache-2.0", "repository": { "type": "git", "url": "https://github.com/michaelliao/learn-javascript.git" }, "dependencies": { "koa": "2.0.0", "koa-router": "7.0.0" } }
然后用npm install安装。
接下来,我们修改app.js,使用koa-router来处理URL:
// 导入koa,和koa 1.x不同,在koa2中,我们导入的是一个class,因此用大写的Koa表示: const Koa = require(‘koa‘); // 注意require(‘koa-router‘)返回的是函数:koa-router的语句最后的()是函数调用: const router = require(‘koa-router‘)(); // 创建一个Koa对象表示web app本身: const app = new Koa(); //log request URL: app.use(async(ctx,next)=> { console.log(`Process ${ctx.request.method} ${ctx.request.url}.....`) await next(); }) //add url-route; 添加访问路径 router.get(`/hello/:name`,async(ctx,next)=> { var name = ctx.params.name ctx.response.body = `<h1>Hello,${name}</h1>` }) //add url-route;添加访问路径 router.get(‘/‘, async (ctx, next) => { ctx.response.body = ‘<h1>Index</h1>‘; }); // add router middlware app.use(router.routes()); // 在端口3000监听: app.listen(3000); console.log(‘app started at port 3000...‘);
注意导入koa-router的语句最后的()是函数调用:
const router = require(‘koa-router‘)();
相当于:
const fn_router = require(‘koa-router‘);
const router = fn_router();
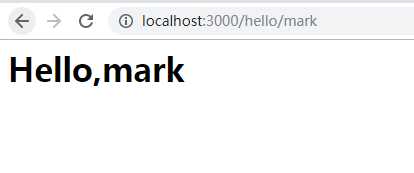
然后,我们使用router.get(‘/path‘, async fn)来注册一个GET请求。可以在请求路径中使用带变量的/hello/:name,变量可以通过ctx.params.name访问。
再运行app.js,我们就可以测试不同的URL:
输入首页:http://localhost:3000/
用router.get(‘/path‘, async fn)处理的是get请求。如果要处理post请求,可以用router.post(‘/path‘, async fn)。
用post请求处理URL时,我们会遇到一个问题:post请求通常会发送一个表单,或者JSON,它作为request的body发送,但无论是Node.js提供的原始request对象,还是koa提供的request对象,都不提供解析request的body的功能!
所以,我们又需要引入另一个middleware来解析原始request请求,然后,把解析后的参数,绑定到ctx.request.body中。
koa-bodyparser就是用来干这个活的。
1. 在package.json中添加依赖项:
"koa-bodyparser": "3.2.0"
2.引入koa-bodyparser:
const bodyParser = require(‘koa-bodyparser‘);
在合适的位置加上:
app.use(bodyParser());
由于middleware的顺序很重要,这个koa-bodyparser必须在router之前被注册到app对象上。
现在我们就可以处理post请求了。写一个简单的登录表单:
// 导入koa,和koa 1.x不同,在koa2中,我们导入的是一个class,因此用大写的Koa表示: const Koa = require(‘koa‘); // 注意require(‘koa-router‘)返回的是函数:koa-router的语句最后的()是函数调用: const router = require(‘koa-router‘)(); // 创建提供解析request的body的功能 const bodyParser = require(‘koa-bodyparser‘); // 创建一个Koa对象表示web app本身: const app = new Koa(); //log request URL: app.use(async(ctx,next)=> { console.log(`Process ${ctx.request.method} ${ctx.request.url}.....`) await next(); }) //get 请求返回一个body html文本 router.get(‘/‘, async (ctx, next) => { // 响应html文本 ctx.response.body = `<h1>Index</h1> <form action="/signin" method="post"> <p>Name: <input name="name" value="koa"></p> <p>Password: <input name="password" type="password"></p> <p><input type="submit" value="Submit"></p> </form>`; }); //处理用户提交过来的 post请求 router.post(‘/signin‘, async (ctx, next) => { // 获取用户提交上来的值 var name = ctx.request.body.name || ‘‘, password = ctx.request.body.password || ‘‘; console.log(`signin with name: ${name}, password: ${password}`); // 对用户提交上来的值进行判断 if (name === ‘koa‘ && password === ‘12345‘) { //如果成功 返回登录成功 ctx.response.body = `<h1>Welcome, ${name}!</h1>`; } else { // 如果登录失败 返回登录失败,然后尝试 再次登录 ctx.response.body = `<h1>Login failed!</h1> <p><a href="/">Try again</a></p>`; } }); // add middlware 这个要放前面 app.use(bodyParser()); // add router middlware app.use(router.routes()); // 在端口3000监听: app.listen(3000); console.log(‘app started at port 3000...‘);
注意到我们用var name = ctx.request.body.name || ‘‘拿到表单的name字段,如果该字段不存在,默认值设置为‘‘。
类似的,put、delete、head请求也可以由router处理。
现在,我们已经可以处理不同的URL了,但是看看app.js,总觉得还是有点不对劲。
所有的URL处理函数都放到app.js里显得很乱,而且,每加一个URL,就需要修改app.js。随着URL越来越多,app.js就会越来越长。
如果能把URL处理函数集中到某个js文件,或者某几个js文件中就好了,然后让app.js自动导入所有处理URL的函数。这样,代码一分离,逻辑就显得清楚了。最好是这样:
url2-koa/ | +- .vscode/ | | | +- launch.json <-- VSCode 配置文件 | +- controllers/ | | | +- login.js <-- 处理login相关URL | | | +- users.js <-- 处理用户管理相关URL | +- app.js <-- 使用koa的js | +- package.json <-- 项目描述文件 | +- node_modules/ <-- npm安装的所有依赖包
于是我们把url-koa复制一份,重命名为url2-koa,准备重构这个项目。
我们先在controllers目录下编写index.js:
原文:https://www.cnblogs.com/Rivend/p/12188956.html