词汇表示,目前为止一直都是用词汇表来表示词,上周提到的词汇表,可能是 10000 个单词,我们一直用 one-hot 向量来表示词。这种表示方法的一大缺点就是它把每个词孤立起来,这样使得算法对相关词的泛化能力不强。
换一种表示方式会更好,如果不用 one-hot 表示,而是用特征化的表示来表示每个词,man,woman,king,queen,apple,orange 或者词典里的任何一个单词,我们学习这些词的特征或者数值。

举个例子,对于这些词,比如想知道这些词与 Gender(性别)的关系。假定男性的性别为-1,女性的性别为+1,那么 man 的性别值可能就是-1,而 woman 就是-1。最终根据经验 king 就是-0.95,queen 是+0.97,apple 和 orange 没有性别可言。
我们假设有 300 个不同的特征,这样的话就有了这一列数字(上图编号 1 所示),这里只写了 4 个,实际上是 300 个数字,这样就组成 了一个 300 维的向量来表示 man 这个词。接下来,我想用\(??_{5391}\)这个符号来表示,就像这样(上图编号 2 所示)。同样这个 300 维的向量,我用\(??_{9853}\)代表这个 300 维的向量用来表示 woman 这个词(上图编号 3 所示),其他的例子也一样。
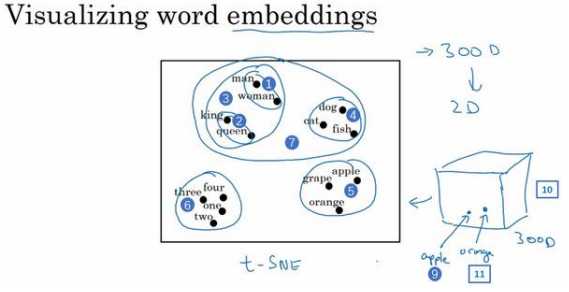
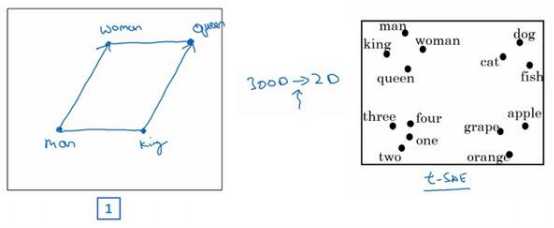
如果我们能够学习到一个 300 维的特征向量,或者说 300 维的词嵌入,通常可以把这 300 维的数据嵌入到一个二维空间里,这样就可以可视化了。常用的可视化算 法是 t-SNE 算法:
如果观察这种词嵌入的表示方法,会发现 man 和 woman 这些词聚集在一块(上图编号 1 所示),king 和 queen 聚集在一块(上图编号 2 所示),这些都是人,也都聚集在一起(上图编号 3 所示)。 动物都聚集在一起(上图编号 4 所示),水果也都聚集在一起(上图编号 5 所示),像 1、 2、3、4 这些数字也聚集在一起(上图编号 6 所示)。如果把这些生物看成一个整体,他们 也聚集在一起(上图编号 7 所示)。
这种词嵌入算法对于相近的概念,学到的特征也比较类似,在对这些概念可视化的时候,这些概念就比较相似,最终把它们映射为相似的特征向量。这种表示方式用的是在 300 维空间里的特征表示,这叫做嵌入(embeddings)。
之所以叫嵌入的原因是,可以想象一个 300 维的空间,这里用个 3 维的代替(上图编号 8 所 示)。现在取每一个单词比如 orange,它对应一个 3 维的特征向量,所以这个词就被嵌在这 个 300 维空间里的一个点上了(上图编号 9 所示),apple 这个词就被嵌在这个 300 维空间 的另一个点上了(上图编号 10 所示)。为了可视化,t-SNE 算法把这个空间映射到低维空间,可以画出一个 2 维图像然后观察,这就是这个术语嵌入的来源。
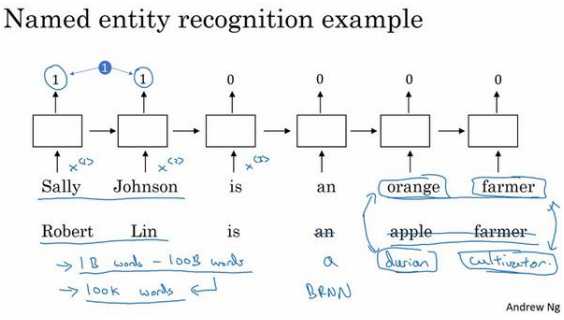
要是看到:“Robert Lin is a durian cultivator.”(Robert Lin 是一个榴莲培育家)怎么办?榴莲(durian)是一种比较稀罕的水果,这种水果在新加坡和其他一些国家流行。如果对于一个命名实体识别任务, 你只有一个很小的标记的训练集,你的训练集里甚至可能没有 durian(榴莲)或者 cultivator (培育家)这两个词。但是如果你有一个已经学好的词嵌入,它会告诉你 durian(榴莲)是 水果,就像 orange(橙子)一样,并且 cultivator(培育家),做培育工作的人其实跟 farmer (农民)差不多,那么你就有可能从你的训练集里的“an orange farmer”(种橙子的农民)归纳出“a durian cultivator”(榴莲培育家)也是一个人。
词嵌入能够达到这种效果,其中一个原因就是学习词嵌入的算法会考察非常大的文本集,可以考察很大的数据集可以是 1 亿个单词,甚至达到 100 亿也 都是合理的,大量的无标签的文本的训练集。接下来可以把这个词嵌入应用到你 的命名实体识别任务当中,尽管只有一个很小的训练集,也许训练集里有100,000个单词, 甚至更小,这就使得可以使用迁移学习,把你从互联网上免费获得的大量的无标签文本中学习到的知识,能够分辨 orange(橙子)、apple(苹果)和 durian(榴莲)都是水果的知识,把这些知识迁移到一个任务中,比如只有少量标记的训练数据集的命名实体识别任务中。

当任务的训练集相对较小时,词嵌入的作用最明显,所以它广泛用于 NLP 领域。
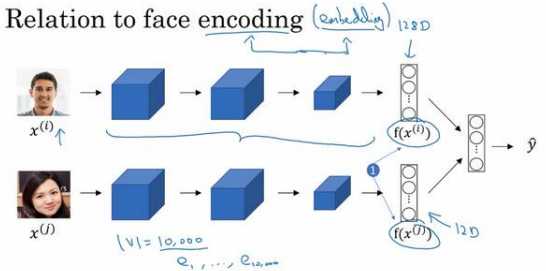
词嵌入和人脸编码之间有奇妙的关系:
训练的网络会学习不同人脸的一个 128 维表示,然后通过比较编码结果来判断两个图片是否是同一个人脸,这个词嵌入的意思和这个差不多。在人脸识别领域大家喜欢用编码这个词来指代这些向量\(,??(??^{(??)} ),??(??^{(??)} )\)(上图编号 1 所示),人脸识别领域和 这里的词嵌入有一个不同就是,在人脸识别中我们训练一个网络,任给一个人脸照片,甚至是没有见过的照片,神经网络都会计算出相应的一个编码结果。主要差别就是,人脸识别中的算法未来可能涉及到海量的人脸照片,而自然语言处理有一个固定的词汇表,而像一些没有出现过的单词我们就记为未知单词。
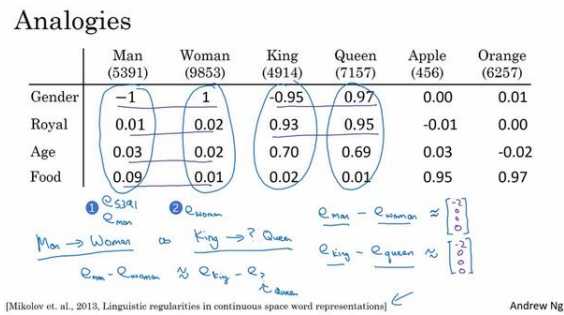
我们用一个四维向量来表示 man,我们用\(??_{5391}\)来表示,不过在这节视频中我们先把它 (上图编号 1 所示)称为\(??_{man}\),而旁边这个(上图编号 2 所示)表示 woman 的嵌入向量, 称它为\(??_{woman}\),对 king 和 queen 也是用一样的表示方法。在该例中,假设你用的是四维的嵌入向量,而不是比较典型的 50 到 1000 维的向量。这些向量有一个有趣的特性,就是假如你有向量\(??_{man}\)和\(??_{woman}\),将它们进行减法运算,即
\[
e_{man}-e_{woman}=\begin{bmatrix}-1\\0.01\\0.03\\0.09\end{bmatrix}-\begin{bmatrix}1\\0.02\\0.02\\0.01\end{bmatrix}=\begin{bmatrix}-2\\-0.01\\0.01\\0.08\end{bmatrix}\approx\begin{bmatrix}-2\\0\\0\\0\end{bmatrix}
\]
\[ ??_{king} ? ??_{queen} = \begin{bmatrix}?0.95\\0.93\\0.70\\0.02\end{bmatrix} ? \begin{bmatrix}0.97\\0.95\\0.69\\0.01\end{bmatrix} = \begin{bmatrix}?1.92\\?0.02\\0.01\\0.01\end{bmatrix} \approx \begin{bmatrix}?2\\0\\0\\0\end{bmatrix} \]
这个结果表示,man 和 woman 主要的差异是 gender(性别)上的差异,而 king 和 queen 之间的主要差异,根据向量的表示,也是 gender(性别)上的差异。
为了得出这样 的类比推理,计算当 man 对于 woman,那么 king 对于什么,你能做的就是找到单词 w 来 使得,\(??_{man} ? ??_{woman} ≈ ??_{king} ? ??_??\)这个等式成立,你需要的就是找到单词 w 来最大化\(与??_??与 ??_{king} ? ??_{man} + ??_{woman}\)的相似度,即
\[
???????? ???????? ??: ???????????? ??????(??_??, ??_{king} ? ??_{man} + ??_{woman})
\]
所以这里做的就是把这个\(??_??\)全部放到等式的一边,于是等式的另一边就会是\(??_{king} ???_{man} + ??_{woman}\)。我们有一些用于测算\(??_??\)和\(??_{king} ? ??_{man} + ??_{woman}\)之间的相似度的函数,然后通过方程找到一个使得相似度最大的单词,如果结果理想的话会得到单词 queen。值得注意 的是这种方法真的有效,如果你学习一些词嵌入,通过算法来找到使得相似度最大化的单词 w,你确实可以得到完全正确的答案。不过这取决于过程中的细节,如果你查看一些研究论 文就不难发现,通过这种方法来做类比推理准确率大概只有 30%~75%,只要算法猜中了单 词,就把该次计算视为正确,从而计算出准确率,在该例子中,算法选出了单词 queen。
在之前我们谈 到过用 t-SNE 算法来将单词可视化。t-SNE 算法所做的就是把这些 300 维的数据用一种非线 性的方式映射到 2 维平面上,可以得知 t-SNE 中这种映射很复杂而且很非线性。在进行 t-SNE 映射之后,你不能总是期望使等式成立的关系,会像左边那样成一个平行四边形,尽管在这 个例子最初的 300 维的空间内你可以依赖这种平行四边形的关系来找到使等式成立的一对 类比,通过 t-SNE 算法映射出的图像可能是正确的。但在大多数情况下,由于 t-SNE 的非线 性映射,你就没法再指望这种平行四边形了,很多这种平行四边形的类比关系在 t-SNE 映射 中都会失去原貌。
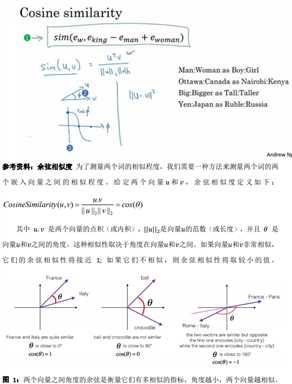
地列举一个最常用的相似度函数,这个最常用的相似度 函数叫做余弦相似度。这是我们上个幻灯片所得到的等式(下图编号 1 所示),在余弦相似 度中,假如在向量??和??之间定义相似度:\(sim(u,v)=\frac{u^Tv}{\lVert{u}\rVert_2\lVert{v}\rVert_2}\) 分子其实就是??和??的内积。如果 u 和 v 非常相似,那么它们的 内积将会很大,把整个式子叫做余弦相似度,其实就是因为该式是??和??的夹角的余弦值,所 以这个角(下图编号 2 所示)就是 Φ 角,这个公式实际就是计算两向量夹角 Φ 角的余弦。
Φ 角的余弦图像是这样的(下图编号 3 所示),所以夹角为 0 度 时,余弦相似度就是 1,当夹角是 90 度角时余弦相似度就是 0,当它们是 180 度时,图像完全跑到了相反的方向,这时相似度等于-1,这就是为什么余弦相似度对于这种类比工作能起 到非常好的效果。 距离用平方距离或者欧氏距离来表示:\(\lVert{?? ? ??}\rVert^2\)
词嵌入的一个显著成果就是,可学习的类比关系的一般性。举个例子,它能学会 man 对 于 woman 相当于 boy 对于 girl,因为 man 和 woman 之间和 king 和 queen 之间,还有 boy 和 girl 之间的向量差在 gender(性别)这一维都是一样的。它还能学习 Canada(加拿大) 的首都是 Ottawa(渥太华),而渥太华对于加拿大相当于 Nairobi(内罗毕)对于 Kenya(肯 尼亚),这些都是国家中首都城市名字。它还能学习 big 对于 bigger 相当于 tall 对于 taller, 还能学习 Yen(円)对于 Janpan(日本),円是日本的货币单位,相当于 Ruble(卢比)对 于 Russia(俄罗斯)。这些东西都能够学习,只要你在大型的文本语料库上实现一个词嵌入 学习算法,只要从足够大的语料库中进行学习,它就能自主地发现这些模式。
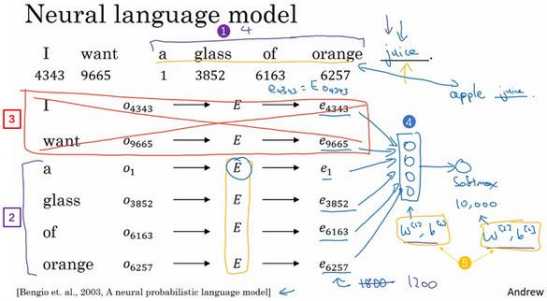
假设我们的词汇表含有 10,000 个单词,词汇表里有 a,aaron,orange, zulu,可能还有一个未知词标记。我们要做的就是学习一个嵌入矩阵??,它将是一个 300×10,000 的矩阵,如果你的词汇表里有 10,000 个,或者加上未知词就是 10,001 维。这个 矩阵的各列代表的是词汇表中 10,000 个不同的单词所代表的不同向量。假设 orange 的单词 编号是 6257(下图编号 1 所示),代表词汇表中第 6257 个单词,我们用符号\(??_{6527}\) 来表示 这个 one-hot 向量,这个向量除了第 6527 个位置上是 1(下图编号 2 所示),其余各处都为 0,显然它是一个 10,000 维的列向量,它只在一个位置上有 1,它不像图上画的那么短,它 的高度应该和左边的嵌入矩阵的宽度相等。
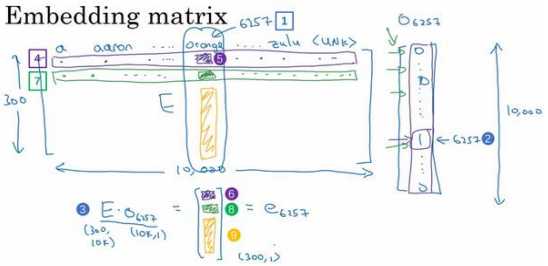
假设这个嵌入矩阵叫做矩阵??,注意如果用??去乘以右边的 one-hot 向量(上图编号 3 所 示),也就是\(??_{6527}\),那么就会得到一个 300 维的向量,??是 300×10,000 的,\(??_{6527}\)是 10,000×1 的,所以它们的积是 300×1 的,即 300 维的向量。就是单词 orange 下的这一列,它等于\(??_{6257}\),这个符号是我们用来表示这个 300×1 的嵌入向量的符号,它表示的单词是 orange。
更广泛来说,假如说有某个单词 w,那么\(??_??\)就代表单词 w 的嵌入向量。同样,\(????_??\),\(??_??\) 就是只有第??个位置是 1 的 one-hot 向量,得到的结果就是\(??_??\),它表示的是字典中单词 j 的嵌 入向量。
假如你在构建一个语言模型,并且用神经网络来实现这个模型。于是在训练过程中,你 可能想要你的神经网络能够做到比如输入:“I want a glass of orange ___.”,然后预测这句话 的下一个词。在每个单词下面,我都写上了这些单词对应词汇表中的索引。实践证明,建立 一个语言模型是学习词嵌入的好方法:
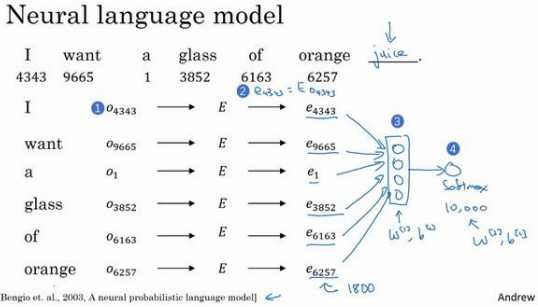
从第一个词 I 开始,建立一个 one-hot 向量表示这个单词 I。 这是一个 one-hot 向量(上图编号 1 所示),在第 4343 个位置是 1,它是一个 10,000 维的 向量。然后要做的就是生成一个参数矩阵??,然后用??乘以\(??_{4343}\),得到嵌入向量\(??_{4343}\),这一 步意味着\(??_{4343}\)是由矩阵??乘以 one-hot 向量得到的(上图编号 2 所示)。于是现在有许多 300 维的嵌入向量。我们能做的就是把它们全部放进神经网络中(上 图编号 3 所示),经过神经网络以后再通过 softmax 层(上图编号 4 所示),这个 softmax 也有自己的参数,然后这个 softmax 分类器会在 10,000 个可能的输出中预测结尾这个单词。这里有 6 个词,所以用 6×300,所以这个输入会是一个 1800 维的向 量,这是通过将这 6 个嵌入向量堆在一起得到的。
实际上更常见的是有一个固定的历史窗口,举个例子,你总是想预测给定四个单词(上 图编号 1 所示)后的下一个单词,注意这里的 4 是算法的超参数。这就是如何适应很长或者 很短的句子,方法就是总是只看前 4 个单词,所以说我只用这 4 个单词(上图编号 2 所示) 而不去看这几个词(上图编号 3 所示)。如果你一直使用一个 4 个词的历史窗口,这就意味 着你的神经网络会输入一个 1200 维的特征变量到这个层中(上图编号 4 所示),然后再通 过 softmax 来预测输出,选择有很多种,用一个固定的历史窗口就意味着你可以处理任意长 度的句子,因为输入的维度总是固定的。所以这个模型的参数就是矩阵??,对所有的单词用 的都是同一个矩阵??,而不是对应不同的位置上的不同单词用不同的矩阵。然后这些权重(上 图编号 5 所示)也都是算法的参数,你可以用反向传播来进行梯度下降来最大化训练集似 然,通过序列中给定的 4 个单词去重复地预测出语料库中下一个单词什么。
这就是早期最成功的学习词嵌入,算法预测出了某个单词 juice,我们 把它叫做目标词(下图编号 1 所示),它是通过一些上下文,在本例中也就是这前 4 个词 (下图编号 2 所示)推导出来的。如果你的目标是学习一个嵌入向量,研究人员已经尝试过 很多不同类型的上下文。
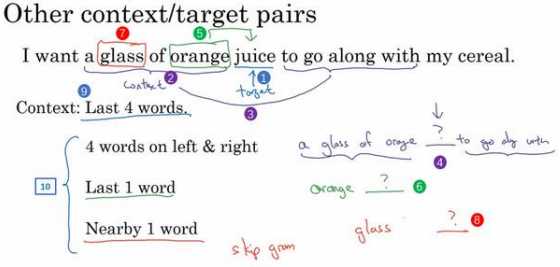
你可以把 目标词左右各 4 个词作为上下文(上图编号 3 所示)。这就意味着我们提出了一个这样的问 题,算法获得左边 4 个词,也就是 a glass of orange,还有右边四个词 to go along with,然后 要求预测出中间这个词(上图编号 4 所示)。提出这样一个问题,这个问题需要将左边的还 有右边这 4 个词的嵌入向量提供给神经网络,就像我们之前做的那样来预测中间的单词是 什么,来预测中间的目标词,这也可以用来学习词嵌入。
研究者发现,如果你真想建立一个语言模型,用目标词的前几个单词作为上下文是常见 做法(上图编号 9 所示)。但如果你的目标是学习词嵌入,那么你就可以用这些其他类型的 上下文(上图编号 10 所示),它们也能得到很好的词嵌入。
假设在训练集中给定了一个这样的句子:“I want a glass of orange juice to go along with my cereal.”,在 Skip-Gram 模型中,我们要做的是抽取上下文和目标词配对,来构造一个监 督学习问题。上下文不一定总是目标单词之前离得最近的四个单词,或最近的??个单词。我 们要的做的是随机选一个词作为上下文词,比如选 orange 这个词,然后我们要做的是随机 在一定词距内选另一个词,比如在上下文词前后 5 个词内或者前后 10 个词内,我们就在这 个范围内选择目标词。可能你正好选到了 juice 作为目标词,正好是下一个词(表示 orange 的下一个词),也有可能你选到了前面第二个词,所以另一种配对目标词可以是 glass,还可 能正好选到了单词 my 作为目标词。
于是我们将构造一个监督学习问题,它给定上下文词,要求你预测在这个词正负 10 个 词距或者正负 5 个词距内随机选择的某个目标词。显然,这不是个非常简单的学习问题,因 为在单词 orange 的正负 10 个词距之间,可能会有很多不同的单词。但是构造这个监督学习 问题的目标并不是想要解决这个监督学习问题本身,而是想要使用这个学习问题来学到一个 好的词嵌入模型。
我们要解决的基本的监督学习问题是学习一种映射关系,从上下 文 c,比如单词 orange,到某个目标词,记为 t,可能是单词 juice 或者单词 glass 或者单词 my。延续上一张幻灯片的例子,在我们的词汇表中,orange 是第 6257 个单词,juice 是 10,000 个单词中的第 4834 个,这就是你想要的映射到输出??的输入??。
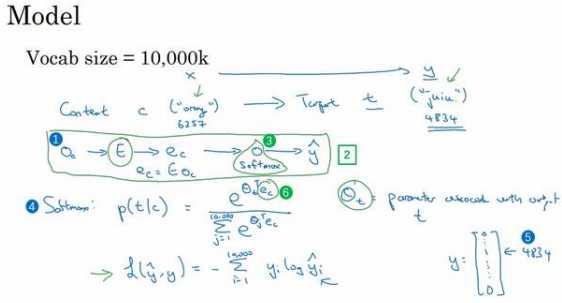
为了表示输入,比如单词 orange,你可以先从 one-hot 向量开始,我们将其写作\(??_??\),这 就是上下文词的 one-hot 向量(上图编号 1 所示)。可以拿嵌入矩阵??乘以向量\(??_??\),然后得到了输入的上下文词的嵌入向量,于是这里\(??_?? = ????_??\)。 在这个神经网络中(上图编号 2 所示),我们将把向量\(??_??\)喂入一个 softmax 单元。我通常把 softmax 单元画成神经网络中的一个节点(上图编号 3 所示),这不是字母 O,而是 softmax 单元,softmax 单元要做的就是输出\(\hat{y}\)。然后我们再写出模型的细节,这是 softmax 模型(上 图编号 4 所示),预测不同目标词的概率:
\[
Softmax::p(t|c)=\frac{e^{\theta^T_t}e_c}{\sum^{10000}_{j=1}e^{\theta^T_je_c}}
\]
这里\(??_??\)是一个与输出??有关的参数,即某个词??和标签相符的概率是多少。省略了 softmax 中的偏差项,想要加上的话也可以加上。
用??表示目标词,我们这里用的??和 \(\hat{y}\)都 是用 one-hot 表示的,于是损失函数就会是:
\[
L(\hat{y},y)=-\sum^{10000}_{i=1}y_ilog{\hat{y}_i}
\]
这是常用的 softmax 损失函数,?? 就是只有一个 1 其他都是 0 的 one-hot 向量,如果目标词是 juice,那么第 4834 个元素就是 1,其余是 0(上图编号 5 所示)。类似的 \(\hat{y}\) 是一个从 softmax 单元输出的 10,000 维的向量,这个向量是所有可能目标词的概率。
总结一下,这大体上就是一个可以找到词嵌入的简化模型和神经网络(上图编号 2 所 示),其实就是个 softmax 单元。矩阵??将会有很多参数,所以矩阵??有对应所有嵌入向量 \(??_??\) 的参数(上图编号 6 所示),softmax 单元也有\(??_??\)的参数(上图编号 3 所示)。如果优化这 个关于所有这些参数的损失函数,你就会得到一个较好的嵌入向量集,这个就叫做 Skip-Gram 模型。它把一个像 orange 这样的词作为输入,并预测这个输入词,从左数或从右数的某个 词,预测上下文词的前面一些或者后面一些是什么词。
实际上使用这个算法会遇到一些问题,首要的问题就是计算速度。尤其是在 softmax 模 型中,每次你想要计算这个概率,你需要对你词汇表中的所有 10,000 个词做求和计算,可 能 10,000 个词的情况还不算太差。如果你用了一个大小为 100,000 或 1,000,000 的词汇表, 那么这个分母的求和操作是相当慢的,实际上 10,000 已经是相当慢的了,所以扩大词汇表就更加困难了。

这里有一些解决方案,如分级(hierarchical)的 softmax 分类器和负采样(Negative Sampling)。
分级(hierarchical)的 softmax 分类器,意思就是 说不是一下子就确定到底是属于 10,000 类中的哪一类。它告诉你目标词是在词汇表的前 5000 个中还是在词汇表的后 5000 个词中,假 如这个二分类器告诉你这个词在前 5000 个词中(上图编号 2 所示),然后第二个分类器会 告诉你这个词在词汇表的前 2500 个词中,或者在词汇表的第二组 2500 个词中,诸如此类直到最终你找到一个词准确所在的分类器(上图编号 3 所示),那么就是这棵树的一个叶子 节点。实际上用这样的分类树,计算成本与词汇表大小的对数成正比(上图编号 4 所示),而不是 词汇表大小的线性函数,这个就叫做分级 softmax 分类器。
在实践中分级 softmax 分类器不会使用一棵完美平衡的分类树或者说一棵 左边和右边分支的词数相同的对称树(上图编号 1 所示的分类树)。实际上,分级的 softmax 分类器会被构造成常用词在顶部,然而不常用的词像 durian 会在树的更深处(上图编号 2 所 示的分类树),因为你想更常见的词会更频繁,所以你可能只需要少量检索就可以获得常用 单词像 the 和 of。然而你更少见到的词比如 durian 就更合适在树的较深处,因为你一般不 需要到那样的深处,所以有不同的经验法则可以帮助构造分类树形成分级 softmax 分类器。
怎么对上下文 c 进行采样:
一 旦你对上下文 c 进行采样,那么目标词 t 就会在上下文 c 的正负 10 个词距内进行采样。但 是你要如何选择上下文c?一种选择是你可以就对语料库均匀且随机地采样,如果你那么做,你会发现有一些词,像 the、of、a、and、to 诸如此类是出现得相当频繁的,于是你那么做 的话,你会发现你的上下文到目标词的映射会相当频繁地得到这些种类的词,但是其他词, 像 orange、apple 或 durian 就不会那么频繁地出现了。你可能不会想要你的训练集都是这些 出现得很频繁的词,因为这会导致你花大部分的力气来更新这些频繁出现的单词的\(??_??\)(上图 编号 1 所示),但你想要的是花时间来更新像 durian 这些更少出现的词的嵌入,即\(??_{durian}\)。 实际上词??(??)的分布并不是单纯的在训练集语料库上均匀且随机的采样得到的,而是采用了不同的分级来平衡更常见的词和不那么常见的词。
这就是 Word2Vec 的 Skip-Gram 模型,如果你读过我之前提到的论文原文,你会发现那 篇论文实际上有两个不同版本的 Word2Vec 模型,Skip-Gram 只是其中的一个,另一个叫做 CBOW,即连续词袋模型(Continuous Bag-Of-Words Model),它获得中间词两边的的上下 文,然后用周围的词去预测中间的词,这个模型也很有效,也有一些优点和缺点。
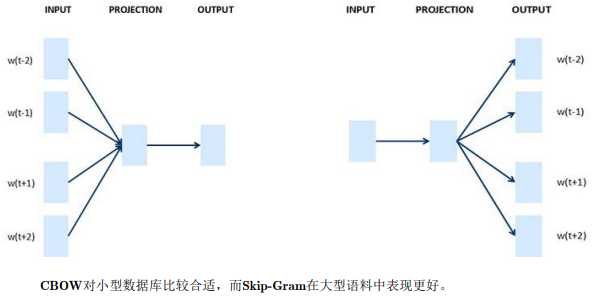
总结下:CBOW 是从原始语句推测目标字词;而 Skip-Gram 正好相反,是从目标字词推 测出原始语句。而刚才讲的 Skip-Gram 模型,关键问题在于 softmax 这个步骤的计算成本非 常昂贵,因为它需要在分母里对词汇表中所有词求和。通常情况下,Skip-Gram 模型用到更多点。
我们在这个算法中要做的是构造一个新的监督学习问题,那么问题就是给定一对单词, 比如 orange 和 juice,我们要去预测这是否是一对上下文词-目标词(context-target)。
我们要做的就是采样得到一个上下文词和一个目标词,在这个例子中就是 orange 和 juice,我们用 1 作为标记,我把中间这列(下图编号 1 所示)叫做词(word)。这样生成一个正样本,正样本跟上个视频中生成的方式一模一样,先抽取一个上下文词,在 一定词距内比如说正负 10 个词距内选一个目标词,这就是生成这个表的第一行,即 orange– juice -1 的过程。然后为了生成一个负样本,你将用相同的上下文词,再在字典中随机选一 个词,在这里我随机选了单词 king,标记为 0。
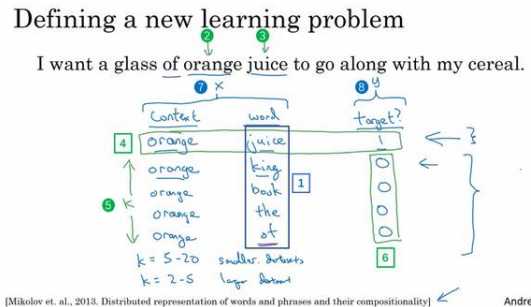
总结一下,生成这些数据的方式是我们选择一个上下文词(上图编号 2 所示),再选一 个目标词(上图编号 3 所示),这(上图编号 4 所示)就是表的第一行,它给了一个正样本, 上下文,目标词,并给定标签为 1。然后我们要做的是给定几次,比如??次(上图编号 5 所 示),我们将用相同的上下文词,再从字典中选取随机的词,king、book、the、of 等,从词 典中任意选取的词,并标记 0,这些就会成为负样本(上图编号 6 所示)。出现以下情况也 没关系,就是如果我们从字典中随机选到的词,正好出现在了词距内,比如说在上下文词 orange 正负 10 个词之内。
接下来我们将构造一个监督学习问题,其中学习算法输入??,输入这对词(上图编号 7 所示),要去预测目标的标签(上图编号 8 所示),即预测输出??。因此问题就是给定一对 词,像 orange 和 juice,你觉得它们会一起出现么?你觉得这两个词是通过对靠近的两个词 采样获得的吗?或者你觉得我是分别在文本和字典中随机选取得到的?这个算法就是要分 辨这两种不同的采样方式,这就是如何生成训练集的方法。
那么如何选取???Mikolov 等人推荐小数据集的话,??从 5 到 20 比较好。如果你的数据 集很大,??就选的小一点。对于更大的数据集??就等于 2 到 5,数据集越小??就越大。
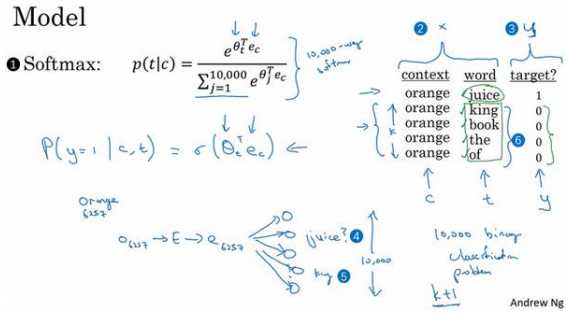
从??映射到??的监督学习模型,这(上图编号 1 所示:\() ??????????????: ??(??|??) = \frac{??^{??_??^??}??_?? }{\sum^{10000}_{j=1}??^{??_??^????_??}} )\)的 softmax 模型。这个(上图编号 2 所 示)将是新的输入??,这个(上图编号 3 所示)将是你要预测的值??。为了定义模型,我们将 使用记号??表示上下文词,记号??表示可能的目标词,我再用??表示 0 和 1,表示是否是一对 上下文-目标词。我们要做的就是定义一个逻辑回归模型,给定输入的??,??对的条件下,?? = 1的概率,即:
\[ ??(?? = 1|??,??) = ??(??_??^????_??) \]
我们把这个画成一个神经网络,如果输入词是 orange,即词 6257,你要做的就是输入 one-hot 向量,再传递给??,通过两者相乘获得嵌入向量\(??_{6257}\),你就得到了 10,000 个可能的 逻辑回归分类问题,其中一个(上图编号 4 所示)将会是用来判断目标词是否是 juice 的分 类器,还有其他的词,比如说可能下面的某个分类器(上图编号 5 所示)是用来预测 king 是 否是目标词,诸如此类,预测词汇表中这些可能的单词。把这些看作 10,000 个二分类逻辑 回归分类器,但并不是每次迭代都训练全部 10,000 个,我们只训练其中的 5 个,我们要训练对应真正目标词那一个分类器,再训练 4 个随机选取的负样本,这就是?? = 4的情况。所 以不使用一个巨大的 10,000 维度的 softmax,因为计算成本很高,而是把它转变为 10,000 个 二分类问题,每个都很容易计算,每次迭代我们要做的只是训练它们其中的 5 个,一般而言 就是?? + 1个,其中??个负样本和 1 个正样本。这也是为什么这个算法计算成本更低,因为 只需更新?? + 1个逻辑单元,?? + 1个二分类问题,相对而言每次迭代的成本比更新 10,000 维 的 softmax 分类器成本低。
这个算法有一个重要的细节就是如何选取负样本,即在选取了上下文词 orange 之后, 你如何对这些词进行采样生成负样本?一个办法是对中间的这些词进行采样,即候选的目标 词,你可以根据其在语料中的经验频率进行采样,就是通过词出现的频率对其进行采样。但 问题是这会导致你在 like、the、of、and 诸如此类的词上有很高的频率。另一个极端就是用 1 除以词汇表总词数,即\(\frac{ 1} {\lvert ?? \rvert}\),均匀且随机地抽取负样本,这对于英文单词的分布是非常没有代表性的。
论文的作者 Mikolov 等人根据经验,他们发现这个经验值的效果最好,它位 于这两个极端的采样方法之间,既不用经验频率,也就是实际观察到的英文文本的分布,也 不用均匀分布,他们采用以下方式:
\[
P(w_i)=\frac{f(w_i)^{\frac{3}{4}}}{\sum_{j=1}^{10000}f(w_j)^{\frac{3}{4}}}
\]
进行采样,所以如果\(??(??_??)\)是观测到的在语料库中的某个英文词的词频,通过\(\frac{3}{4}\) 次方的计 算,使其处于完全独立的分布和训练集的观测分布两个极端之间。我并不确定这是否有理论 证明,但是很多研究者现在使用这个方法,似乎也效果不错。
GloVe 代表用词表示的全局变量(global vectors for word representation)。在此之前, 我们曾通过挑选语料库中位置相近的两个词,列举出词对,即上下文和目标词,GloVe 算法做的就是使其关系开始明确化。假定\(??_{????}\)是单词??在单词??上下文中出现的次数,那么这里??和?? 就和??和??的功能一样,所以你可以认为\(??_{????}\)等同于\(??_{????}\)。根据 上下文和目标词的定义,你大概会得出\(??_{????}\)等于\(??_{????}\)这个结论。事实上,如果你将上下文和目 标词的范围定义为出现于左右各 10 词以内的话,那么就会有一种对称关系。如果你对上下 文的选择是,上下文总是目标词前一个单词的话,那么\(??_{????}\)和\(??_{????}\)就不会像这样对称了。不过 对于 GloVe 算法,我们可以定义上下文和目标词为任意两个位置相近的单词,假设是左右各 10 词的距离,那么\(??_{????}\)就是一个能够获取单词??和单词??出现位置相近时或是彼此接近的频率 的计数器。
GloVe 模型做的就是进行优化,我们将他们之间的差距进行最小化处理
\[
minimize \sum^{10000}_{i=1}\sum^{10000}_{j=1}f(X_{ij})(\theta^T_ie_j+b_i+b'_j-logX_{ij})^2
\]
其中\(??_??^?? ??_??\),想一下??和??与??和??的功能一样是告诉你这两个单词之间有多 少联系,??和??之间有多紧密,??和??之间联系程度如何,换句话说就是他们同时出现的频率是 多少,这是由这个\(??_{????}\)影响的。我们要做的是解决参数??和??的问题,然后准备用梯度 下降来最小化上面的公式,你只想要学习一些向量,这样他们的输出能够对这两个单词同时 出现的频率进行良好的预测。
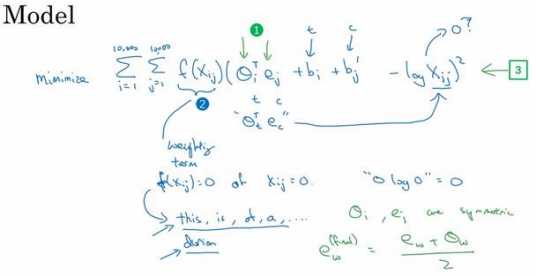
些附加的细节是如果\(??_{????}\)是等于 0 的话,那么??????0就是未定义的,是负无穷大的, 所以我们想要对\(??_{????}\)为 0 时进行求和,因此要做的就是添加一个额外的加权项\(??(??_{????})\)(上图编 号 2 所示)。如果\(??_{????}\)等于 0 的话,同时我们会用一个约定,即0??????0 = 0,这个的意思是如 果\(??_{????}\) = 0,先不要进行求和,所以这个??????0项就是不相关项。
\(??(??_{????})\)的另一个作用是,有 些词在英语里出现十分频繁,比如说 this,is,of,a 等等,有些情况,这叫做停止词,但是 在频繁词和不常用词之间也会有一个连续统(continuum)。不过也有一些不常用的词,比 如 durion,你还是想将其考虑在内,但又不像那些常用词这样频繁。因此,这个加权因子 \(??(??_{????})\)就可以是一个函数,即使是像 durion 这样不常用的词,它也能给予大量有意义的运 算,同时也能够给像 this,is,of,a 这样在英语里出现更频繁的词更大但不至于过分的权重。 因此有一些对加权函数??的选择有着启发性的原则,就是既不给这些词(this,is,of,a)过 分的权重,也不给这些不常用词(durion)太小的权值。
最后,一件有关这个算法有趣的事是??和??现在是完全对称的,所以那里的\(??_??\)和\(??_??\)就是对 称的。如果你只看数学式的话,他们(\(和??_??和??_??\))的功能其实很相近,你可以将它们颠倒或者 将它们进行排序,实际上他们都输出了最佳结果。因此一种训练算法的方法是一致地初始化 ??和??,然后使用梯度下降来最小化输出,当每个词都处理完之后取平均值,所以,给定一个 词??,你就会有\(??_??^{ (??????????) }= \frac{??_??+??_?? }{2}\) 。因为??和??在这个特定的公式里是对称的,而不像之前视频 里我们了解的模型,??和??功能不一样,因此也不能像那样取平均。
但是当你在使 用我们了解过的算法的一种来学习一个词嵌入时,例如我们之前的幻灯片里提到的 GloVe 算 法,会发生一件事就是你不能保证嵌入向量的独立组成部分是能够理解的:

假设说有个空间,里面的第一个轴(上图编号 1 所示)是 Gender,第二个轴(上图编 号 2 所示)是 Royal,你能够保证的是第一个嵌入向量对应的轴(上图编号 3 所示)是和这 个轴(上面提到的第一和第二基轴,编号 1,2 所示)有联系的,它的意思可能是 Gender、Royal、Age 和 Food。具体而言,这个学习算法会选择这个(上图编号 3 所示)作为第一维的轴,所以给定一些上下文词,第一维可能是这个轴(上图编号 3 所示),第二维也许是这 个(上图编号 4 所示),或者它可能不是正交的,它也可能是第二个非正交轴(上图编号 5 所示),它可以是你学习到的词嵌入中的第二部分。当我们看到这个(上图编号 6 所示)的 时候,如果有某个可逆矩阵??,那么这项(上图编号6所示)就可以简单地替换成\((????_?? )^?? (??^{???}??_??)\), 因为我们将其展开:
\[
(A\theta_i)^T(A^{-T}e_j)=\theta_i^TA^TA^{-T}e_j=\theta_i^Te_j
\]
一个简单证明过程。你 不能保证这些用来表示特征的轴能够等同于人类可能简单理解的轴,具体而言,第一个特征 可能是个 Gender、Roya、Age、Food Cost 和 Size 的组合,它也许是名词或是一个行为动词 和其他所有特征的组合,所以很难看出独立组成部分,即这个嵌入矩阵的单行部分,然后解 释出它的意思。尽管有这种类型的线性变换,这个平行四边形映射也说明了我们解决了这个 问题,当你在类比其他问题时,这个方法也是行得通的。因此尽管存在特征量潜在的任意线 性变换,你最终还是能学习出解决类似问题的平行四边形映射。

这是一个情感分类问题的一个例子(上图所示),输入??是一段文本,而输出??是你要预测的相应情感。
情感分类一个最大的挑战就是可能标记的训练集没有那么多。对于情感分类任务来说, 训练集大小从 10,000 到 100,000 个单词都很常见,甚至有时会小于 10,000 个单词,采用了词嵌入能够带来更好的效果,尤其是只有很小的训练集时。
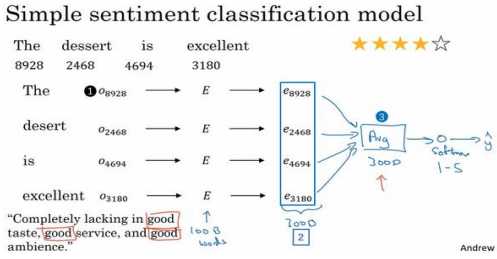
如果在很大的训练集上训练??,比如一百亿的单词,这样你就会获得很多知识,甚至从 有些不常用的词中获取,然后应用到你的问题上,即使你的标记数据集里没有这些词。我们 可以这样构建一个分类器,取这些向量(上图编号 2 所示),比如是 300 维度的向量。然后 把它们求和或者求平均,这里我画一个大点的平均值计算单元(上图编号 3 所示),你也可 以用求和或者平均。这个单元(上图编号 3 所示)会得到一个 300 维的特征向量,把这个特 征向量送进 softmax 分类器,然后输出\(\hat{y}\)。这个 softmax 能够输出 5 个可能结果的概率值, 从一星到五星,这个就是 5 个可能输出的 softmax 结果用来预测??的值。这个平均值运算效果不错。它 实际上会把所有单词的意思给平均起来,或者把你的例子中所有单词的意思加起来就可以用 了。
这个算法有一个问题就是没考虑词序,尤其是这样一个负面的评价,"Completely lacking in good taste, good service, and good ambiance.",但是 good 这个词出现了很多次,有 3 个 good,如果你用的算法跟这个一样,忽略词序,仅仅把所有单词的词嵌入加起来或者平均下 来,你最后的特征向量会有很多 good 的表示,你的分类器很可能认为这是一个好的评论, 尽管事实上这是一个差评,只有一星的评价。
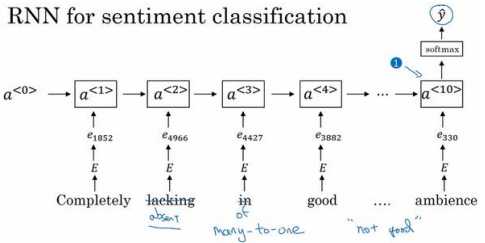
一个更加复杂的模型,不用简单的把所有的词嵌入都加起来,我们用一个 RNN 来做情感分类。
首先取这条评论,"Completely lacking in good taste, good service, and good ambiance.",找出每一个 one-hot 向量,这里我跳过去每一个 one-hot 向量的表示。 用每一个 one-hot 向量乘以词嵌入矩阵??,得到词嵌入表达??,然后把它们送进 RNN 里。RNN 的工作就是在最后一步(上图编号 1 所示)计算一个特征表示,用来预测\(\hat{y}\),这是一个多对 一的网络结构的例子。
如果你训练一个这样的算法,最后会得到一个很合适的情感分类的算法。由于你的词嵌 入是在一个更大的数据集里训练的,这样效果会更好,更好的泛化一些没有见过的新的单词。 比如其他人可能会说,"Completely absent of good taste, good service, and good ambiance.", 即使 absent 这个词不在标记的训练集里,如果是在一亿或者一百亿单词集里训练词嵌入, 它仍然可以正确判断,并且泛化的很好,甚至这些词是在训练集中用于训练词嵌入的,但是 可以不在专门用来做情感分类问题的标记的训练集中。

本节视频中当我使用术语 bias 时,我不是指 bias 本身这个词,或是偏见这种感觉,而 是指性别、种族、性取向方面的偏见,那是不同的偏见,同时这也通常用于机器学习的学术 讨论中。
一个已经完成学习的词嵌入可能会输出 Man:Computer Programmer, 同时输出 Woman:Homemaker,那个结果看起来是错的,并且它执行了一个十分不良的性 别歧视。如果算法输出的是 Man:Computer Programmer,同时 Woman:Computer Programmer 这样子会更合理。因此根据训练模型所使用的文本,词嵌入能够反映出性别、种族、年龄、性取向等其他 方面的偏见。尽量修改学习算法来尽可能减少或是理 想化消除这些非预期类型的偏见是十分重要的。至于词嵌入,它们能够轻易学会用来训练模型的文本中的偏见内容,所以算法获取到的 偏见内容就可以反映出人们写作中的偏见。有 许多研究许多难题需要完成来减少学习算法中这些类型的偏见。
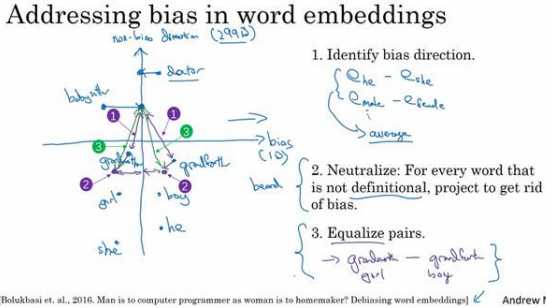
一、对于性别歧视这种情况来说,我们能做的是\(??_{he} ? ??_{she}\),因为它们的性别不同,然后 将\(??_{male} ? ??_{female}\),然后将这些值取平均,将这些差简单地求平均。这个 趋势看起来就是性别趋势或说是偏见趋势,然后这个趋势与我们想要尝试处理的特定偏见并不相关,因此这就是个无偏见趋势。在这种情况下,偏见趋势可以将它看做 1D 子空间,所以这个无偏见趋势就会是 299D 的子空间。
二、中和步骤,所以对于那些定义不确切的词可以将其处理一下,避免偏见。有些词本 质上就和性别有关,像 grandmother、grandfather、girl、boy、she、he,他们的定义中本就 含有性别的内容,不过也有一些词像 doctor 和 babysitter 我们想使之在性别方面是中立的。 同时在更通常的情况下,你可能会希望像 doctor 或 babysitter 这些词成为种族中立的,或是性取向中立的等等,不过这里我们仍然只用性别来举例说明。所以对于像 doctor 和 babysitter 这种单词我们就可以将它们在这个轴上进行处理,来减少或是消除他们 的性别歧视趋势的成分,也就是说减少他们在这个水平方向上的距离(上图在non-bias轴上的投影),所以这就是第二个中和步。
三、均衡步,意思是说你可能会有这样的词对,grandmother 和 grandfather,或者是 girl 和 boy,对于这些词嵌入,你只希望性别是其区别。在这个例子中, babysitter和grandmother之间的距离或者说是相似度实际上是小于babysitter和grandfather 之间的(上图编号 1 所示),因此这可能会加重不良状态,或者可能是非预期的偏见,也就 是说 grandmothers 相比于 grandfathers 最终更有可能输出 babysitting。所以在最后的均衡 步中,我们想要确保的是像 grandmother 和 grandfather 这样的词都能够有一致的相似度, 或者说是相等的距离,和 babysitter 或是 doctor 这样性别中立的词一样。这其中会有一些线 性代数的步骤,但它主要做的就是将 grandmother 和 grandfather 移至与中间轴线等距的一 对点上(上图编号 2 所示),现在性别歧视的影响也就是这两个词与 babysitter 的距离就完 全相同了(上图编号 3 所示)。
最后一个细节是你怎样才能够决定哪个词是中立的呢?
对于这个例子来说 doctor 看起 来像是一个应该对其中立的单词来使之性别不确定或是种族不确定。相反地,grandmother 和 grandfather 就不应是性别不确定的词。也会有一些像是 beard 词,一个统计学上的事实 是男性相比于比女性更有可能拥有胡子,因此也许 beard 应该比 female 更靠近 male 一些。
因此论文作者做的就是训练一个分类器来尝试解决哪些词是有明确定义的,哪些词是性 别确定的,哪些词不是。结果表明英语里大部分词在性别方面上是没有明确定义的,意思就 是说性别并是其定义的一部分,只有一小部分词像是 grandmother-grandfather,girl-boy, sorority-fraternity 等等,不是性别中立的。
如何对两个单词除偏,比如:"actress“(“女演员”)和“actor”(“演员”)。 均衡算法适 用于您可能希望仅通过性别属性不同的单词对。 举一个具体的例子,假设"actress“(“女演 员”)比“actor”(“演员”)更接近“保姆”。 通过将中和应用于"babysit"(“保姆”),我们可以 减少与保姆相关的性别刻板印象。 但是这仍然不能保证"actress“(“女演员”)和“actor”(“演 员”)与"babysit"(“保姆”)等距。 均衡算法可以解决这个问题。
均衡背后的关键思想是确保一对特定的单词与 49 维\(g_\perp\)距离相等 。均衡步骤还可以确 保两个均衡步骤现在与\(??_{????????????????????????}^{????????????????}\) 距离相同,或者用其他方法进行均衡。下图演示了均衡算法的工作原理:


原文:https://www.cnblogs.com/phoenixash/p/12246625.html