



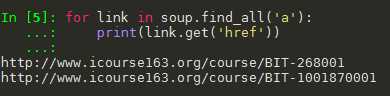
import requests from bs4 import BeautifulSoup r = requests.get("http://python123.io/ws/demo.html") demo = r.text print(demo, "\n") soup = BeautifulSoup(demo, "html.parser") for link in soup.find_all(‘a‘): print(link.get(‘href‘))
python爬虫笔记(五)网络爬虫之提取—信息组织与提取方法(2)信息提取的一般方法
原文:https://www.cnblogs.com/douzujun/p/12241099.html