多数应用使用层层叠加的数据模型构建。对于每层数据模型的关键问题是:它是如何用低一层数据模型来表示的?例如:
一个复杂的应用程序可能会有更多的中间层次,不过基本思想仍然是一样的:每个层都通过提供一个明确的数据模型来隐藏更低层次中的复杂性。这些抽象允许不同的人群有效地协作(例如数据库厂商的工程师和使用数据库的应用程序开发人员)。
关系数据库起源于商业数据处理,在20世纪60年代和70年代用大型计算机来执行。从今天的角度来看,那些用例显得很平常:典型的事务处理(将销售或银行交易,航空公司预订,库存管理信息记录在库)和批处理(客户发票,工资单,报告)。
采用NoSQL数据库的背后有几个驱动因素,其中包括:
不同的应用程序有不同的需求,一个用例的最佳技术选择可能不同于另一个用例的最佳技术选择。因此,在可预见的未来,关系数据库似乎可能会继续与各种非关系数据库一起使用 - 这种想法有时也被称为混合持久化。
目前大多数应用程序开发都使用面向对象的编程语言来开发,这导致了对SQL数据模型的普遍批评:如果数据存储在关系表中,那么需要一个笨拙的转换层,处于应用程序代码中的对象和表,行,列的数据库模型之间。模型之间的不连贯有时被称为阻抗不匹配。
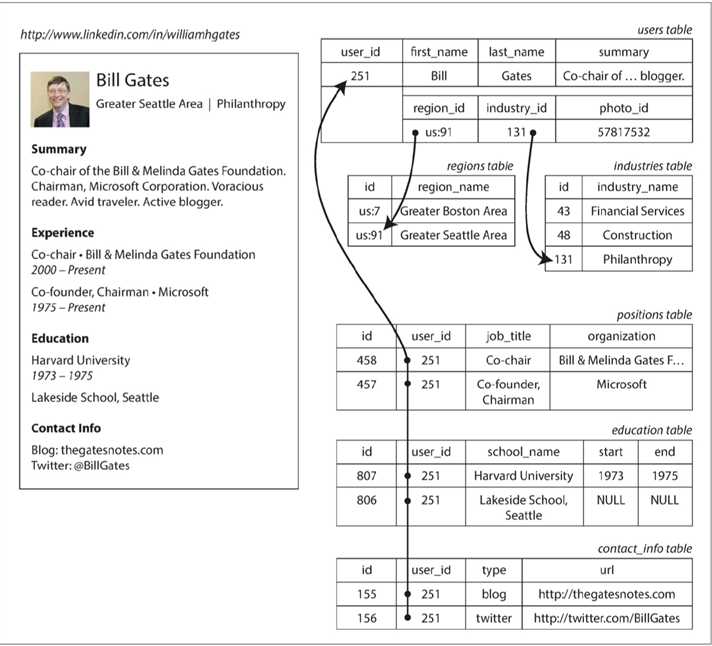
例如,上图展示了如何在关系模式中表示简历(一个LinkedIn简介)。整个简介可以通过一个唯一的标识符 user_id 来标识。像 first_name 和 last_name 这样的字段每个用户只出现一次,所以可以在User表上将其建模为列。但是,大多数人在职业生涯中拥有多于一份的工作,人们可能有不同样的教育阶段和任意数量的联系信息。从用户到这些项目之间存在一对多的关系,可以用多种方式来表示:
对于一个像简历这样自包含文档的数据结构而言,JSON表示是非常合适的。JSON比XML更简单。面向文档的数据库(如MongoDB ,RethinkDB ,CouchDB 和Espresso)支持这种数据模型。
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{
"job_title": "Co-chair",
"organization": "Bill & Melinda Gates Foundation"
},
{
"job_title": "Co-founder, Chairman",
"organization": "Microsoft"
}
],
"education": [
{
"school_name": "Harvard University",
"start": 1973,
"end": 1975
},
{
"school_name": "Lakeside School, Seattle",
"start": null,
"end": null
}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}JSON表示比图2-1中的多表模式具有更好的局部性(locality)。如果在前面的关系型示例中获取简介,那需要执行多个查询(通过 user_id 查询每个表),或者在User表与其下属表之间混乱地执行多路连接。而在JSON表示中,所有相关信息都在同一个地方,一个查询就足够了。
如果应用程序中的数据具有类似文档的结构(即,一对多关系树,通常一次性加载整个树),那么使用文档模型可能是一个好主意。将类似文档的结构分解成多个表(如图中的 positions , education 和 contact_info )的关系技术可能导致繁琐的模式和不必要的复杂的应用程序代码。
文档模型有一定的局限性:例如,不能直接引用文档中的嵌套的项目,而是需要说“用户251的位置列表中的第二项”(很像分层模型中的访问路径)。但是,只要文件嵌套不太深,这通常不是问题。
但是,如果你的应用程序确实使用多对多关系,那么文档模型就没有那么吸引人了。通过反规范化可以减少对连接的需求,但是应用程序代码需要做额外的工作来保持数据的一致性。通过向数据库发出多个请求,可以在应用程序代码中模拟连接,但是这也将复杂性转移到应用程序中,并且通常比由数据库内的专用代码执行的连接慢。在这种情况下,使用文档模型会导致更复杂的应用程序代码和更差的性能。
很难说在一般情况下哪个数据模型让应用程序代码更简单;它取决于数据项之间存在的关系种类。对于高度相联的数据,选用文档模型是糟糕的,选用关系模型是可接受的,而选用图形模型(参见“图数据模型”)是最自然的。
文档数据库有时称为无模式,但这具有误导性,因为读取数据的代码通常假定某种结构——即存在隐式模式,但不由数据库强制执行。一个更精确的术语是读时模式(数据的结构是隐含的,只有在数据被读取时才被解释),相应的是写时模式(传统的关系数据库方法中,模式明确,且数据库确保所有的数据都符合其模式)
在应用程序想要改变其数据格式的情况下,这些方法之间的区别尤其明显。例如,假设你把每个用户的全名存储在一个字段中,而现在想分别存储名字和姓氏。在文档数据库中,只需开始写入具有新字段的新文档,并在应用程序中使用代码来处理读取旧文档的情况。例如:
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
}另一方面,在“静态类型”数据库模式中,通常会执行以下迁移(migration)操作:
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL模式变更的速度很慢,而且要求停运。它的这种坏名誉并不是完全应得的:大多数关系数据库系统可在几毫秒内执行 ALTER TABLE 语句。MySQL是一个值得注意的例外,它执行 ALTERTABLE 时会复制整个表,这可能意味着在更改一个大型表时会花费几分钟甚至几个小时的停机时间,尽管存在各种工具来解决这个限制。
大型表上运行 UPDATE 语句在任何数据库上都可能会很慢,因为每一行都需要重写。要是不可接受的话,应用程序可以将 first_name 设置为默认值 NULL ,并在读取时再填充,就像使用文档数据库一样。
为处理多对多关系而兴起的数据模型
在属性图模型中,每个顶点(vertex)包括:
每条边(edge)包括:
可以将图存储看作由两个关系表组成:一个存储顶点,另一个存储边。头部和尾部顶点用来存储每条边;如果你想要一组顶点的输入或输出边,你可以分别通过 head_vertex 或 tail_vertex 来查询 edges 表。
CREATE TABLE vertices (
vertex_id INTEGER PRIMARY KEY,
properties JSON
);
CREATE TABLE edges (
edge_id INTEGER PRIMARY KEY,
tail_vertex INTEGER REFERENCES vertices (vertex_id),
head_vertex INTEGER REFERENCES vertices (vertex_id),
label TEXT,
properties JSON
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);关于这个模型的一些重要方面是:
三元组的主语相当于图中的一个顶点。而宾语是下面两者之一:
Cypher是属性图的声明式查询语言,为Neo4j图形数据库而发明。
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name原文:https://www.cnblogs.com/Ryan16231112/p/12240576.html