pip install scrapy
scrapy startproject 项目名称
执行完创建项目的命令后,得到的提示为:
You can start your first spider with:
cd Spider
scrapy genspider example example.com
然后按照提示,依次来执行这两行命令。
这里,cd命令是切换到当前爬虫的工作目录。
genspider 则是生成一个爬虫,该爬虫的名字为example,要爬取的网站为example.com。
当然,example和example.com 可以根据实际情况进行修改。
执行完生成爬虫的命令后,我们可以看到如下提示:
Created spider ‘example‘ using template ‘basic‘ in module:
Spider.spiders.example
从提示中可以看到,这里使用了‘basic’模板来生成爬虫,当然可以指定别的模板,这个内容后面会提到
最终,我们得到的这整个项目的框架为:

其中,Spider为我们使用startproject命令指定的项目名称,而example.py则为我们的爬虫文件。
至于items.py,middlewares.py,pipelines.py,settings.py,这些文件的作用请参考菜鸟教程
简单来说,items.py: 项目的目标文件。pipelines.py: 项目的管道文件。settings.py: 项目的设置文件。middlewares.py:项目的中间件文件。
不同的模板生成的文件是不一样的,这里的example.py文件对应于‘basic’模板。
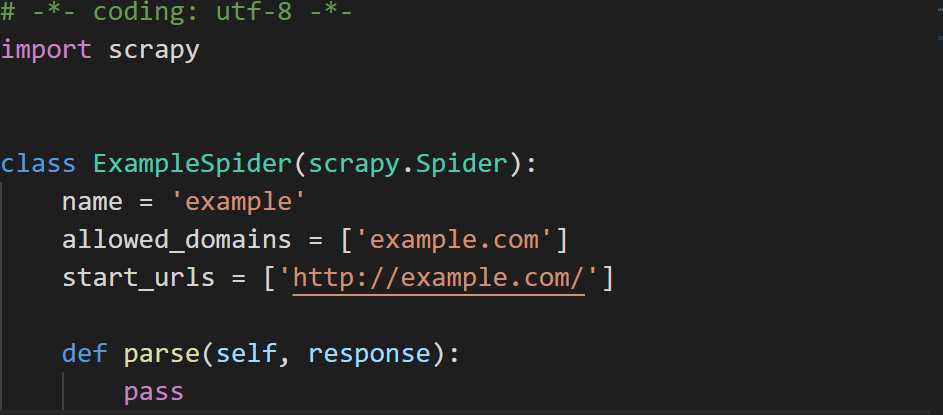
可以看到,该文件定义了一个爬虫类ExampleSpider,在该类中,name为爬虫的名字,allowed_domains指定要爬取的网址,start_url指定从哪个url开始爬取。
而parse函数则是对请求start_url返回的response对象进行分析,该函数需要用户自定义。
这里,假设我们已经对新浪新闻网站进行了分析,并决定爬取新浪新闻里的滚动新闻里的国内新闻版块。
为了不与之前的example搞混,我们根据上述的流程重新创建一个用于爬取新浪新闻的爬虫。
具体实现的功能是爬取共爬取10页的所有新闻链接,然后载根据得到的新闻链接爬取对应的新闻,并将新闻的标题,内容和发布时间等信息保存下来。
因此,在我们的爬虫文件中,设置的参数如下:
name = ‘sina‘
allowed_domains = [‘feed.mix.sina.com.cn‘,‘sina.com.cn‘]
start_urls = ["https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2510&k=&num=50&page={}".format(page) for page in range(10)]
然后,决定我们需要爬取的内容,比如我们需要获得每篇文章的标题,关键字,内容,发布的时间,媒体,标签这些内容,因而需要对items.py文件进行设置,设置内容如下:
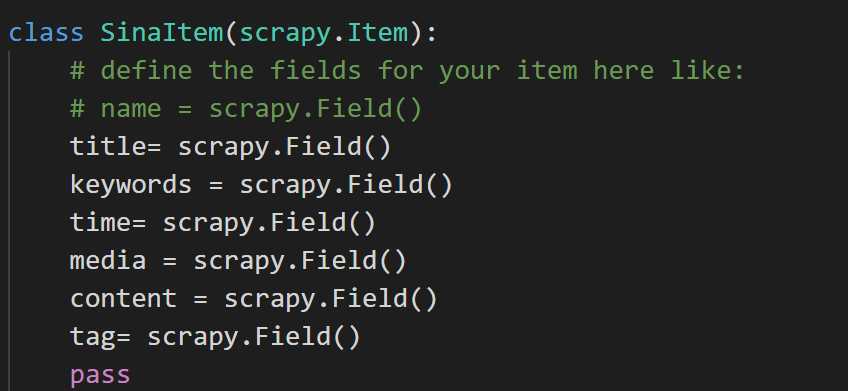
然后,回到我们的爬虫文件,将items.py的内容导入到爬虫文件中

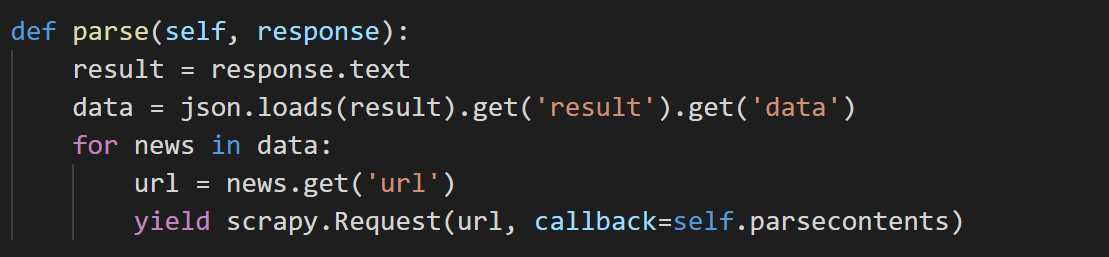
parse函数的实现为:获得请求start_url的返回的response内容,并对其提取url,然后将其抛给parsecontent函数,由parsecontent函数来处理请求该url后获得的response的内容。
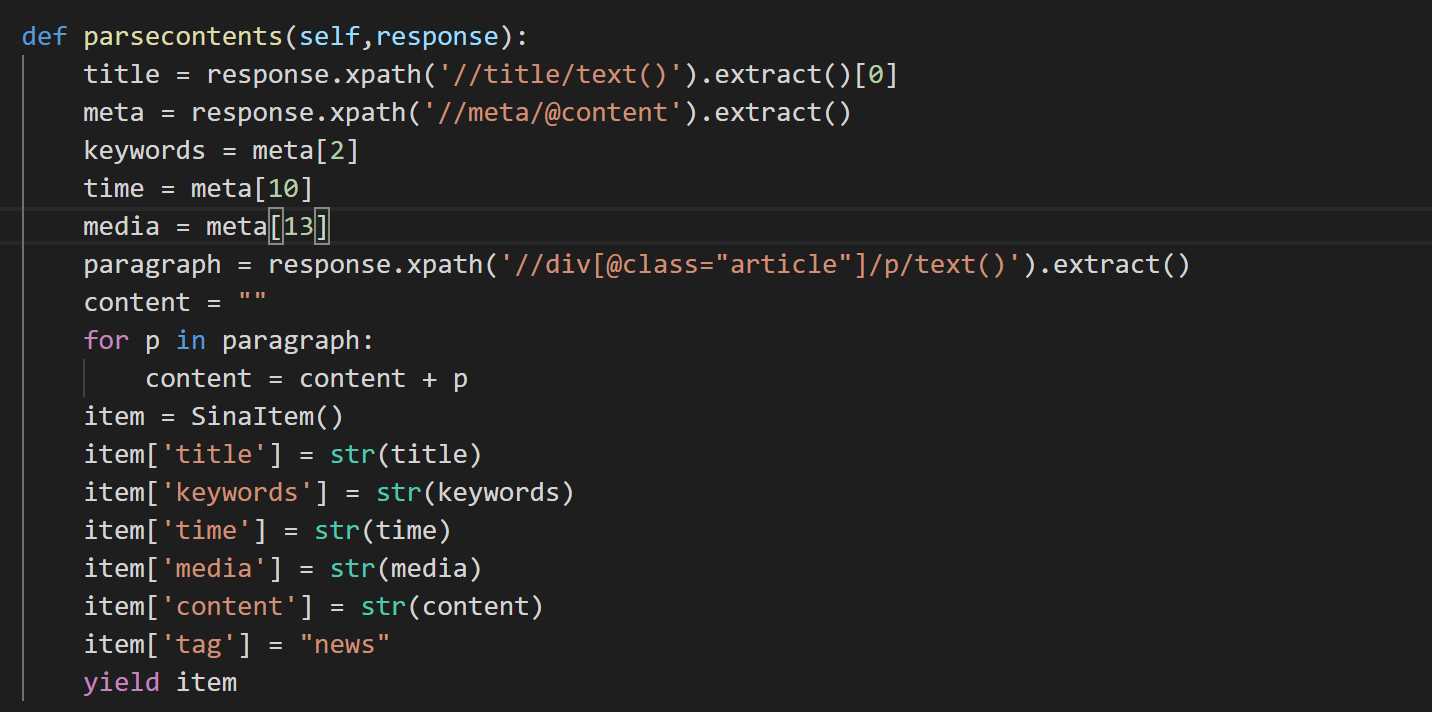
parseconten函数的内容为根据请求url后返回的response内容进行提取,使用xpath对网页格式的内容提取非常方便,当然也可以使用其他方法,比如正则表达式或者beautifulsoup等工具。
在工作目录下输入命令以启动爬虫
scrapy crawl 爬虫名称
这里输入的命令为:scrapy crawl sina
爬虫爬取的内容保存实现在pipelines.py文件,在编写爬虫时,我们最后抛出了item,这个item应该被传送得到了pipelines.py中,
在pipelines.py文件中,我们可以实现将获取的item写入文件或者保存得到MongoDB数据库中。
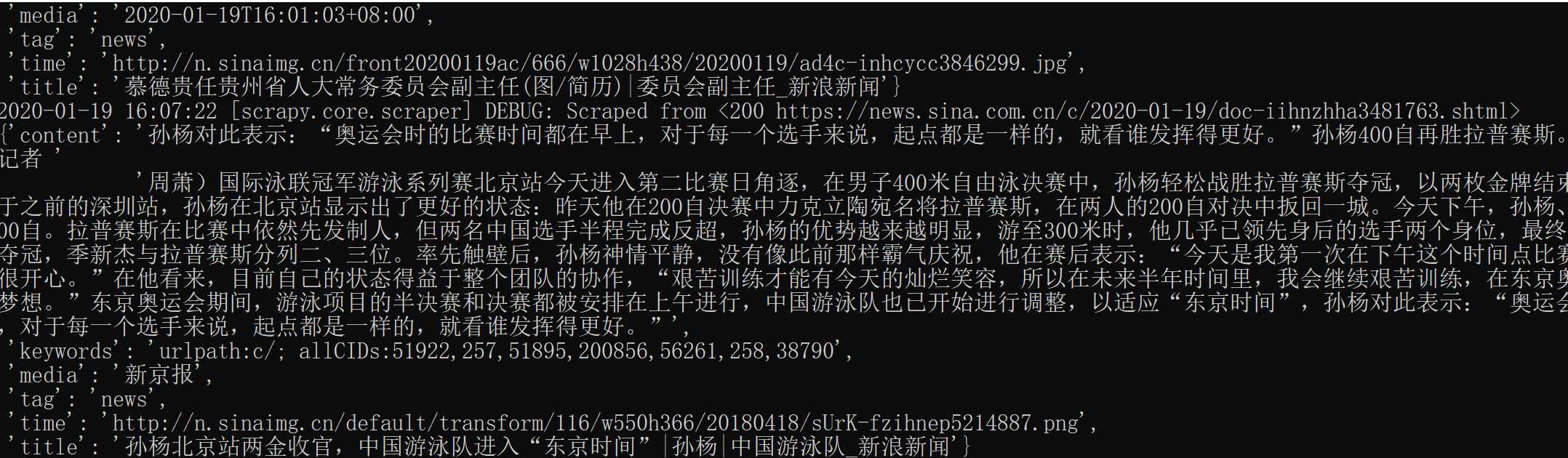
爬取得到的内容为:
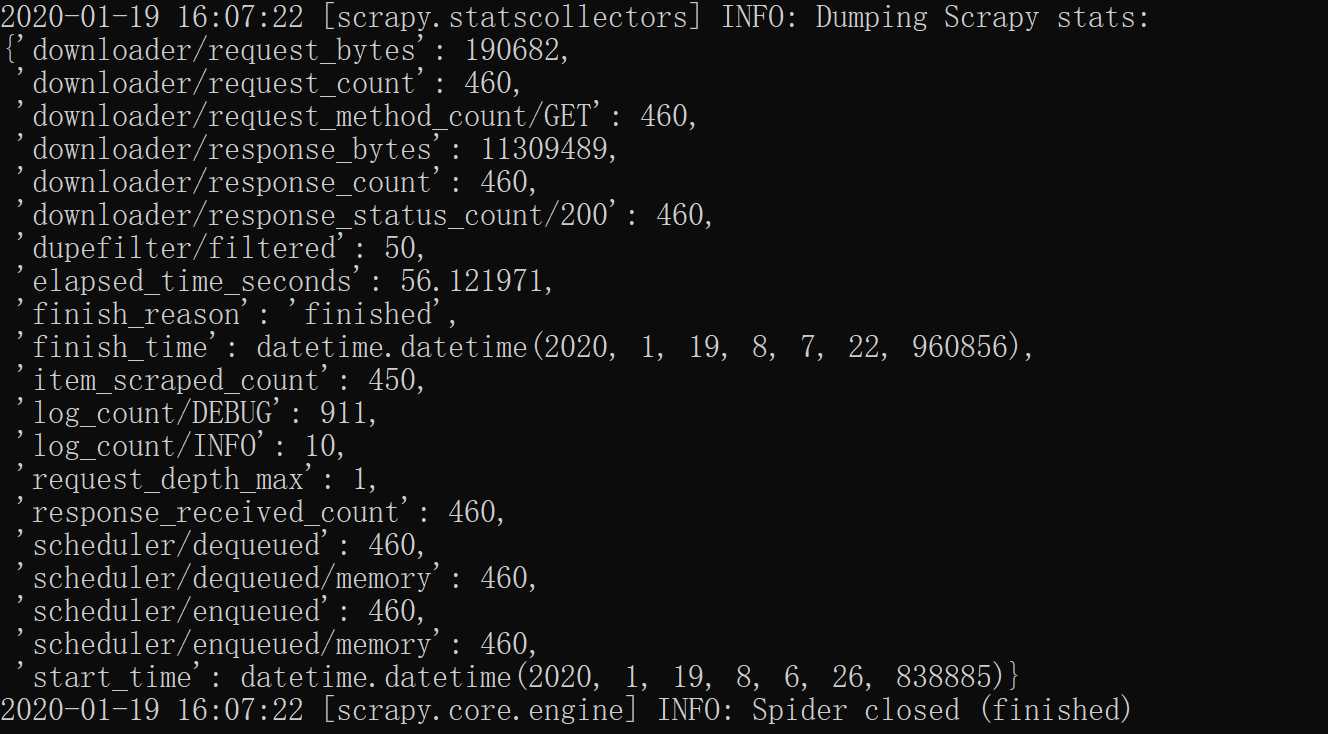
爬取结束后,scrapy会给出统计信息
原文:https://www.cnblogs.com/ASE265/p/12214364.html