Cross-X Learning for Fine-Grained Visual Categorization
Summary
- 本文提出了一种利用不同图像之间以及不同网络层之间的关系进行鲁棒的多尺度特征学习的框架————Cross-X
易于训练,易于扩展到大型数据集上
Research Objective
- 本文提出了一种简单有效的学习框架————Cross-X
- 设计了两个组件:
- 细粒度视觉分类:由于类内差异大且类间差异小,从具有非常细微差异的子类别中识别对象是一项艰巨的任务
- 目前的常见弱监督方式解决细粒度识别问题:首先检测对象部件,然后提取相应部分特征进行细粒度分类,但这些方法通常会单独处理每个图像的部分特定特征,而忽略它们在不同图像之间的关系
- 作者介绍了弱监督方式的FGVC的主要方式:
- 利用细粒度标签之间的关系来约束特征学习和定位判别性部分来提取特定部分特征
- 基于局部化的方式,具有从局部区域提取细粒度特征的优点(子类别之间的细微差异通常存在于局部区域)
- 介绍了早期的多阶段学习框架和近期的端到端学习框架并分析了这些模型改进有限的原因:
- 优化度量学习损失具有挑战性
- 涉及一个非平凡的样本选择过程
Method(s)
- 提出了Cross-X框架,类似于先前方法,同样采用多重激励模式生成注意力区域特征,但涉及两个新的组件:i)跨类别跨语义正则化器(C^3S) ii)跨层正则化器(CL)
- C^3S来引导不同的激励模块的注意特征来表示不同的语义部分
- !理想情况下:相同语义部分的注意力特征即使来自不同图片有着不同的类别标签也应比不同语义部分更相关
- 与度量学习损失相比,C^3S可以自然地集成到模型中,并且无需任何采样过程就可以很容易的进行优化
- 使用OSME模块(One-Squeeze Multi-Excitation一次挤压多次激发),生成多个特定注意力的特征图
- 首先使用全局平均池化(GAP)挤压
- 产生channel-wise描述符z
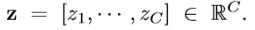
- 为每一个激励模块,一个门机制独立地运用在z上,p=1,2..,P(其中δ表示ReLU,σ表示Sigmoid)
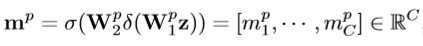
- 特定注意力的特征图U_p通过重新权重化原始特征图U通道生成:
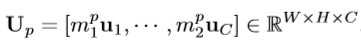
- C^3S 通过最大化相同激励模块的相关性,最小化不同激励模块的相关性来约束特征学习
- 首先对U_p进行全局平均池化(GAP)来获得汇聚后的特征f_p,并对f_p进行归一化
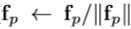
- 然后计算 激励模块之间的相关性矩阵 S_p,p‘:
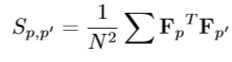
- 通过最大化S的对角来最大化相同激励模块之间的相关性,通过惩罚S的范数来最小化不同激励模块之间的相关性(使用F-范数):
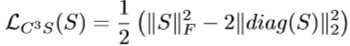
- C^3S正则化器可以很好地融入OSME模块,不需要任何采样过程就可以很容易的进行优化
- 两个原因导致不同层的预测输出组合在一起进行最终预测通常导致较差的性能:
- 中层特征对输入变化更敏感,这使得它们在类内变化较大的细粒度识别中不那么健壮
- 特征预测之间的关系没有被利用
- 为了解决上述问题,采用特征金字塔网络(FPN)来整合不同层之间的特征,并提出CL正则化器,通过匹配不同层之间的预测分布来学习鲁棒性特征
- 生成 融合特征图 U^G_p(使用L阶段和L-1阶段的特征图,这里的阶段指的是一组生成同样大小特征图的网络层)
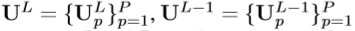
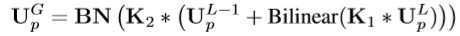
- 上述公式具体过程如下图所示(K1,K2分别是1x1和3x3的滤波器):
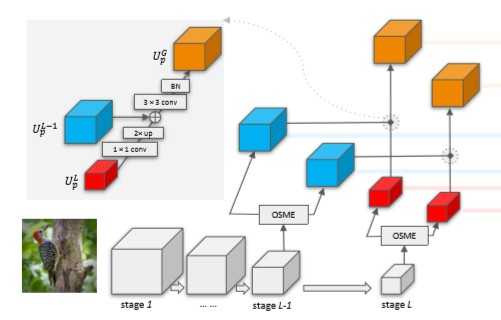
- U^G融合了中层精细空间分辨率的特性和顶层丰富的高级语义
- 探索特征预测之间的关系(f为输出层,σ为softmax函数):
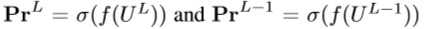
- CL正则化器通过最小化KL散度来匹配鼓励匹配 Pr^L-1 和 Pr^L (K为类的数量)
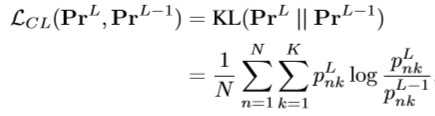
- CL正则化器可以被看作知识蒸馏利用U^L中具有丰富结构信息的“软目标”来指导 U^L-1和 U^G的特征学习(同时连接到一个全连接层生成logits再将logits转换为类概率被CL约束,过程如下图:)
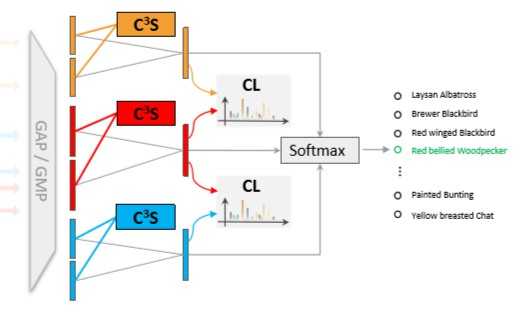
- 最终预测(通过结合 U^L , U^L-1 , U^G 获得最终的预测):
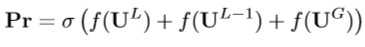
- L_data为分类损失,γ和λ为超参数,采用SGD优化,不需要多重裁切、数据增强、模型集成、单独初始化等优化方式
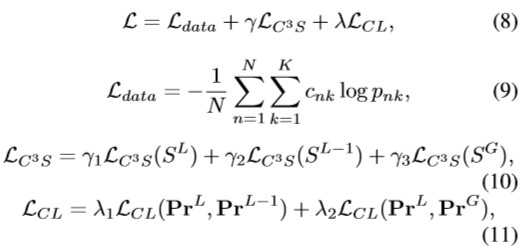
Evaluation
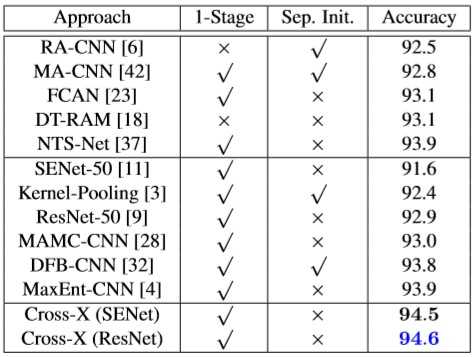
- 采用与其他不同的模型相比较,以最后FGVC数据集上的精度评估模型的性能(backbone采用SENet和RESNet)
- 在FGVC飞机上获得了92.7%的精度(排名第3),在斯坦福汽车上获得了94.6%的精度(排名第4),对比于其他模型性能提升明显。
- 斯坦福汽车:
Conclusion
- 该方法易于训练,并且易于扩展到大型数据集上(如NABirds),不涉及多阶段或多裁切机制
- 通过合并特征图引入额外语义特征提高FGVC性能
- 相同语义部分的注意力特征即使来自不同图片有着不同的类别标签也应比不同语义部分更相关
- 利用多尺度特征提高视觉任务的性能
- GMP导致单个区域激活一致(从左往右分别为 U^L-1 , U^L , U^G 最后一列为组合激活图)
- GAP导致多个区域激活分散(从左往右分别为 U^L-1 , U^L , U^G 最后一列为组合激活图)
- 来自同一层的激活图相互重叠,它们集中在对象的不同区域,与 U^L 相比 U^L-1 、 U^G 的激活区域相对较小,中心突出
Notes
- SENet 挤压-激发网络
- KL散度:又称相对熵、信息散度。两个概率分布(probability distribution)间差异的非对称性度量。
- 相对熵可以衡量两个随机分布之间的距离,当两个随机分布相同时,它们的相对熵为零,当两个随机分布的差别增大时,它们的相对熵也会增大。所以相对熵可以用于比较文本的相似度,先统计出词的频率,然后计算相对熵。另外,在多指标系统评估中,指标权重分配是一个重点和难点,也通过相对熵可以处理
Cross-X
原文:https://www.cnblogs.com/mercuialC/p/12220756.html

