微服务鉴权限流剖析
微服务
- 把复杂的大应用,解耦拆分成几个小的应用。
- 有利于团队组织架构的拆分,毕竟团队越大协作的难度越大;
- 每个应用都可以独立运维,独立扩容,独立上线,各个应用之间互不影响。
- 有利就有弊:
- 大应用拆分成微服务之后,服务之间的调用关系变得更复杂,平台的整体复杂熵升高,出错的概率、debug 问题的难度都高了好几个数量级。
- 为了解决这些问题,服务治理便成了微服务的一个技术重点。
服务治理
- 简单点讲,就是管理微服务,保证平台整体正常、平稳地运行。
- 涉及的内容:鉴权、限流、降级、熔断、监控告警等等。
- 服务治理功能的实现,底层依赖大量的数据结构和算法。这里拿其中的鉴权和限流这两个功能,剖析一下实现过程中用到的数据结构和算法。
鉴权
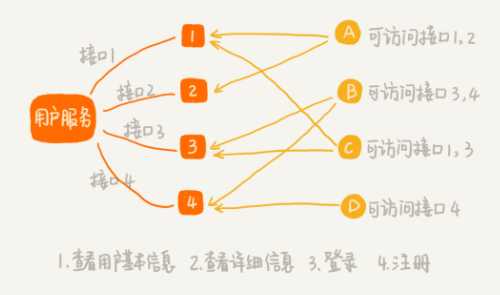
- 有一个微服务叫用户服务(User Service)。它提供很多用户相关的接口,比如获取用户信息、注册、登录等,给公司内部的其他应用使用。
- 并不是公司内部所有应用,都可以访问这个用户服务,也并不是每个有访问权限的应用,都可以访问用户服务的所有接口。
-
需要实现接口鉴权功能
- 如何实现快速鉴权?
- 用什么数据结构来存储规则?
- 用户请求 URL 在规则中快速匹配,用什么的算法?
- 不同的规则和匹配模式,对应的数据结构和匹配算法也是不一样。
- 如何实现精确匹配规则?
- 简单规则

- 不同的应用对应不同的规则集合,可以采用散列表来存储这种对应关系。
- 每个应用对应的规则集合,该如何存储和匹配?
- 可以将每个应用对应的权限规则,存储在一个字符串数组中。
- 当用户请求到来时,拿用户的请求 URL,在这个字符串数组中逐一匹配,匹配的算法就是我们之前学过的字符串匹配算法(比如 KMP、BM、BF 等)。
- 规则不会经常变动,所以,为了加快匹配速度,可以按照字符串的大小给规则排序,把它组织成有序数组这种数据结构。
- 当要查找某个 URL 能否匹配其中某条规则的时候,可以采用二分查找算法,在有序数组中进行匹配。
- 如何实现前缀匹配规则?
- 稍微复杂的匹配模式:只要某条规则可以匹配请求 URL 的前缀,这条规则就能够跟这个请求 URL 匹配。

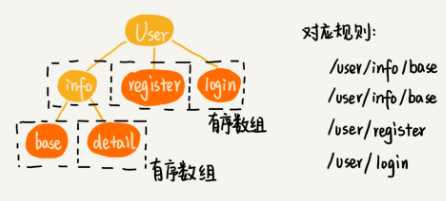
- Trie 树非常适合用来做前缀匹配
- 可以将每个用户的规则集合,组织成 Trie 树这种数据结构。
- Trie 树中的每个节点不是存储单个字符,而是存储接口被“/”分割之后的子目录(比如“/user/name”被分割为“user”“name”两个子目录)。
- 同样的,规则不会经常变动,所以,在 Trie 树中,可以把每个节点的子节点们,组织成有序数组这种数据结构。
- 当在匹配的过程中,可以利用二分查找算法,决定从一个节点应该跳到哪一个子节点。
-
如何实现模糊匹配规则?
限流
- 对接口调用的频率进行限制。比如每秒钟不能超过 100 次调用,超过之后,就拒绝服务。
- 在很多场景中,发挥着重要的作用。比如在秒杀、大促、双 11、618 等场景中,限流已经成为了保证系统平稳运行的一种标配的技术解决方案。
- 按照不同的限流粒度分类:
- 每个接口限制不同的访问频率
- 给所有接口限制总的访问频率
- 限制某个应用对某个接口的访问频率
- 如何实现精准限流?
- 固定时间窗口限流算法:
- 选定一个时间起点,之后每当有接口请求到来,将计数器加一。
- 如果在当前时间窗口内,根据限流规则(比如每秒钟最大允许 100 次访问请求),出现累加访问次数超过限流值的情况时,我们就拒绝后续的访问请求。
- 当进入下一个时间窗口之后,计数器就清零重新计数。
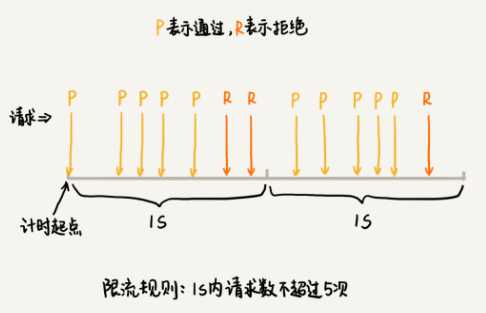
- 缺点:限流策略过于粗略,无法应对两个时间窗口临界时间内的突发流量:
- 第一个 1s 时间窗口内,100 次接口请求都集中在最后 10ms 内。
- 第二个 1s 的时间窗口内,100 次接口请求都集中在最开始的 10ms 内。
- 虽然两个时间窗口内流量都符合限流要求(≤100 个请求),但在两个时间窗口临界的 20ms 内,会集中有 200 次接口请求。
- 固定时间窗口限流算法并不能对这种情况做限制,所以,集中在这 20ms 内的 200 次请求就有可能压垮系统。
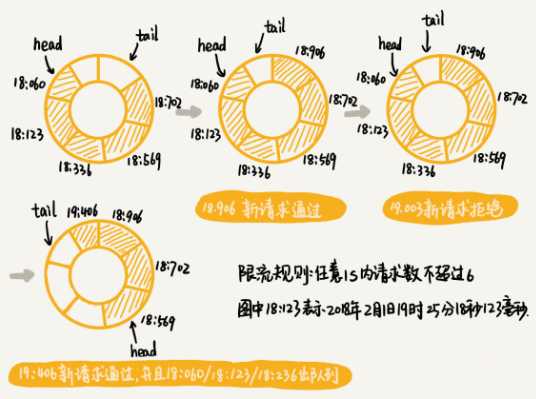
- 滑动时间窗口限流算法
数据结构与算法简记--剖析微服务接口鉴权限流背后的数据结构和算法
原文:https://www.cnblogs.com/wod-Y/p/12219106.html