DDIA_Chapter11 学习笔记
之前,我们讨论了批处理技术,它读取一组文件作为输入,并生成一组新的文件作为输出。输出是衍生数据(derived data)的一种形式;也就是说,如果需要,可以通过再次运行批处理过程来重新创建数据集。我们看到了如何使用这个简单而强大的想法来建立搜索索引,推荐系统,做分析等等。
但是,批处理系统的局限性在于——输入的数据是有界的,所以批处理系统知道输入何时结束,这意味着批处理系统知道所有的输入。例如,MapReduce的排序操作必须读取其全部输入,然后才能开始进行处理。因为,可能发生这种情况——最后一条输入记录具有最小的键,因此需要第一个被输出,所以提早开始输出是不可行的。
实际上,很多数据是无界的。因为它随着时间的推移而逐渐到达——你的用户在昨天和今天产生了数据,明天他们将继续产生更多的数据。除非你停业,否则这个过程永远都不会结束,所以数据集从来就不会以任何有意义的方式“结束”。因此,批处理程序必须将数据人为地分成固定时间段的数据块,例如,在每天结束时处理一天的数据,或者在每小时结束时处理一小时的数据。
? 日常批处理中的问题是,输入的变更只会在一天之后的输出中反映出来,这对于许多急躁的用户来说太慢了。为了减少延迟,我们可以更频繁地运行处理 —— 比如说,在每秒钟的末尾 —— 或者甚至更连续一些,完全抛开固定的时间切片,当事件发生时就立即进行处理,这就是流处理(stream processing)背后的想法。
向消费者通知新事件的常用方式是使用消息传递系统(messaging system):生产者发送包含事件的消息,然后将消息推送给消费者。
? 一种广泛使用的替代方法是通过消息代理(message broker)(也称为消息队列(message queue))发送消息,消息代理实质上是一种针对处理消息流而优化的数据库。它作为服务器运行,生产者和消费者作为客户端连接到服务器。生产者将消息写入代理,消费者通过从代理那里读取来接收消息。
? 通过将数据集中在代理上,这些系统可以更容易地容忍来来去去的客户端(连接,断开连接和崩溃),而持久性问题则转移到代理的身上。一些消息代理只将消息保存在内存中,而另一些消息代理(取决于配置)将其写入磁盘,以便在代理崩溃的情况下不会丢失。针对缓慢的消费者,它们通常会允许无上限的排队(而不是丢弃消息或背压),尽管这种选择也可能取决于配置。
? 排队的结果是,消费者通常是异步(asynchronous)的:当生产者发送消息时,通常只会等待代理确认消息已经被缓存,而不等待消息被消费者处理。向消费者递送消息将发生在未来某个未定的时间点 —— 通常在几分之一秒之内,但有时当消息堆积时会显著延迟。
负载均衡(多消费者监听同一个Topic,每条数据只被一个Consumer消费):每条消息都被传递给消费者之一,所以处理该主题下消息的工作能被多个消费者共享。代理可以为消费者任意分配消息。当处理消息的代价高昂,希望能并行处理消息时,此模式非常有用(在AMQP中,可以通过让多个客户端从同一个队列中消费来实现负载均衡,而在JMS中则称之为共享订阅(shared subscription))。
扇出(多消费者监听同一个Topic,每条数据被所有Consumer消费):每条信息都被传递给所有消费者,所以处理该主题下消息的工作能被多个消费者共享。
两种方式可以组合使用,即——每条消息可以被多个Consumer Group分别消费(扇出),而在每个Consumer Group内部,每条消息只能被其中一个Consumer消费(负载均衡)。
手动提交Offset:? 消费随时可能会崩溃,所以有一种可能的情况是:代理向消费者递送消息,但消费者没有处理,或者在消费者崩溃之前只进行了部分处理。为了确保消息不会丢失,消息代理使用确认(acknowledgments):客户端必须显式告知代理消息处理完毕的时间,以便代理能将消息从队列中移除。
重试:如果与客户端的连接关闭,或者代理超出一段时间未收到确认,代理则认为消息没有被处理,因此它将消息再递送给另一个消费者。 (请注意可能发生这样的情况,消息实际上是处理完毕的,但确认在网络中丢失了。需要一种原子提交协议才能处理这种情况,正如在“实践中的分布式事务”中所讨论的那样)。
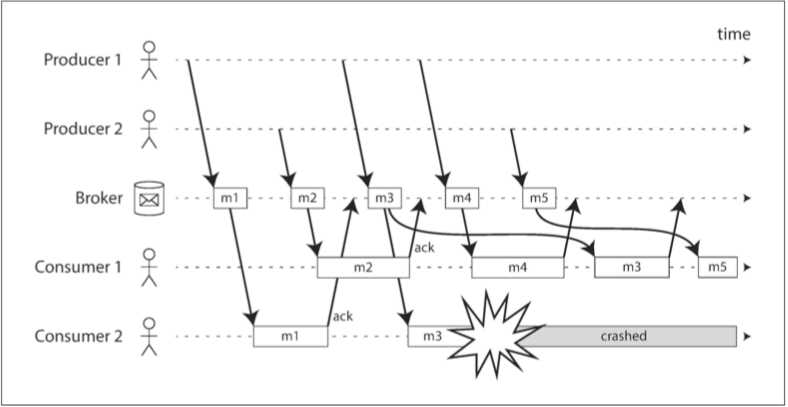
如图所示,? 当与负载均衡相结合时,这种重传行为对消息的顺序有种有趣的影响。在图中,消费者通常按照生产者发送的顺序处理消息。然而消费者2在处理消息m3时崩溃,与此同时消费者1正在处理消息m4。未确认的消息m3随后被重新发送给消费者1,结果消费者1按照m4,m3,m5的顺序处理消息。因此m3和m4的交付顺序与以生产者1的发送顺序不同。?
即使消息代理试图保留消息的顺序(如JMS和AMQP标准所要求的),负载均衡与重传的组合也不可避免地导致消息被重新排序。为避免此问题,你可以让每个消费者使用单独的队列(即不使用负载均衡功能)。如果消息是完全独立的,则消息顺序重排并不是一个问题。但正如我们将在本章后续部分所述,如果消息之间存在因果依赖关系,这就是一个很重要的问题。
数据库和文件系统采用截然相反的方法论:至少在某人显式删除前,通常写入数据库或文件的所有内容都要被永久记录下来。
? 这种思维方式上的差异对创建衍生数据的方式有巨大影响。如第10章所述,批处理过程的一个关键特性是,你可以反复运行它们,试验处理步骤,不用担心损坏输入(因为输入是只读的)。而 AMQP/JMS风格的消息传递并非如此:收到消息是具有破坏性的,因为确认可能导致消息从代理中被删除,因此你不能期望再次运行同一个消费者能得到相同的结果。
? 如果你将新的消费者添加到消息系统,通常只能接收到消费者注册之后开始发送的消息。先前的任何消息都随风而逝,一去不复返。作为对比,你可以随时为文件和数据库添加新的客户端,且能读取任意久远的数据(只要应用没有显式覆盖或删除这些数据)。
? 为什么我们不能把它俩杂交一下,既有数据库的持久存储方式,又有消息传递的低延迟通知?这就是基于日志的消息代理(log-based message brokers) 背后的想法。
我们的目标是丢弃任何失败任务的部分输出,以便能安全地重试,而不会生效两次。分布式事务是实现这个目标的一种方式,而另一种方式是依赖幂等性(idempotence)【97】。
? 幂等操作是多次重复执行与单次执行效果相同的操作。例如,将键值存储中的某个键设置为某个特定值是幂等的(再次写入该值,只是用同样的值替代),而递增一个计数器不是幂等的(再次执行递增意味着该值递增两次)。
? 即使一个操作不是天生幂等的,往往可以通过一些额外的元数据做成幂等的。例如,在使用来自Kafka的消息时,每条消息都有一个持久的,单调递增的偏移量或唯一的标识。将值写入外部数据库时可以将这个偏移量或唯一标识带上,这样你就可以判断一条更新是不是已经执行过了,因而避免重复执行。
原文:https://www.cnblogs.com/ybonfire/p/12237296.html
{kind=link}