今天学了爬虫,实现了一些爬虫案例,如从猫眼电影网址中爬取Top100的电影数据,最受期待的电影等。
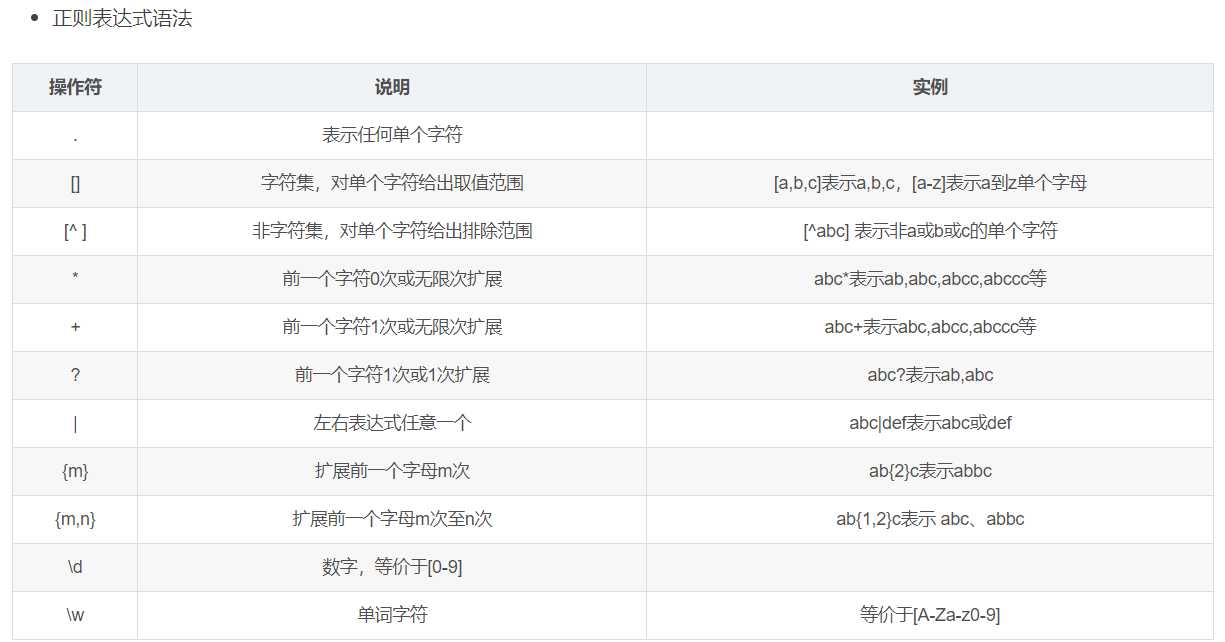
爬虫三部曲:
第一步:获取网页数据(响应)
1 def reptile(url): 2 try: 3 response = requests.get(url,headers=headers) 4 if response.status_code == 200: 5 return response.text 6 else: 7 print("获取网页失败") 8 except Exception as e: 9 print(e)
第二步:去响应数据的中所需的数据
1 def get_info(page): 2 items = re.findall(‘<dd>.*?<i class="board-index board-index-.*?">(.*?)</i>.*?<p class="name"><a.*?>(.*?)</a>.*?<p class="star">主演:(.*?)</p>‘+ 3 ‘<p class="releasetime">上映时间:(.*?)<.*?</dd>‘,page,re.S) 4 # print(items) 5 print(len(items)) 6 for item in items: 7 data = {} 8 data["电影排名"] = item[0] 9 # print(item[0]) 10 data["电影名称"] = item[1] 11 data["主演"] = item[2] 12 data["上映时间"] = item[3] 13 # data["本月想看新增人数"] = item[4] 14 yield data
第三步:生成xls文件
1 f = xlwt.Workbook(encoding=‘utf-8‘) 2 sheet01 = f.add_sheet(u‘sheet1‘, cell_overwrite_ok=True) 3 sheet01.write(0, 0, ‘电影排名‘) # 第一行第一列 4 sheet01.write(0, 1, ‘电影名称‘) 5 sheet01.write(0, 2, ‘主演‘) 6 sheet01.write(0, 3, ‘上映时间‘) 7 # sheet01.write(0, 4, ‘score‘) 8 # 写内容 9 for i in range(len(Data)): 10 sheet01.write(i + 1, 0, Data[i][‘电影排名‘]) 11 sheet01.write(i + 1, 1, Data[i][‘电影名称‘]) 12 sheet01.write(i + 1, 2, Data[i][‘主演‘]) 13 sheet01.write(i + 1, 3, Data[i][‘上映时间‘]) 14 # sheet01.write(i + 1, 4, Data[i][‘score‘]) 15 print(‘p‘, end=‘‘) 16 f.save(‘D:\\爬虫数据\\猫眼电影最期待.xls‘)
学习博客:https://blog.csdn.net/weixin_41779359/article/details/86374812
原文:https://www.cnblogs.com/goubb/p/12203496.html