采用两个平行的分支(判别性分支和互补性分支)去重采样图片,结果作为ResNet50的输入,并且以概率分配稀疏注意。同时使用FO(原始图像特征)FD(判别性分支采样得到的图像的特征)FC(互补性分支采样得到的图像特征)。提升强有力证据的同时维持弱的证据,使网络不易受强特征的主导。
互补性(complementary)分支————抽取互补性的特征
通过对先前细粒度图像识别方法不足的介绍,结合人类视觉系统理解一个场景的三个阶段,本文介绍了一种简单高效的框架选择性稀疏采样(S3N),以捕获各种细粒度的细节
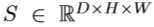
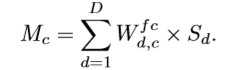
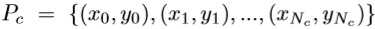
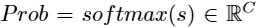

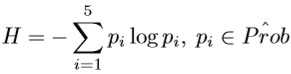

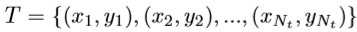










作者对于失败案例的原因分析:当目标与背景和其他物种相似时,由于互补性分支习得的特征是无用的,甚至是有害的。
图像识别领域引入注意力机制就是一个非常关键的技术,让深度学习模型更加关注某个局部的信息。
原文:https://www.cnblogs.com/mercuialC/p/12220750.html