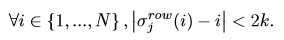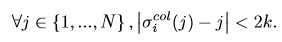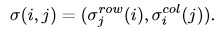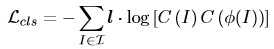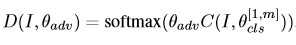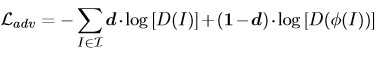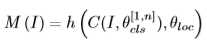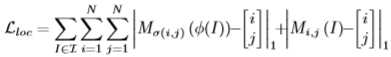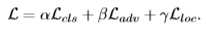Destruction and Construction Learning for Fine-grained Image Recognition
Summary
Method(s)
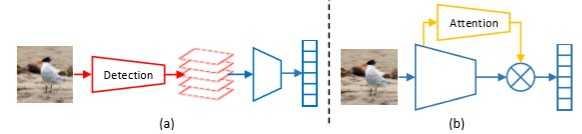
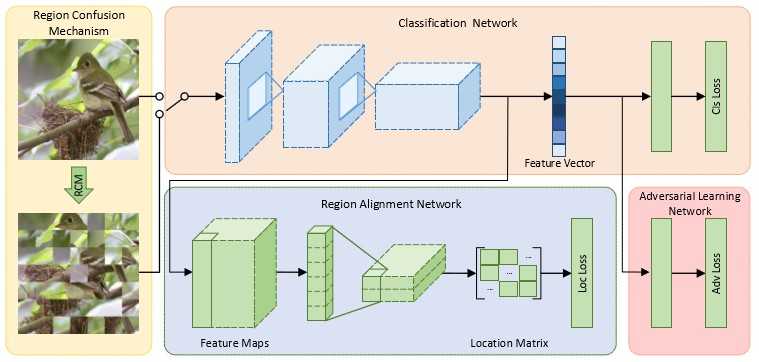
- DCL首先对输入图像进行仔细破坏,是有区别的局部细节移动,然后重构局部区域间的语义相关
- 破坏:使用RCM(Region Confusion Mechanism)区域混淆机制,混淆全局结构,分割为局部小块,随机打乱
- 分割为局部小块:细粒度类别通常共享相同的全局结构或形状,但仅在局部细节上不同。丢弃全局结构,保留局部细节,可以迫使网络集中于有区别的局部区域进行识别
- 随机打乱:对图像中的局部区域进行变换,那么对于细粒度识别来说不重要的不相关区域将被忽略,网络将被迫根据有区别的局部细节对图像进行分类
- !RCM的副作用:可能引入噪声
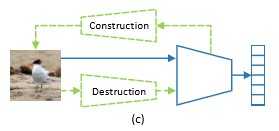
- 使用使用了一种对抗性损失来区分原始图像和破坏图像,从而最小化噪声模式的影响
- 构造:引入与RCM相反的区域对齐网络(Region Alignment Network)来恢复原始区域的排列,通过这个过程需要理解每个区域的语义对不同局部区域之间的相关关系进行建模,从而恢复区域原始布局
- 具体由四部分组成:
Evaluation
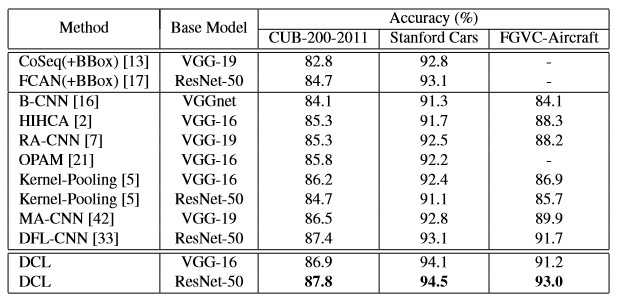
- 在多个FGVC数据集上进行实验:
- 将输入的图像大小调整为512 512的固定大小,并随机裁剪为448 448。随机旋转和随机水平翻转用于数据增强
- 最终测试:在测试时,RCM被禁用,用于对抗损失和区域构建的网络结构被删除。将输入的图像进行中心裁剪,然后将其输入到主干分类网络中进行最终的预测。
- 对所有实验设置α = β = 1
- 非刚性物体识别:CUB-200-2011 设置γ= 1。不同区域之间的相关性对于加深对物体的理解非常重要
- 刚性物体识别任务: 斯坦福汽车和FGVC飞机 设置γ= 0.01 物体的部分是有判别性和互补性的
- 对于像CUB-200-2011这样的非刚性物体识别任务,不同区域之间的相关性对于加深对物体的理解非常重要。对象和部分位置可能发挥重要作用的,突出刚性物体识别的破坏学习(DL)在学习有判别性区域的细节有重要作用
- 对于FGVC飞机,设置N=2,保留飞机的结构信息,其余设置为7(随着N的增大,性能先增大后减小)
Conclusion
DCL
原文:https://www.cnblogs.com/mercuialC/p/12220759.html