Promethues配置文件中的时间相关参数
1. scrape_interval:Promethues抓取数据的间隔,默认为1分钟
2. evaluation_interval:评估间隔,Promethues跑一遍所有的定义好的alerting rules,并更新alerting的状态
3. alert status:
inactive: 未达到告警的条件
pending: 达到了告警的条件,但是持续时间小于设定的阈值时间(取决于有没有for语句,如果没有将直接从inactive跳到firing状态)
firing: 达到了告警的条件,且持续时间大于设定的时间阈值
4. alert sending:
group_wait: 等待该时间,目的是将该时间段内所有的属于同一个组的alert打包一起发送告警通知
group_interval:下一次评估过程中,同一个组的alert生效,则会等待该时长发送告警通知,此时不会等待group_wait设置的时间
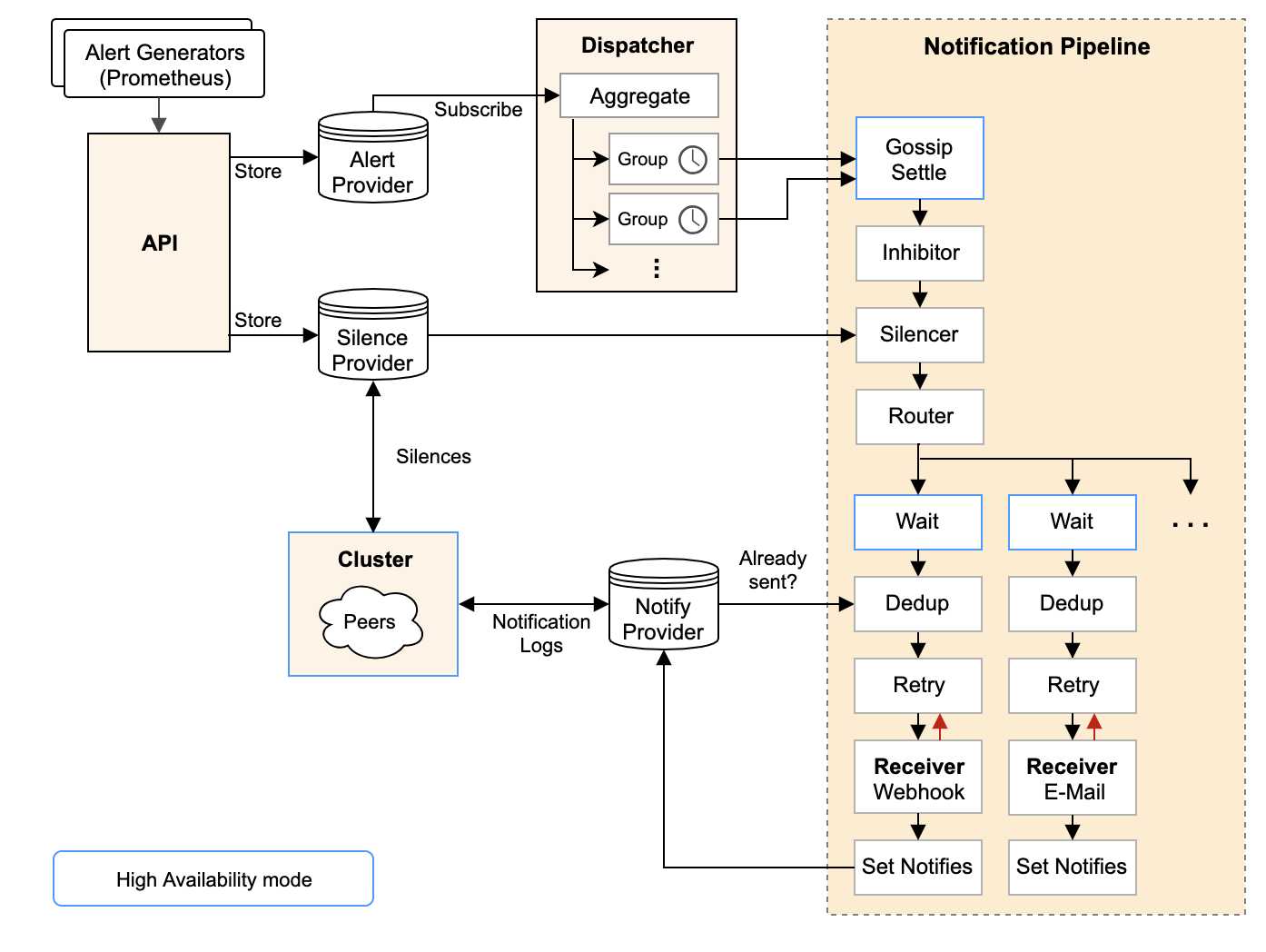
Alertmanager内部架构图
- 从左上开始,Prometheus 发送的警报到 Alertmanager;
- 警报会被存储到 AlertProvider 中,Alertmanager 的内置实现就是包了一个 map,也就是存放在本机内存中,这里可以很容易地扩展其它 Provider;
- Dispatcher 是一个单独的 goroutine,它会不断到 AlertProvider 拉新的警报,并且根据 YAML 配置的 Routing Tree 将警报路由到一个分组中;
- 分组会定时进行 flush (间隔为配置参数中的 group_interval), flush 后这组警报会走一个 Notification Pipeline 链式处理;
- Notification Pipeline 为这组警报确定发送目标,并执行抑制逻辑,静默逻辑,去重逻辑,发送与重试逻辑,实现警报的最终投递;
参考资料
Prometheus告警发送时间详解
原文:https://www.cnblogs.com/battlescars/p/prometheus_alertmanager.html