MySQL由于自身简单、高效、可靠的特点,成为小米内部使用最广泛的数据库,但是当数据量达到千万/亿级别的时候,MySQL的相关操作会变的非常迟缓;如果这时还有实时BI展示的需求,对于mysql来说是一种灾难。
为了解决sql查询慢,查不了的业务痛点,我们探索出一套完整的实时同步,即席查询的解决方案,本文主要从实时同步的角度介绍相关工作。早期业务借助Sqoop将Mysql中的数据同步到Hive来进行数据分析,使用过程中也带来了一些问题:
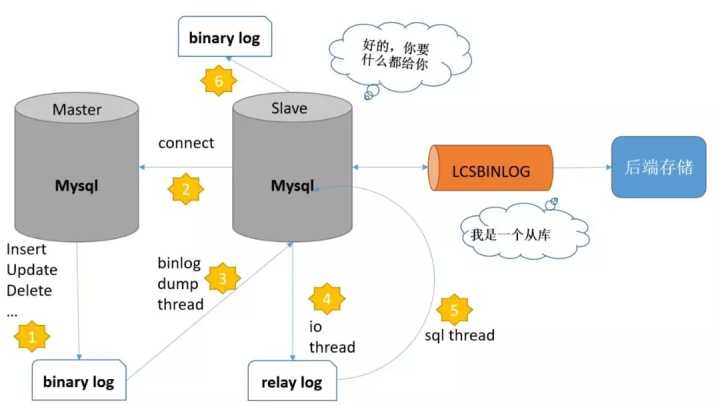
为了更有效地连接前端业务数据系统(MySQL)和后端统计分析系统(查询分析引擎),我们需要一套实时同步MySQL数据的解决方案。小米内部实践如何能够做到数据的实时同步呢?我们想到了MySQL主从复制时使用的binlog日志,它记录了所有的 DDL 和 DML 语句(除了数据查询语句select、show等),以事件形式记录,还包含语句所执行的消耗时间下面来看一下MySQL主从复制的原理,主要有以下几个步骤:
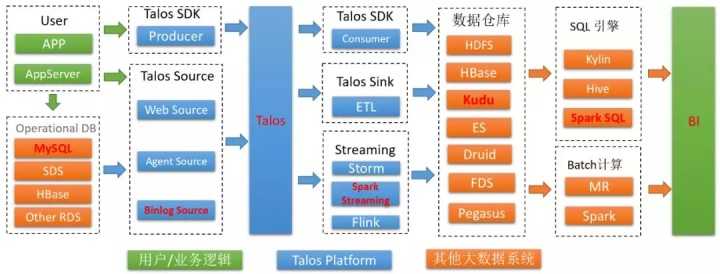
上图是Talos Platform中的整体流程架构,其中标红部分是目前LCSBinlog在小米内部使用最广泛的一条链路:Mysql ---> Talos ---> Kudu ---> BI,数据同步到kudu后借助Sparksql查询引擎为上层BI系统提供即席查询服务,Kudu和Sparksql的整合细节可以参见往期内容:告别”纷纷扰扰”—小米OLAP服务架构演进LCSBinlog服务的主体架构服务一共有两种角色 Master :主要负责作业的调度, Worker: 主要完成具体的数据同步任务在Worker上运行两种作业:
服务整体依赖于Zookeeper来同步服务状态,记录作业调度信息和标记作业运行状态;在kudu表中记录作业同步进度
控制流程如下:
如何保障数据正确性
>>>>顺序性
用户配置的每一个BinlogSource 都会绑定一个Talos的topic,在进行消费的时候需要保证同一条mysql记录操作的顺序性,消息队列Talos是无法保证全局消息有序的,只能保证partition内部有序。对于配置分库分表或者多库同步任务的BinlogSource,服务会根据库表信息进行hash,将数据写入相应的partiton,保证同一张表的数据在一个partition中,使得下游消费数据的顺序性;对于单表同步的作业目前使用一个partition保证其数据有序。>>>>
一致性
如何保证在作业异常退出后,作业重新启动能够完整地将mysql中的数据同步到下游系统,主要依赖于以下三点
应用场景有了这份数据我们可以做些什么事情呢,本节例举了几种常见的应用场景
>>>>实时更新缓存
业务查询类服务往往会在mysql之上架设一个缓存,减少对底层数据库的访问;当mysql库数据变化时,如果缓存还没有过期那么就会拿到过期的数据,业务期望能够实时更新缓存;利用binlog服务,根据策略实时将数据同步到redis中,这样就能够保证了缓存中数据有效性,减少了对数据库的调用,从而提高整体性能。
>>>>异步处理,系统解耦
随着业务的发展,同一份数据可能有不同的分析用途,数据成功写入到mysql的同时也需要被同步到其他系统;如果用同步的方式处理,一方面拉长了一次事务整个流程,另一方面系统间也会相互影响数据在mysql中操作成功后才会记录在binlog中,保证下游处理到时的一致性;使用binlog服务完成数据的下发,有助于系统的解耦关于异步处理,系统解耦在消息队列价值思考一文中有更深入的解读
>>>>即席查询的BI系统
就如文章开篇提到的,mysql在一定场景下的性能瓶颈,mysql数据同步到kudu后可以借助sparksql完成性能的提升因为同样是sql接口,对使用者的切换成本也是较低的,数据同步到更适合的存储中进行查询,也能够避免因大查询而对原mysql库其他查询的影响目前小米内部稳定运行3000+的同步作业,使用binlog服务同步数据到kudu中;小米内部BI明星产品XDATA借助整套同步流程很好地支持了运营、sql分析同学日常统计分析的需求如何使用Binlog数据用户接入数据的时候要求mysql库开启binlog日志格式必须为Row模式:记录的是每一行记录的每个字段变化前后的值,虽然会造成binlog数据量的增多,但是能够确保每一条记录准确性,避免数据同步不一致情况的出现最终通过监听binlog日志,LCSBinlog服务将数据转换成如下的数据结构,写入用户注册的Topic中, 目前Sink服务使用SparkStreaming实时转储数据到kudu中,后续也将逐步迁移到Flink上以提升资源利用、降低延迟
原文:https://www.cnblogs.com/dujian123/p/12228087.html