所谓的BitMap算法就是位图算法,简单说就是用一个bit位来标记某个元素所对应的value,而key即是该元素,由于BitMap使用了bit位来存储数据,因此可以大大节省存储空间,这是很常用的数据结构,比如用于Bloom Filter中、用于无重复整数的排序等等。bitmap通常基于数组来实现,数组中每个元素可以看成是一系列二进制数,所有元素组成更大的二进制集合。
我用一个简单的例子来详细介绍BitMap算法的原理。假设我们要对0-7内的5个元素(4,7,2,5,3)进行排序(这里假设元素没有重复)。我们可以使用BitMap算法达到排序目的。要表示8个数,我们需要8个byte,
1.首先我们开辟一个字节(8byte)的空间,将这些空间的所有的byte位都设置为0
2.然后便利这5个元素,第一个元素是4,因为下边从0开始,因此我们把第五个字节的值设置为1
3.然后再处理剩下的四个元素,最终8个字节的状态如下图
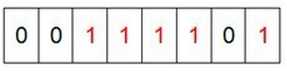
4.现在我们遍历一次bytes区域,把值为1的byte的位置输出(2,3,4,5,7),这样便达到了排序的目的
从上面的例子我们可以看出,BitMap算法的思想还是比较简单的,关键的问题是如何确定10进制的数到2进制的映射图。
MAP映射:
假设需要排序或则查找的数的总数N=100000000,BitMap中1bit代表一个数字,1个int = 4Bytes = 4*8bit = 32 bit,那么N个数需要N/32 int空间。所以我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
a[0]-----------------------------> 0-31
a[1]------------------------------> 32-63
a[2]-------------------------------> 64-95
a[3]--------------------------------> 96-127
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位:
1.求十进制数在对应数组a中的下标
十进制数0-31,对应在数组a[0]中,32-63对应在数组a[1]中,64-95对应在数组a[2]中………,使用数学归纳分析得出结论:对于一个十进制数n,其在数组a中的下标为:a[n/32]
2.求出十进制数在对应数a[i]中的下标
例如十进制数1在a[0]的下标为1,十进制数31在a[0]中下标为31,十进制数32在a[1]中下标为0。 在十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得在对应数组a[i]中的下标。
3.位移
对于一个十进制数n,对应在数组a[n/32][n%32]中,但数组a毕竟不是一个二维数组,我们通过移位操作实现置1
a[n/32] |= 1 << n % 32
移位操作:
a[n>>5] |= 1 << (n & 0x1F)
n & 0x1F 保留n的后五位 相当于 n % 32 求十进制数在数组a[i]中的下标。
用户标签使用BitMap的数据结构来存储,比如表示用户对应的标签表如下所示:
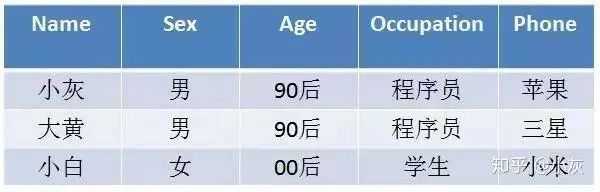
如果使用标签,也就是一个标签对应多个用户,如下所示,比较简单一看就会:
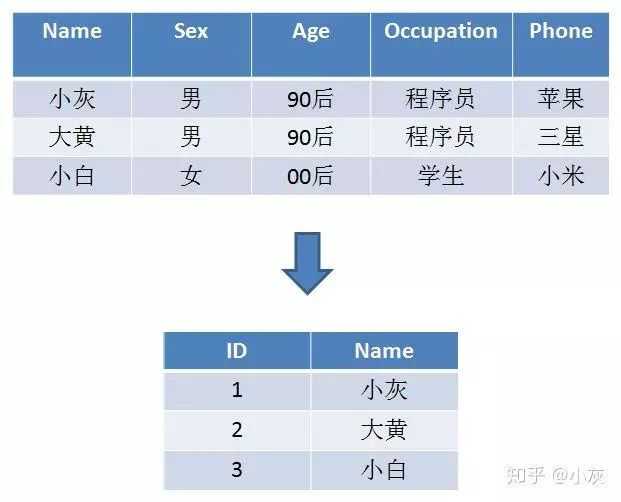
让每一个标签存储包含此标签的所有用户 ID,每一个标签都是一个独立的 Bitmap。这样,实现用户的去重和查询统计,就变得一目了然:
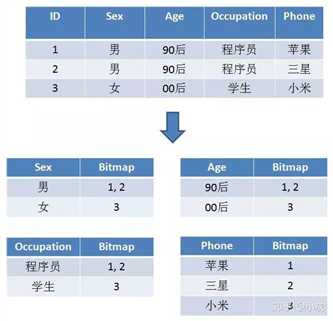
对上面例子的使用:
在用户群做交集和并集运算的时候,例如:
1,如何查找使用苹果手机的程序员用户?
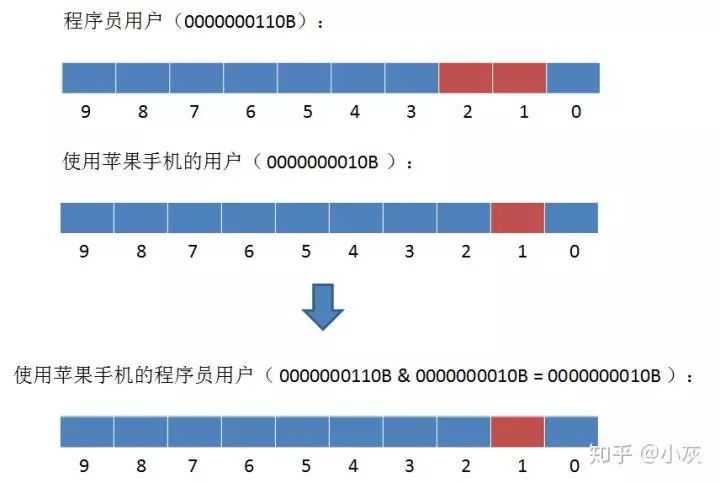
2.如何查找所有男性或者00后的用户?
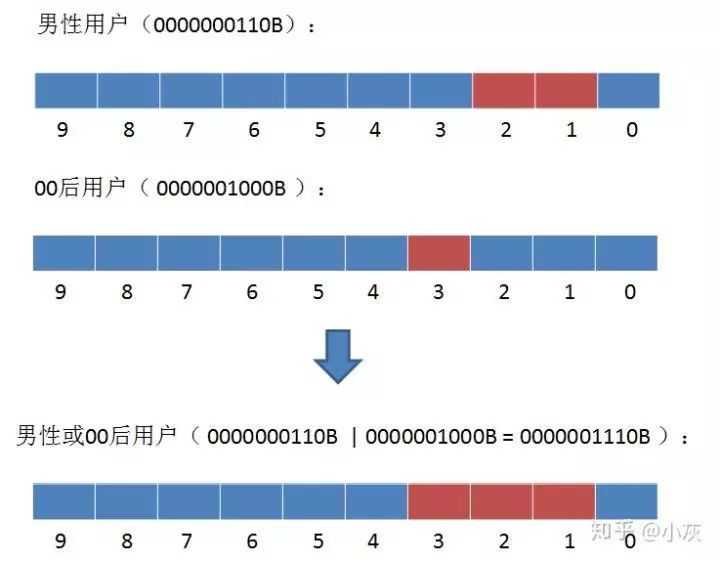
3,同样是刚才的例子,我们给定 90 后用户的 Bitmap,再给定一个全量用户的 Bitmap。最终要求出的是存在于全量用户,但又不存在于 90 后用户的部分。
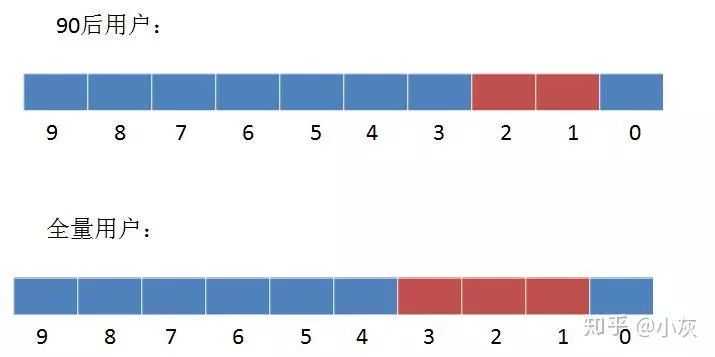
如何求出呢?我们可以使用异或操作,即相同位为 0,不同位为 1。 (1^1)
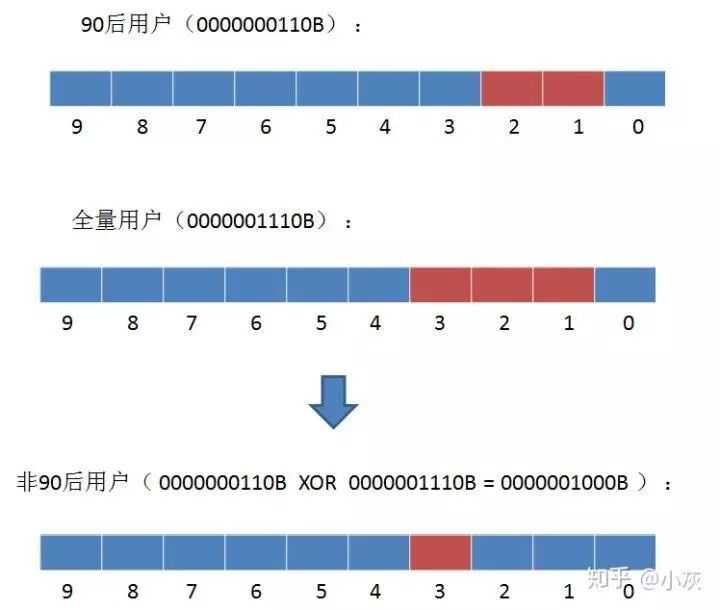
java实现:
1 /** 2 * ClassName BitMap4.java 3 * author Rhett.wang 4 * version 1.0.0 5 * Description TODO 6 * createTime 2020年01月24日 07:53:00 7 */ 8 public class BitMap4 { 9 //保存数据的 10 private byte[] bits; 11 12 //能够存储多少数据 13 private int capacity; 14 15 16 public BitMap4(int capacity){ 17 this.capacity = capacity; 18 19 //1bit能存储8个数据,那么capacity数据需要多少个bit呢,capacity/8+1,右移3位相当于除以8 20 bits = new byte[(capacity >>3 )+1]; 21 } 22 23 public void add(int num){ 24 // num/8得到byte[]的index 25 int arrayIndex = num >> 3; 26 27 // num%8得到在byte[index]的位置 28 int position = num & 0x07; 29 30 //将1左移position后,那个位置自然就是1,然后和以前的数据做|,这样,那个位置就替换成1了。 31 bits[arrayIndex] |= 1 << position; 32 } 33 34 public boolean contain(int num){ 35 // num/8得到byte[]的index 36 int arrayIndex = num >> 3; 37 38 // num%8得到在byte[index]的位置 39 int position = num & 0x07; 40 41 //将1左移position后,那个位置自然就是1,然后和以前的数据做&,判断是否为0即可 42 return (bits[arrayIndex] & (1 << position)) !=0; 43 } 44 45 public void clear(int num){ 46 // num/8得到byte[]的index 47 int arrayIndex = num >> 3; 48 49 // num%8得到在byte[index]的位置 50 int position = num & 0x07; 51 52 //将1左移position后,那个位置自然就是1,然后对取反,再与当前值做&,即可清除当前的位置了. 53 bits[arrayIndex] &= ~(1 << position); 54 55 } 56 57 public static void main(String[] args) { 58 BitMap4 bitmap = new BitMap4(100); 59 bitmap.add(7); 60 System.out.println("插入7成功"); 61 62 boolean isexsit = bitmap.contain(7); 63 System.out.println("7是否存在:"+isexsit); 64 65 bitmap.clear(7); 66 isexsit = bitmap.contain(7); 67 System.out.println("7是否存在:"+isexsit); 68 } 69 }
PYTHON代码实现:
1 class BitMap(): 2 def __init__(self,max): 3 self.size=int((max +31 -1)/31) 4 self.array=[0 for i in range(self.size)] 5 6 def bitindex(self,num): 7 return num%31 8 9 def set_1(self,num): 10 elemindex=(num//31) 11 byteindex=self.bitindex(num) 12 ele=self.array[elemindex] 13 self.array[elemindex] = ele| (1<< byteindex) 14 15 16 def test_1(self,i): 17 elemindex=(i//31) 18 bytearray= self.bitindex(i) 19 if self.array[elemindex] & (1 << bytearray): 20 return True 21 return False 22 23 if __name__ =="__main__": 24 Max = ord(‘z‘) 25 shuffle_array=[x for x in ‘qwelajkda‘] 26 ret =[] 27 bitmap =BitMap(Max) 28 for c in shuffle_array: 29 bitmap.set_1(ord(c)) 30 31 for i in range(Max+1): 32 if bitmap.test_1(i): 33 ret.append(chr(i)) 34 35 print(u‘原始数组是:%s‘ % shuffle_array) 36 print(u‘排序以后的数组是:%s‘ % ret)
scala代码实现
1 /** 2 * ClassName BitMap.java 3 * author Rhett.wang 4 * version 1.0.0 5 * Description TODO 6 * createTime 2020年01月24日 10:30:00 7 */ 8 class BitMap(bitmap:Array[Byte], length:Int) { 9 10 } 11 object BitMap { 12 var bitmap:Array[Int]=Array() 13 def main(args: Array[String]) { 14 15 var bitmaps=TestBit(100) 16 setBit(32) 17 println(getBit(32)) 18 println(getBit(11)) 19 } 20 def TestBit(length:Int):Unit={ 21 bitmap= new Array[Int]((length >> 5).toInt + (if ((length & 31) > 0) 1 22 else 0)) 23 } 24 25 def getBit(index: Long): Int = { 26 var intData: Int = bitmap(((index - 1) >> 5).toInt) 27 var offset: Int = ((index - 1) & 31).toInt 28 return intData >> offset & 0x01 29 } 30 31 def setBit(index: Long) { 32 var belowIndex: Int = ((index - 1) >> 5).toInt 33 var offset: Int = ((index - 1) & 31).toInt 34 var inData: Int = bitmap(belowIndex) 35 bitmap(belowIndex) = inData | (0x01 << offset) 36 } 37 38 /* def clear(num:Int):Unit={ 39 var arrayIndex: Int = num >> 5 40 var position: Int = num & 0x1F 41 bitmap(arrayIndex) =(bitmap(arrayIndex) & ~(1 << position)).toByte 42 }*/ 43 44 45 }
位图索引被广泛用于数据库和搜索引擎中,通过利用位级并行,它们可以显著加快查询速度。但是,位图索引会占用大量的内存,因此我们会更喜欢压缩位图索引。 Roaring Bitmaps 就是一种十分优秀的压缩位图索引,后文统称 RBM。压缩位图索引有很多种,比如基于 RLE(Run-Length Encoding,运行长度编码)的WAH (Word Aligned Hybrid Compression Scheme) 和 Concise (Compressed ‘n’ Composable Integer Set)。相比较前者, RBM 能提供更优秀的压缩性能和更快的查询效率。
RBM 的用途和 Bitmap 很差不多(比如说索引),只是说从性能、空间利用率各方面更优秀了。目前 RBM 已经在很多成熟的开源大数据平台中使用,简单列几个作为参考。
1 Apache Lucene and derivative systems such as Solr and Elasticsearch, 2 Metamarkets’ Druid, 3 Apache Spark, 4 Apache Hive, 5 eBay’s Apache Kylin, 6 ……
RBM 的主要思想并不复杂,简单来讲,有如下三条:
1,我们将 32-bit 的范围 ([0, n)) 划分为 2^16 个桶,每一个桶有一个 Container 来存放一个数值的低16位;
2,在存储和查询数值的时候,我们将一个数值 k 划分为高 16 位(k % 2^16)和低 16 位(k mod 2^16),取高 16 位找到对应的桶,然后在低 16 位存放在相应的 Container 中;
3,容器的话, RBM 使用两种容器结构: Array Container 和 Bitmap Container。Array Container 存放稀疏的数据,Bitmap Container 存放稠密的数据。即,若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。
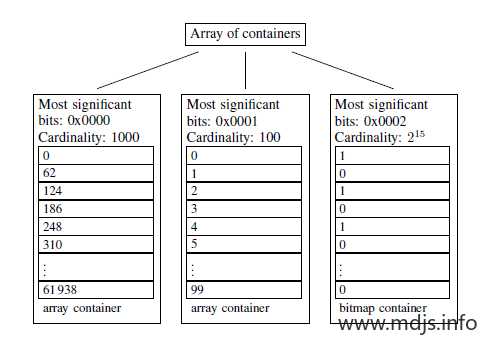
如下图,就是官网给出的一个例子,三个容器分别代表了三个数据集:
the list of the first 1000 multiples of 62
all integers [216, 216 + 100)
all even numbers in [2216, 3216)
举例说明:
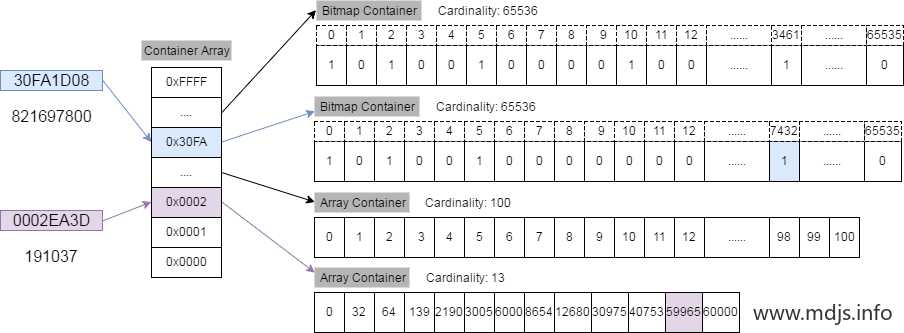
看完前面的还不知道在说什么?没关系,举个栗子说明就好了。现在我们要将 821697800 这个 32 bit 的整数插入 RBM 中,整个算法流程是这样的:
821697800 对应的 16 进制数为 30FA1D08, 其中高 16 位为 30FA, 低16位为 1D08。
我们先用二分查找从一级索引(即 Container Array)中找到数值为 30FA 的容器(如果该容器不存在,则新建一个),从图中我们可以看到,该容器是一个 Bitmap 容器。
找到了相应的容器后,看一下低 16 位的数值 1D08,它相当于是 7432,因此在 Bitmap 中找到相应的位置,将其置为 1 即可。
下面介绍到的是RoaringBitmap的核心,三种Container。
通过上面的介绍我们知道,每个32位整形的高16位已经作为key存储在RoaringArray中了,那么Container只需要处理低16位的数据。
结构很简单,只有一个short[] content,将16位value直接存储。
short[] content始终保持有序,方便使用二分查找,且不会存储重复数值。
因为这种Container存储数据没有任何压缩,因此只适合存储少量数据。
ArrayContainer占用的空间大小与存储的数据量为线性关系,每个short为2字节,因此存储了N个数据的ArrayContainer占用空间大致为2N字节。存储一个数据占用2字节,存储4096个数据占用8kb。
根据源码可以看出,常量DEFAULT_MAX_SIZE值为4096,当容量超过这个值的时候会将当前Container替换为BitmapContainer。
这种Container使用long[]存储位图数据。我们知道,每个Container处理16位整形的数据,也就是0~65535,因此根据位 图的原理,需要65536个比特来存储数据,每个比特位用1来表示有,0来表示无。每个long有64位,因此需要1024个long来提供65536个 比特。
因此,每个BitmapContainer在构建时就会初始化长度为1024的long[]。这就意味着,不管一个BitmapContainer中只存储了1个数据还是存储了65536个数据,占用的空间都是同样的8kb。
解释一下为什么这里用的 4096 这个阈值?因为一个 Integer 的低 16 位是 2Byte,因此对应到 Arrary Container 中的话就是 2Byte * 4096 = 8KB;同样,对于 Bitmap Container 来讲,2^16 个 bit 也相当于是 8KB。
RunContainer中的Run指的是行程长度压缩算法(Run Length Encoding),对连续数据有比较好的压缩效果。
它的原理是,对于连续出现的数字,只记录初始数字和后续数量。即:
对于数列11,它会压缩为11,0;
对于数列11,12,13,14,15,它会压缩为11,4;
对于数列11,12,13,14,15,21,22,它会压缩为11,4,21,1;
源码中的short[] valueslength中存储的就是压缩后的数据。
这种压缩算法的性能和数据的连续性(紧凑性)关系极为密切,对于连续的100个short,它能从200字节压缩为4字节,但对于完全不连续的100个short,编码完之后反而会从200字节变为400字节。
如果要分析RunContainer的容量,我们可以做下面两种极端的假设:
最好情况,即只存在一个数据或只存在一串连续数字,那么只会存储2个short,占用4字节
最坏情况,0~65535的范围内填充所有的奇数位(或所有偶数位),需要存储65536个short,128kb
代码测试示例:
1 import org.roaringbitmap.RoaringBitmap; 2 3 import java.util.function.Consumer; 4 5 /** 6 * ClassName RBitMap.java 7 * author Rhett.wang 8 * version 1.0.0 9 * Description TODO 10 * createTime 2020年01月25日 21:09:00 11 */ 12 public class RBitMap { 13 public static void main(String[] args) { 14 test1(); 15 } 16 private static void test1(){ 17 //向rr中添加1、2、3、1000四个数字 18 RoaringBitmap rr = RoaringBitmap.bitmapOf(1,2,3,1000); 19 //创建RoaringBitmap rr2 20 RoaringBitmap rr2 = new RoaringBitmap(); 21 //向rr2中添加10000-12000共2000个数字 22 rr2.add(10000L,12000L); 23 //返回第3个数字是1000,第0个数字是1,第1个数字是2,则第3个数字是1000 24 rr.select(3); 25 //返回value = 2 时的索引为 1。value = 1 时,索引是 0 ,value=3的索引为2 26 rr.rank(2); 27 //判断是否包含1000 28 rr.contains(1000); // will return true 29 //判断是否包含7 30 rr.contains(7); // will return false 31 32 //两个RoaringBitmap进行or操作,数值进行合并,合并后产生新的RoaringBitmap叫rror 33 RoaringBitmap rror = RoaringBitmap.or(rr, rr2); 34 //rr与rr2进行位运算,并将值赋值给rr 35 rr.or(rr2); 36 //判断rror与rr是否相等,显然是相等的 37 boolean equals = rror.equals(rr); 38 if(!equals) throw new RuntimeException("bug"); 39 // 查看rr中存储了多少个值,1,2,3,1000和10000-12000,共2004个数字 40 long cardinality = rr.getLongCardinality(); 41 System.out.println(cardinality); 42 //遍历rr中的value 43 for(int i : rr) { 44 System.out.println(i); 45 } 46 //这种方式的遍历比上面的方式更快 47 rr.forEach((Consumer<? super Integer>) i -> { 48 System.out.println(i.intValue()); 49 }); 50 } 51 }
在RoaringBitmap中,32位整数被分成了2^16个块。任何一个32位整数的前16位决定放在哪个块里。后16位就是放在这个块里的内容。比如0xFFFF0000和0xFFFF0001,前16位都是FFFF,表明这两个数应该放在一个块里。后16位分别是0和1。在这个块中指保存0和1就可以了,不需要保存完整的整数。
在最开始的时候,一个块中包含一个长度为4的short数组,后16位所对应的值就存在这个short数组里。注意在插入的时候要保持顺序性,这里就需要用到二分查找来加快速度了。如果当块中的元素大于short数组的长度时,就需要重新分配更大的数组,把当前数组copy过去,并把新值插入对应的位置。扩展数组大小和STL中vector的方式类似,不过并不是完全的加倍,而且上限是4096,也就是说最多只保存4096个元素。那么问题来了,超过了4096怎么办呢?
一个块里最多可能需要存放2^16个元素,那么如果是用short来存放,最多需要65536个short,那么就是131072个byte。如果换一种方式,用位来存储元素,那么就需要65536个bit,相当于1024个long型数组,即2048个int,也就是4096个short。
所以,当一个块中元素数量小于等于4096的时候,用有序short数组来保存元素,而当元素数量大于4096的时候,用长度为1024的long数组来按位表示元素是否存在。
当bitmap中有多个块的时候,块的信息是用数组来保存的。这个数组同样需要保持顺序性,也是用二分查找找到一个块的位置。所以,当一个整数过来之后,首先根据前16位计算出块的key,然后在块的数组中二分查找。找到的话,就把后16位保存在这个块中。找不到,就创建一个新块,把后16位保存在块中,再把块插入对应的位置。
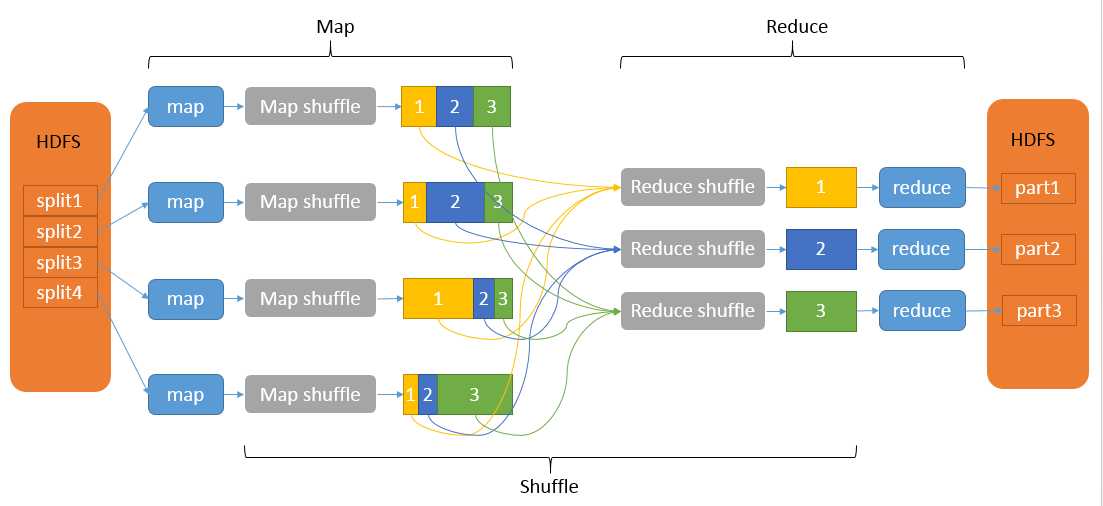
首先,请大家思考一个问题:在大数据处理领域中,什么环节是你最不希望见到的?以我的观点来看,shuffle 是我最不愿意见到的环节,因为一旦出现了非常多的 shuffle,就会占用大量的磁盘和网络 IO,从而导致任务进行得非常缓慢。而今天我们所讨论的去重分析,就是一个会产生非常多 shuffle 的场景,先大概介绍一下shuffle原理:
Shuffle描述着数据从map task输出到reduce task输入的这段过程。在分布式情况下,reduce task需要跨节点去拉取其它节点上的map task结果。这一过程将会产生网络资源消耗和内存,磁盘IO的消耗。
先来看以下场景:

我们有一张商品访问表,表上有 item 和 user_id 两个列,我们希望求商品的 UV,这是去重非常典型的一个场景。我们的数据是存储在分布式平台上的,分别在数据节点 1 和 2 上。
我们从物理执行层面上想一下这句 SQL 背后会发生什么故事:首先分布式计算框架启动任务, 从两个节点上去拿数据, 因为 SQL group by 了 item 列, 所以需要以 item 为 key 对两个表中的原始数据进行一次 shuffle。我们来看看需要 shuffle 哪些数据:因为 select/group by了 item,所以 item 需要 shuffle 。但是,user_id 我们只需要它的一个统计值,能不能不 shuffle 整个 user_id 的原始值呢?
如果只是简单的求 count 的话, 每个数据节点分别求出对应 item 的 user_id 的 count, 然后只要 shuffle 这个 count 就行了,因为count 只是一个数字, 所以 shuffle 的量非常小。但是由于分析的指标是 count distinct,我们不能简单相加两个节点user_id 的 count distinct 值,我们只有得到一个 key 对应的所有 user_id 才能统计出正确的 count distinct值,而这些值原先可能分布在不同的节点上,所以我们只能通过 shuffle 把这些值收集到同一个节点上再做去重。而当 user_id 这一列的数据量非常大的时候,需要 shuffle 的数据量也会非常大。我们其实最后只需要一个 count 值,那么有办法可以不 shuffle 整个列的原始值吗?我下面要介绍的两种算法就提供了这样的一种思路,使用更少的信息位,同样能够求出该列不重复元素的个数(基数)

第一种要介绍的算法是一种精确的去重算法,主要利用了 Bitmap 的原理。Bitmap 也称之为 Bitset,它本质上是定义了一个很大的 bit 数组,每个元素对应到 bit 数组的其中一位。例如有一个集合[2,3,5,8]对应的 Bitmap 数组是[001101001],集合中的 2 对应到数组 index 为 2 的位置,3 对应到 index 为 3 的位置,下同,得到的这样一个数组,我们就称之为 Bitmap。很直观的,数组中 1 的数量就是集合的基数。追本溯源,我们的目的是用更小的存储去表示更多的信息,而在计算机最小的信息单位是 bit,如果能够用一个 bit 来表示集合中的一个元素,比起原始元素,可以节省非常多的存储。
这就是最基础的 Bitmap,我们可以把 Bitmap 想象成一个容器,我们知道一个 Integer 是32位的,如果一个 Bitmap 可以存放最多 Integer.MAX_VALUE 个值,那么这个 Bitmap 最少需要 32 的长度。一个 32 位长度的 Bitmap 占用的空间是512 M (2^32/8/1024/1024),这种 Bitmap 存在着非常明显的问题:这种 Bitmap 中不论只有 1 个元素或者有 40 亿个元素,它都需要占据 512 M 的空间。回到刚才求 UV 的场景,不是每一个商品都会有那么多的访问,一些爆款可能会有上亿的访问,但是一些比较冷门的商品可能只有几个用户浏览,如果都用这种 Bitmap,它们占用的空间都是一样大的,这显然是不可接受的。

对于上节说的问题,有一种设计的非常的精巧 Bitmap,叫做 Roaring Bitmap,能够很好地解决上面说的这个问题。我们还是以存放 Integer 值的 Bitmap 来举例,Roaring Bitmap 把一个 32 位的 Integer 划分为高 16 位和低 16 位,取高 16 位找到该条数据所对应的 key,每个 key 都有自己的一个 Container。我们把剩余的低 16 位放入该 Container 中。依据不同的场景,有 3 种不同的 Container,分别是 Array Container、Bitmap Container 和 Run Container,下文将一一介绍。

首先第一种,是 Roaring Bitmap 初始化时默认的 Container,叫做 Array Container。Array Container 适合存放稀疏的数据,Array Container 内部的数据结构是一个 short array,这个 array 是有序的,方便查找。数组初始容量为 4,数组最大容量为 4096。超过最大容量 4096 时,会转换为 Bitmap Container。这边举例来说明数据放入一个 Array Container 的过程:有 0xFFFF0000 和 0xFFFF0001 两个数需要放到 Bitmap 中, 它们的前 16 位都是 FFFF,所以他们是同一个 key,它们的后 16 位存放在同一个 Container 中; 它们的后 16 位分别是 0 和 1, 在 Array Container 的数组中分别保存 0 和 1 就可以了,相较于原始的 Bitmap 需要占用 512M 内存来存储这两个数,这种存放实际只占用了 2+4=6 个字节(key 占 2 Bytes,两个 value 占 4 Bytes,不考虑数组的初始容量)。

第二种 Container 是 Bitmap Container,其原理就是上文说的 Bitmap。它的数据结构是一个 long 的数组,数组容量固定为 1024,和上文的 Array Container 不同,Array Container 是一个动态扩容的数组。这边推导下 1024 这个值:由于每个 Container 还需处理剩余的后 16 位数据,使用 Bitmap 来存储需要 8192 Bytes(2^16/8), 而一个 long 值占 8 个 Bytes,所以一共需要 1024(8192/8)个 long 值。所以一个 Bitmap container 固定占用内存 8 KB(1024 * 8 Byte)。当 Array Container 中元素到 4096 个时,也恰好占用 8 k(4096*2Bytes)的空间,正好等于 Bitmap 所占用的 8 KB。而当你存放的元素个数超过 4096 的时候,Array Container 的大小占用还是会线性的增长,但是 Bitmap Container 的内存空间并不会增长,始终还是占用 8 K,所以当 Array Container 超过最大容量(DEFAULT_MAX_SIZE)会转换为 Bitmap Container。
我们自己在 Kylin 中实践使用 Roaring Bitmap 时,我们发现 Array Container 随着数据量的增加会不停地 resize 自己的数组,而 Java 数组的 resize 其实非常消耗性能,因为它会不停地申请新的内存,同时老的内存在复制完成前也不会释放,导致内存占用变高,所以我们建议把 DEFAULT_MAX_SIZE 调得低一点,调成 1024 或者 2048,减少 Array Container 后期 reszie 数组的次数和开销。

最后一种 Container 叫做Run Container,这种 Container 适用于存放连续的数据。比如说 1 到 100,一共 100 个数,这种类型的数据称为连续的数据。这边的Run指的是Run Length Encoding(RLE),它对连续数据有比较好的压缩效果。原理是对于连续出现的数字, 只记录初始数字和后续数量。例如: 对于 [11, 12, 13, 14, 15, 21, 22],会被记录为 11, 4, 21, 1。很显然,该 Container 的存储占用与数据的分布紧密相关。最好情况是如果数据是连续分布的,就算是存放 65536 个元素,也只会占用 2 个 short。而最坏的情况就是当数据全部不连续的时候,会占用 128 KB 内存。
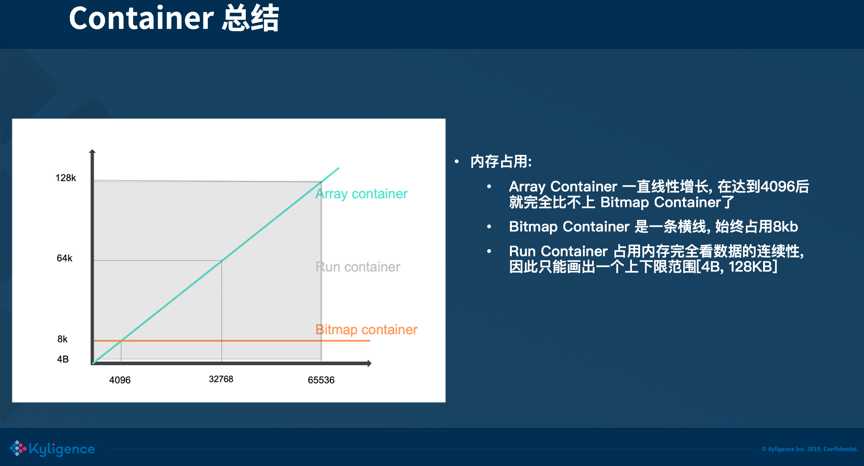
总结:用一张图来总结3种 Container 所占的存储空间,可以看到元素个数达到 4096 之前,选用 Array Container 的收益是最好的,当元素个数超过了 4096 时,Array Container 所占用的空间还是线性的增长,而 Bitmap Container 的存储占用则与数据量无关,这个时候 Bitmap Container 的收益就会更好。而 Run Container 占用的存储大小完全看数据的连续性, 因此只能画出一个上下限范围 [4 Bytes, 128 KB]。
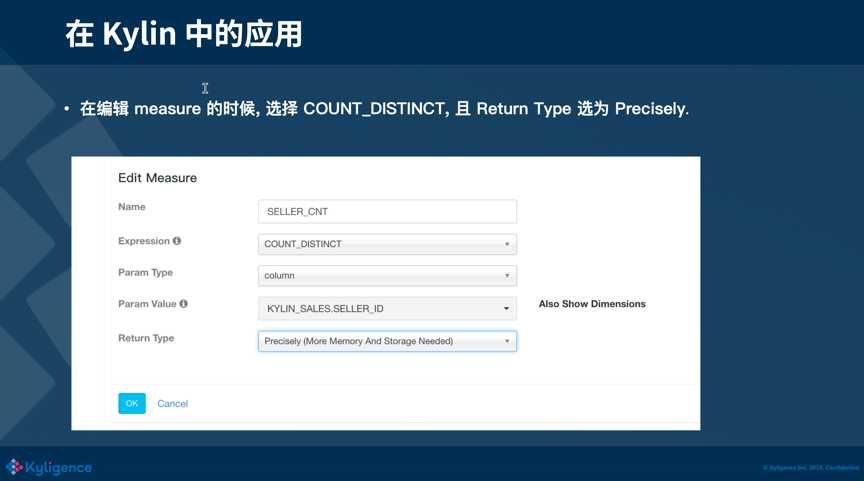
我们再来看一下Bitmap 在 Kylin 中的应用,Kylin 中编辑 measure 的时候,可以选择 Count Distinct,且Return Type 选为 Precisely,点保存就可以了。但是事情没有那么简单,刚才上文在讲 Bitmap 时,一直都有一个前提,放入的值都是数值类型,但是如果不是数值类型的值,它们不能够直接放入 Bitmap,这时需要构建一个全区字典,做一个值到数值的映射,然后再放入 Bitmap 中。

在 Kylin 中构建全局字典,当列的基数非常高的时候,全局字典会成为一个性能的瓶颈。针对这种情况,社区也一直在努力做优化,这边简单介绍几种优化的策略,更详细的优化策略可以见文末的参考链接。
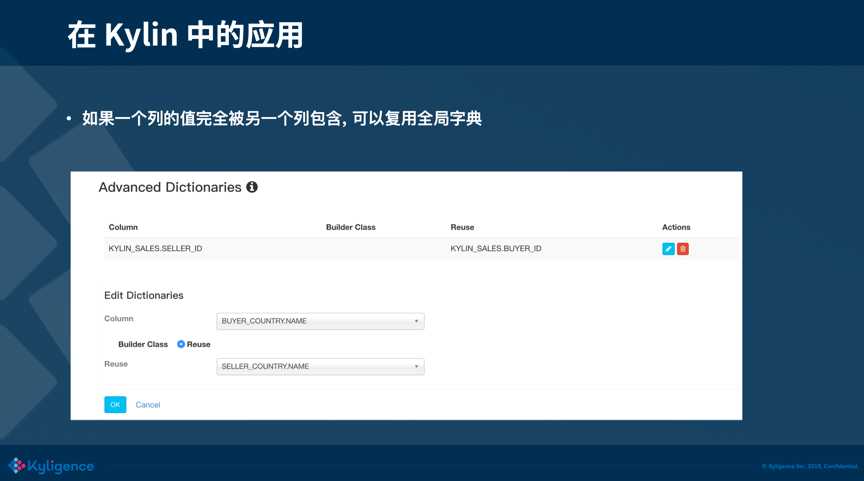
1)当一个列的值完全被另外一个列包含,而另一个列有全局字典,可以复用另一个列的全局字典
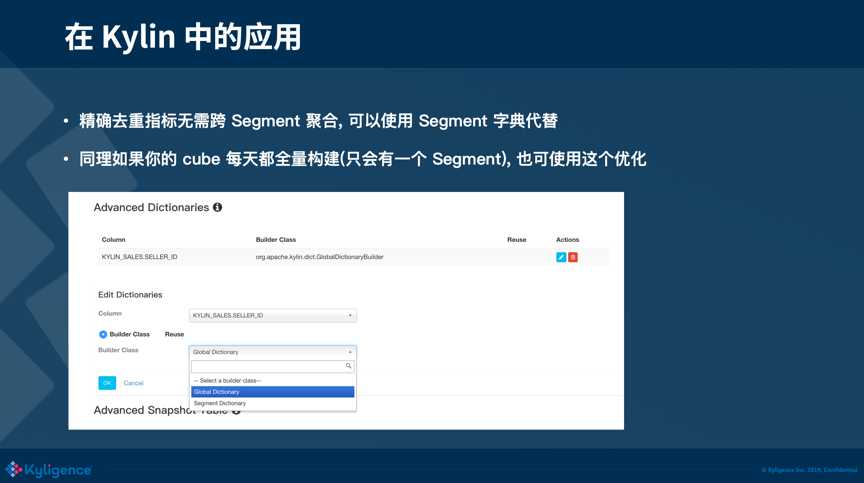
2)当精确去重指标不需要跨 Segment 聚合的时候,可以使用这个列的 Segment 字典代替(这个列需要字典编码)。在 Kylin 中,Segment 就相当于时间分片的概念。当不会发生跨 Segments 的分析时,这个列的 Segment 字典就可以代替这个全局字典。
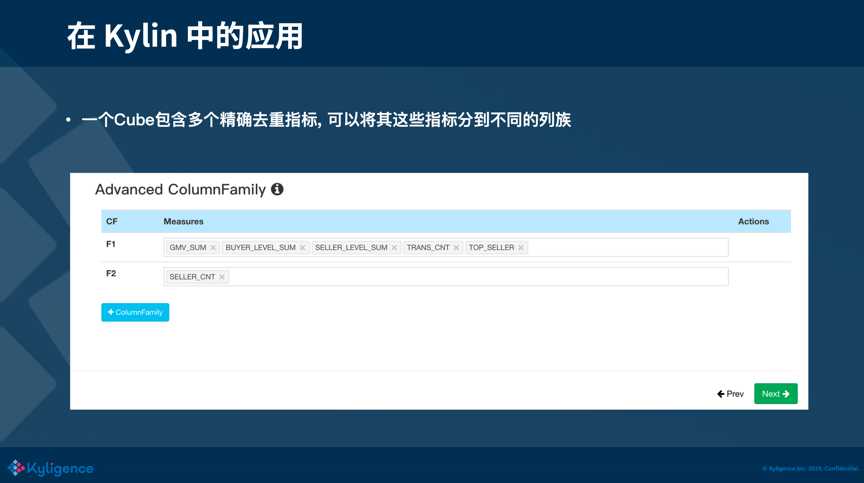
3)如果你的 cube 包含很多的精确去重指标,可以考虑将这些指标放到不同的列族上。不止是精确去重,像一些复杂 measure,我们都建议使用多个列族去存储,可以提升查询的性能。
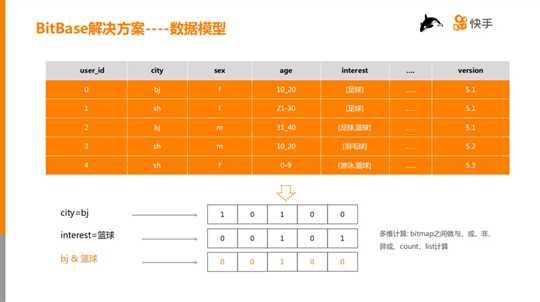
如上图所示,首先将原始数据的一列的某个值抽象成 bitmap(比特数组),举例:city=bj,city 是维度,bj (北京) 是维度值,抽象成 bitmap 值就是10100,表示第0个用户在 bj,第1个用户不在北京,依次类推。然后将多维度之间的组合转换为 bitmap 计算:bitmap 之间做与、或、非、异或,举例:比如在北京的用户,且兴趣是篮球,这样的用户有多少个,就转换为图中所示的两个 bitmap 做与运算,得到橙色的 bitmap,最后,再对 bitmap 做 count 运算。count 表示统计“1”的个数,list 是列举“1”所在的数组 index,业务上表示 userId。
创建表:使用phoenix在HBase中创建测试表,字段使用VARBINARY类型
1 CREATE TABLE IF NOT EXISTS test_binary ( 2 date VARCHAR NOT NULL, 3 dist_mem VARBINARY 4 CONSTRAINT test_binary_pk PRIMARY KEY (date) 5 ) SALT_BUCKETS=6;
创建完成后使用RoaringBitmap序列化数据存入数据库:
自定义代码:
1 import org.apache.spark.sql.Row; 2 import org.apache.spark.sql.expressions.MutableAggregationBuffer; 3 import org.apache.spark.sql.expressions.UserDefinedAggregateFunction; 4 import org.apache.spark.sql.types.DataType; 5 import org.apache.spark.sql.types.DataTypes; 6 import org.apache.spark.sql.types.StructField; 7 import org.apache.spark.sql.types.StructType; 8 import org.roaringbitmap.RoaringBitmap; 9 10 import java.io.*; 11 import java.util.ArrayList; 12 import java.util.List; 13 14 /** 15 * 实现自定义聚合函数Bitmap 16 */ 17 public class UdafBitMap extends UserDefinedAggregateFunction { 18 @Override 19 public StructType inputSchema() { 20 List<StructField> structFields = new ArrayList<>(); 21 structFields.add(DataTypes.createStructField("field", DataTypes.BinaryType, true)); 22 return DataTypes.createStructType(structFields); 23 } 24 25 @Override 26 public StructType bufferSchema() { 27 List<StructField> structFields = new ArrayList<>(); 28 structFields.add(DataTypes.createStructField("field", DataTypes.BinaryType, true)); 29 return DataTypes.createStructType(structFields); 30 } 31 32 @Override 33 public DataType dataType() { 34 return DataTypes.LongType; 35 } 36 37 @Override 38 public boolean deterministic() { 39 //是否强制每次执行的结果相同 40 return false; 41 } 42 43 @Override 44 public void initialize(MutableAggregationBuffer buffer) { 45 //初始化 46 buffer.update(0, null); 47 } 48 49 @Override 50 public void update(MutableAggregationBuffer buffer, Row input) { 51 // 相同的executor间的数据合并 52 // 1. 输入为空直接返回不更新 53 Object in = input.get(0); 54 if(in == null){ 55 return ; 56 } 57 // 2. 源为空则直接更新值为输入 58 byte[] inBytes = (byte[]) in; 59 Object out = buffer.get(0); 60 if(out == null){ 61 buffer.update(0, inBytes); 62 return ; 63 } 64 // 3. 源和输入都不为空使用bitmap去重合并 65 byte[] outBytes = (byte[]) out; 66 byte[] result = outBytes; 67 RoaringBitmap outRR = new RoaringBitmap(); 68 RoaringBitmap inRR = new RoaringBitmap(); 69 try { 70 outRR.deserialize(new DataInputStream(new ByteArrayInputStream(outBytes))); 71 inRR.deserialize(new DataInputStream(new ByteArrayInputStream(inBytes))); 72 outRR.or(inRR); 73 ByteArrayOutputStream bos = new ByteArrayOutputStream(); 74 outRR.serialize(new DataOutputStream(bos)); 75 result = bos.toByteArray(); 76 } catch (IOException e) { 77 e.printStackTrace(); 78 } 79 buffer.update(0, result); 80 } 81 82 @Override 83 public void merge(MutableAggregationBuffer buffer1, Row buffer2) { 84 //不同excutor间的数据合并 85 update(buffer1, buffer2); 86 } 87 88 @Override 89 public Object evaluate(Row buffer) { 90 //根据Buffer计算结果 91 long r = 0l; 92 Object val = buffer.get(0); 93 if (val != null) { 94 RoaringBitmap rr = new RoaringBitmap(); 95 try { 96 rr.deserialize(new DataInputStream(new ByteArrayInputStream((byte[]) val))); 97 r = rr.getLongCardinality(); 98 } catch (IOException e) { 99 e.printStackTrace(); 100 } 101 } 102 return r; 103 } 104 }
调用例子:
1 /** 2 * 使用自定义函数解析bitmap 3 * 4 * @param sparkSession 5 * @return 6 */ 7 private static void udafBitmap(SparkSession sparkSession) { 8 try { 9 Properties prop = PropUtil.loadProp(DB_PHOENIX_CONF_FILE); 10 // JDBC连接属性 11 Properties connProp = new Properties(); 12 connProp.put("driver", prop.getProperty(DB_PHOENIX_DRIVER)); 13 connProp.put("user", prop.getProperty(DB_PHOENIX_USER)); 14 connProp.put("password", prop.getProperty(DB_PHOENIX_PASS)); 15 connProp.put("fetchsize", prop.getProperty(DB_PHOENIX_FETCHSIZE)); 16 // 注册自定义聚合函数 17 sparkSession.udf().register("bitmap",new UdafBitMap()); 18 sparkSession 19 .read() 20 .jdbc(prop.getProperty(DB_PHOENIX_URL), "test_binary", connProp) 21 // sql中必须使用global_temp.表名,否则找不到 22 .createOrReplaceGlobalTempView("test_binary"); 23 //sparkSession.sql("select YEAR(TO_DATE(date)) year,bitmap(dist_mem) memNum from global_temp.test_binary group by YEAR(TO_DATE(date))").show(); 24 sparkSession.sql("select date,bitmap(dist_mem) memNum from global_temp.test_binary group by date").show(); 25 } catch (Exception e) { 26 e.printStackTrace(); 27 } 28 }
感谢网络大神的分享:技术共勉
https://kyligence.io/zh/blog/count-distinct-bitmap/
https://www.jianshu.com/p/ded6e8ecd0d1
https://blog.csdn.net/xiongbingcool/article/details/81282118
http://www.sohu.com/a/327627247_315839
https://blog.csdn.net/xywtalk/article/details/52590275
原文:https://www.cnblogs.com/boanxin/p/12232604.html