目录
@AutoWired的过程作为一个Java程序员,Spring框架的重要性不必多说,最近也是趁着春节假期在简单的在看Spring的源码,下面来说些Spring的DI是怎么实现的,注意本文主要是从我一个小白的角度理解,并未牵涉太深
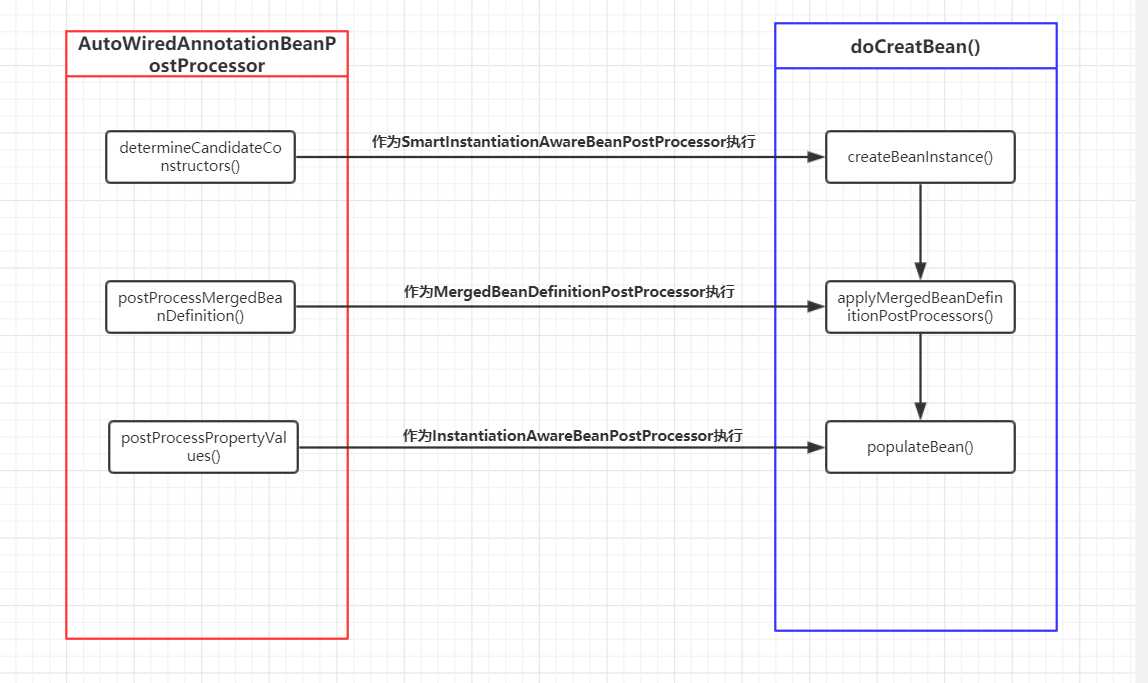
最初在查看Spring源码时,在容器第一次调用getBean()创建bean实例的时候,调用至在doCreateBean()中具体创建bean的伪代码逻辑大致如下
//根据反射创建bean实例
instanceWrapper = createBeanInstance(beanName, mbd, args);
//执行MergedBeanDefinitionPostProcessors后置处理器
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
//执行属性注入
populateBean(beanName, mbd, instanceWrapper);
//执行bean的初始化,在这方法里有beanPostProcessor的前后初始化方法执行
exposedObject = initializeBean(beanName, exposedObject, mbd);
// 如果bean实现了disposable,注册disposable看到这里在没有接触到AutoWiredAnnotationBeanPostProcessor之前,我一直以为populateBean()方法里会解析@Autowired注解的元信息,然后递归调用getBean()把所有的依赖的bean都加载然后利用反射注入
结果昨天看源码视频上了解到,解析@Autowired注解和依赖注入主要是靠后置处理器BeanPostProcessor的实现类AutoWiredAnnotationBeanPostProcessor来实现的,我当时后置处理器的理解仅仅停留在Bean的生命周期中前后初始化中调用
public interface BeanPostProcessor {
//Bean执行初始化方法之前执行
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
//Bean执行初始化方法之后执行
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
到了这里我就想不明白了,这个populateBean()和AutoWiredAnnotationBeanPostProcessor它俩之间到底是什么关系,究竟是在哪里注入的属性呢,深深的困惑开启了debug
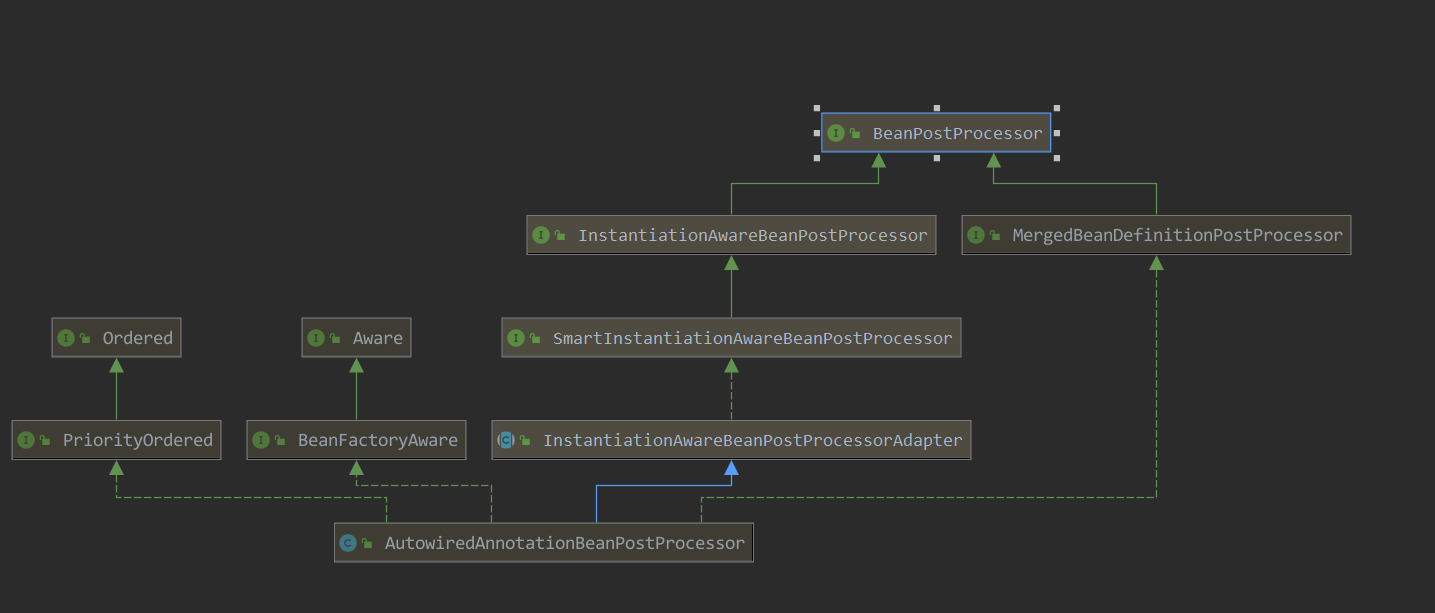
AutoWiredAnnotationBeanPostProcessor中探究首先去看了下AutoWiredAnnotationBeanPostProcessor,既然它是一个BeanPostProcessor,那么它的那两个初始化前后方法,postProcessBeforeInitialization() postProcessAfterInitialization()是代码是怎么写的呢,会不会是在这里进行的依赖注入呢?首先看下AutoWiredAnnotationBeanPostProcessor的继承图
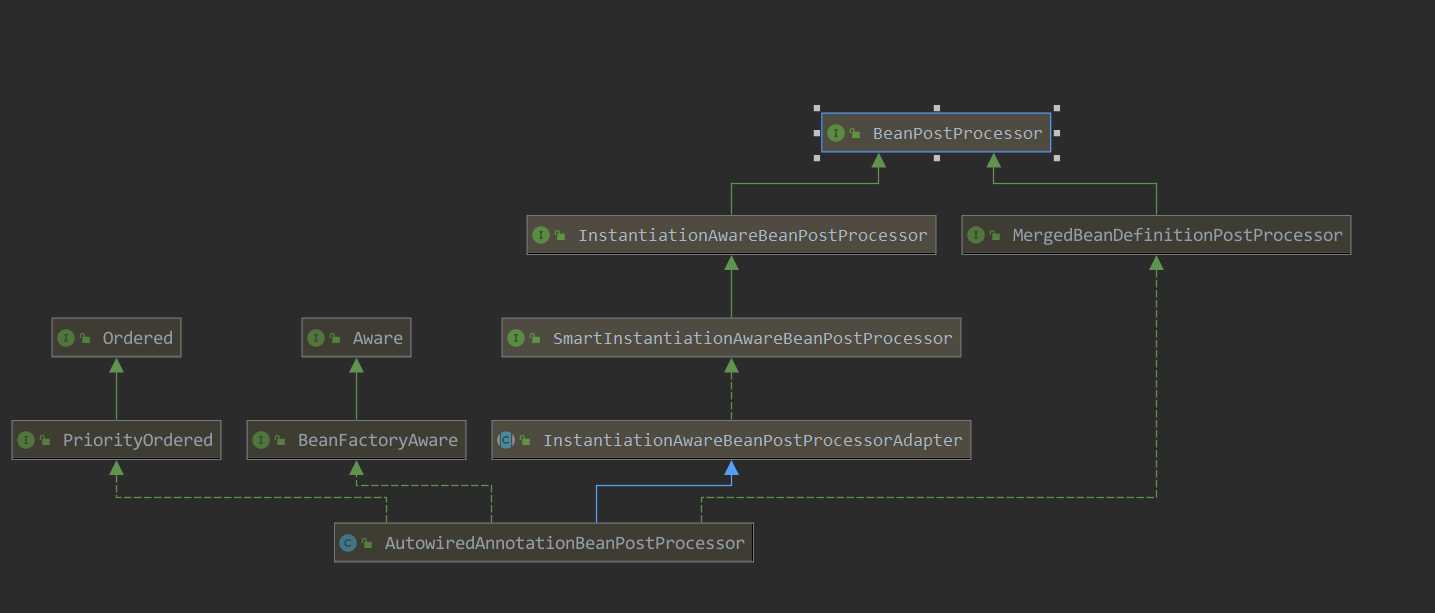
它的继承接口还算比较明了,顶层接口只有三个,Order和Aware这两个顶层接口可以先不管,排除掉,那么只剩下一个BeanPostProcessor,postProcessBeforeInitialization() 和postProcessAfterInitialization()两个方法的默认实现在InstantiationAwareBeanPostProcessorAdapter中,我们看一下它是怎么实现的
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}我了个去这个坑货,根本就啥都没实现好吗,直接就返回了bean,看到这里我是一脸懵逼,因为我对BeanPostProcessor的理解不够,最初我理解在bean的创建过程中后置处理器主要的增强功能都是在前面提到的doCreateBean()中的initializeBean()中去调用的,但是这里明显的啥都没做,那不管它了,从继承图上可以看到还有3个主要的接口
InstantiationAwareBeanPostProcessor 提供bean实例化之前和实例化之后但是属性注入之前的后置处理方法,定义了3个方法//在实例化之前调用,会返回一个期望暴露给容器的类而非类本身的实例(比如代理类)
Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException;
//在实例化之后但是spring执行属性注入之前调用,主要用来判断是否做自定义的属性注入
boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException;
//在注入此属性之前执行,能有验证、修改此属性,返回的属性是真正要注入的属性,即在属性注入前的一次修改机会
PropertyValues postProcessPropertyValues(PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeansException;
InstantiationAwareBeanPostProcessorAdapter 是抽象类,里面有一些默认实现,也先不管 SmartInstantiationAwareBeanPostProcessor 继承了InstantiationAwareBeanPostProcessor 这个主要是spring内部自己用的,增加了预测处理bean的最终类型//返回这个procressor最终得到的bean类型
Class<?> predictBeanType(Class<?> beanClass, String beanName) throws BeansException;
//明确bean会用到的候选构造器
Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, String beanName) throws BeansException;
//获得一个暴露bean的指向(bean并未完全创建完成),比如循环依赖中会用到
Object getEarlyBeanReference(Object bean, String beanName) throws BeansException;
MergedBeanDefinitionPostProcessor//在merged bean definition之后执行,可以用来准备一些元信息在处理bean实例之前
void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName);另外还有一个抽象类InstantiationAwareBeanPostProcessorAdapter,主要是SmartInstantiationAwareBeanPostProcessor 的默认实现,不会对容器bean默认实例化做任何操作,通常继承它的字类需要根据需求重写几个方法
到了这里对AutoWiredAnnotationBeanPostProcessor的分析也算是比较明了了,AutoWiredAnnotationBeanPostProcessor在InstantiationAwareBeanPostProcessorAdapter的基础上重写了determineCandidateConstructors()和postProcessPropertyValues()两个方法,另外还实现了从MergedBeanDefinitionPostProcessor接口继承来的postProcessMergedBeanDefinition()方法
[1580468875278](C:\Users\zheng\AppData\Roaming\Typora!
\1580468875278.png)
接下来只需要重点关注下这三个方法的实现和调用时机即可,在这三个方法打上断点,开始debug
准备了这么多终于开始进入正题,首先看下测试的场景,一个很基础的service中注入dao层
service类:
@Service
public class BookService {
//@Resource(name="bookDao2")
//@Inject
@Autowired
private BookDao bookDao;
@Override
public String toString() {
return "BookService [bookDao=" + bookDao + "]";
}
}dao类:
@Repository
public class BookDao {
private String lable = "1";
public String getLable() {
return lable;
}
public void setLable(String lable) {
this.lable = lable;
}
@Override
public String toString() {
return "BookDao [lable=" + lable + "]";
}
}测试类:
@Test
public void test01(){
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(MainConifgOfAutowired.class);
BookService bookService = applicationContext.getBean(BookService.class);
System.out.println(bookService);
BookDao bean = applicationContext.getBean(BookDao.class);
System.out.println(bean);
applicationContext.close();
}
开始debug!发现第一次进入的方法为determineCandidateConstructors(),前面解释过了它是确定候选的构造器
determineCandidateConstructors()做了什么?先看下调用栈,是谁什么什么时候调用的
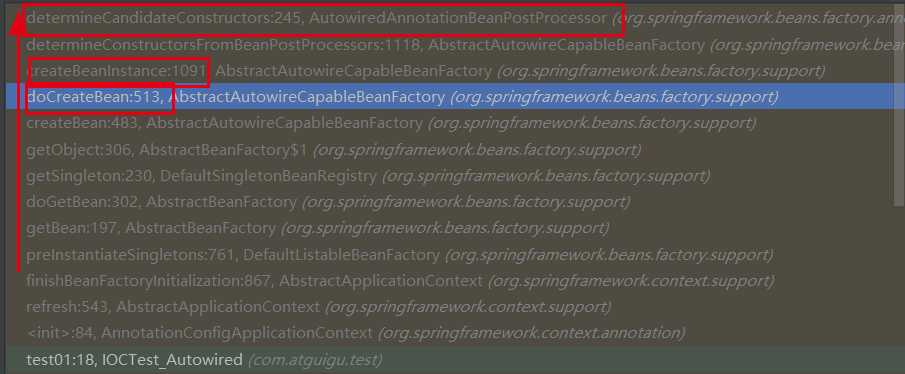
可以看到是在doCreateBean()方法中对createBeanInstance(beanName, mbd, args)的调用
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) {
//做了很多事情 省略....
// Need to determine the constructor...
//在这里调用了后置处理器,去查找构造器
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// No special handling: simply use no-arg constructor.
return instantiateBean(beanName, mbd);
}
//具体的后置处理器调用过程 SmartInstantiationAwareBeanPostProcessor
protected Constructor<?>[] determineConstructorsFromBeanPostProcessors(Class<?> beanClass, String beanName) throws BeansException {
if (beanClass != null && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
Constructor<?>[] ctors = ibp.determineCandidateConstructors(beanClass, beanName);
if (ctors != null) {
return ctors;
}
}
}
}
return null;
}注意调用时机,是在createBeanInstance(beanName, mbd, args)的调用中调用了SmartInstantiationAwareBeanPostProcessor的determineCandidateConstructors()方法
这里determineCandidateConstructors()方法的内部逻辑是怎么推断的这次不是本次研究的主题,考虑了很多种情况来获取构造器,本次debug情况返回了一个null,这里我们接着往下走
放行debug,接下来进入了postProcessMergedBeanDefinition()这个方法可以用来准备一些元数据方便后面类实例化的时候调用,这个方法是被谁,怎么调用的呢?
postProcessMergedBeanDefinition()做了什么?根据debug调用栈信息:
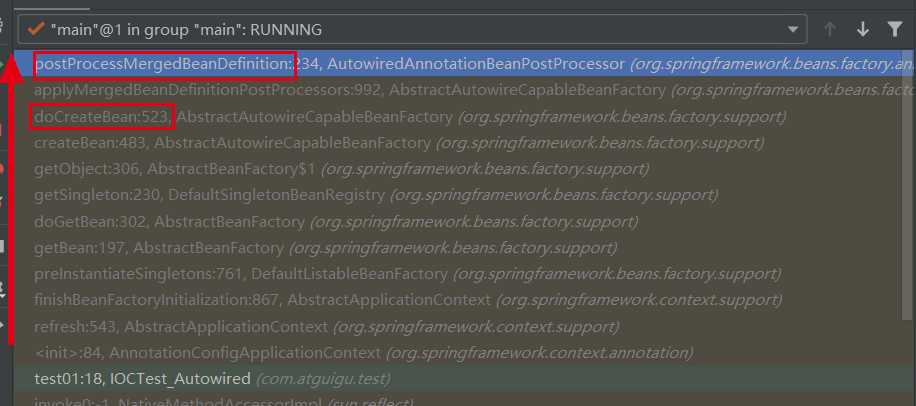
能够看到是在doCreateBean()的第523行,那么这行代码是什么呢?
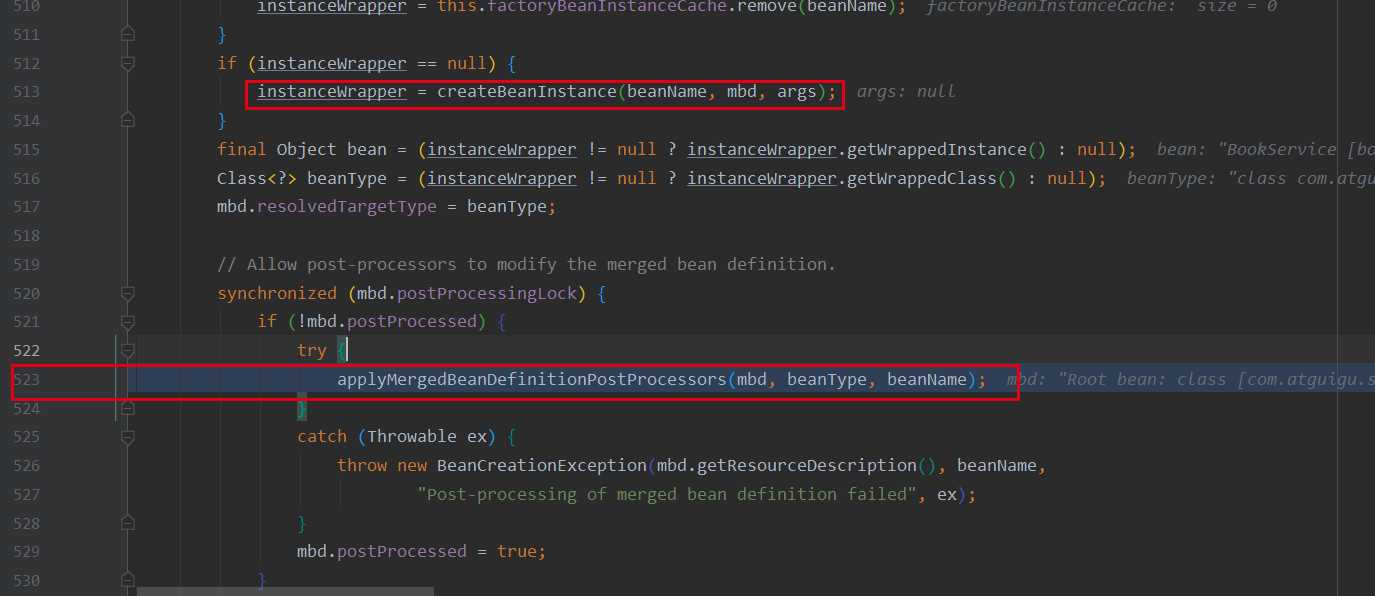

可以看到523行是执行applyMergedBeanDefinitionPostProcessors()方法,主要是调用后置处理器,注意调用时机是在createBeanInstance()之后,方法内部实现也很后置处理器化~ 都是统一的遍历调用,这里调用的是MergedBeanDefinitionPostProcessor的postProcessMergedBeanDefinition()
接下来研究下AutoWiredAnnotationBeanPostProcessor的postProcessMergedBeanDefinition()方法内部到底做了啥事情
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
if (beanType != null) {
//从方法名称上来看是查找自动注入元信息的数据
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}
} 进入findAutowiringMetadata()
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, PropertyValues pvs) {
// Fall back to class name as cache key, for backwards compatibility with custom callers.
String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());
// Quick check on the concurrent map first, with minimal locking.
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
try {
//从缓存中获取不到的话进入构建获取
metadata = buildAutowiringMetadata(clazz);
this.injectionMetadataCache.put(cacheKey, metadata);
}
catch (NoClassDefFoundError err) {
throw new IllegalStateException("Failed to introspect bean class [" + clazz.getName() +
"] for autowiring metadata: could not find class that it depends on", err);
}
}
}
}
return metadata;
}可以看到主要也是做了一层缓存,先从缓存中取,获取不到的话进入buildAutowiringMetadata(clazz),这里我抽取了部分代码
private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz) {
LinkedList<InjectionMetadata.InjectedElement> elements = new LinkedList<InjectionMetadata.InjectedElement>();
Class<?> targetClass = clazz;
do {
final LinkedList<InjectionMetadata.InjectedElement> currElements =
new LinkedList<InjectionMetadata.InjectedElement>();
//遍历类的每个属性,查看是否有AutowiredAnnotation的注解
ReflectionUtils.doWithLocalFields(targetClass, new ReflectionUtils.FieldCallback() {
@Override
public void doWith(Field field) throws IllegalArgumentException, IllegalAccessException {
AnnotationAttributes ann = findAutowiredAnnotation(field);
if (ann != null) {
if (Modifier.isStatic(field.getModifiers())) {
if (logger.isWarnEnabled()) {
logger.warn("Autowired annotation is not supported on static fields: " + field);
}
return;
}
//解析注解上的requied属性
boolean required = determineRequiredStatus(ann);
currElements.add(new AutowiredFieldElement(field, required));
}
}
});
.................................
return new InjectionMetadata(clazz, elements);
}看到这里算是明白了,原来这是利用反射遍历属性,对自动注入相关的注解进行解析(用到findAutowiredAnnotation(field)),并且推断required属性,最后将注解得到的信息包装成InjectionMetadata后返回出去
看一下findAutowiredAnnotation()方法
private AnnotationAttributes findAutowiredAnnotation(AccessibleObject ao) {
if (ao.getAnnotations().length > 0) {
//this.autowiredAnnotationTypes 是一个list<Annotation>,
//里面包括@Autowired @Inject @Value
for (Class<? extends Annotation> type : this.autowiredAnnotationTypes) {
AnnotationAttributes attributes = AnnotatedElementUtils.getMergedAnnotationAttributes(ao, type);
if (attributes != null) {
return attributes;
}
}
}
return null;
}如果当前属性上有这个注解,就把这个属性返回给上层
好的,回到postProcessMergedBeanDefinition()方法中,经过findAutowiringMetadata()拿到了InjectionMetadata可以拿到了,即注入相关注解的属性信息,接下来看一下checkConfigMembers()方法中做了什么
public void checkConfigMembers(RootBeanDefinition beanDefinition) {
Set<InjectedElement> checkedElements = new LinkedHashSet<InjectedElement>(this.injectedElements.size());
for (InjectedElement element : this.injectedElements) {
//member即要注入的类,在本次执行过程中即为bookDao
Member member = element.getMember();
if (!beanDefinition.isExternallyManagedConfigMember(member)) {
//主要是做了这一步
beanDefinition.registerExternallyManagedConfigMember(member);
checkedElements.add(element);
if (logger.isDebugEnabled()) {
logger.debug("Registered injected element on class [" + this.targetClass.getName() + "]: " + element);
}
}
}
this.checkedElements = checkedElements;
}也看不出来什么,进beanDefinition.registerExternallyManagedConfigMember(member)中看一下
public void registerExternallyManagedConfigMember(Member configMember) {
synchronized (this.postProcessingLock) {
if (this.externallyManagedConfigMembers == null) {
this.externallyManagedConfigMembers = new HashSet<Member>(1);
}
this.externallyManagedConfigMembers.add(configMember);
}
}主要是beanDefinition中一个属性setexternallyManagedConfigMembers保存下来需要注入的属性值
到这里postProcessMergedBeanDefinition()方法算是看完了,总结下
? 1.findAutowiringMetadata()遍历属性得到有依赖注解的属性元信息
? 2.checkConfigMembers()将得到的信息保存在beanDefinition中
这样看下来,AutoWiredAnnotationBeanPostProcessor的postProcessMergedBeanDefinition()挺符合它的接口定义,往beanDefinition中准备了需要依赖的属性信息,方便后期bean的处理
放行dubug,进入了AutoWiredAnnotationBeanPostProcessor的第二个方法postProcessPropertyValues()
postProcessPropertyValues()中做了什么?先不看这个方法具体做了啥,首先观察下debug调用栈,是谁在哪里调用的呢?
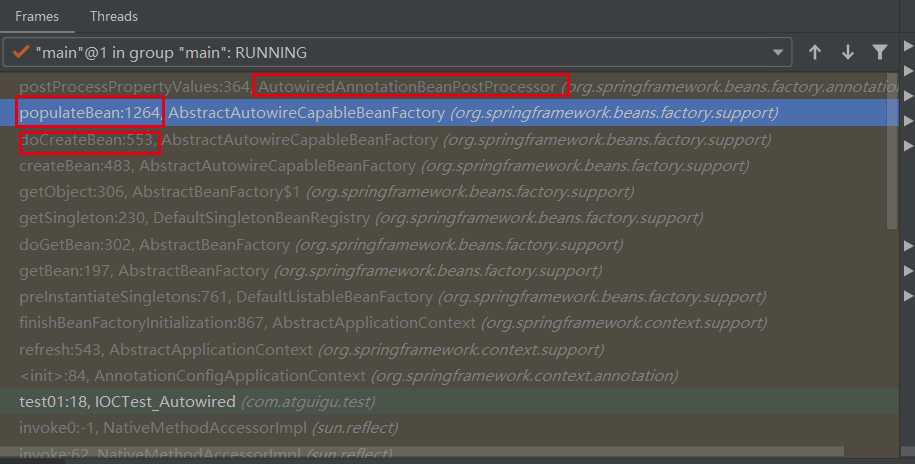
依旧是在doCreateBean()方法中,不过是在方法内部又调用了populateBean(),还记得我开头的那个疑问吗,populateBean()和AutoWiredAnnotationBeanPostProcessor它俩之间到底是什么关系?这里终于露出了端倪,populateBean()内部调用了AutoWiredAnnotationBeanPostProcessor的postProcessPropertyValues()方法,话不多说,快看下究竟是怎么执行的
摘取了populateBean()内具体调用的部分
protected void populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) {
PropertyValues pvs = mbd.getPropertyValues();
// 前面的N多方法省略 ....
//如期方法名,判断是否有InstantiationAwareBeanPostProcessors的后置处理器,本次这里为true
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
//是否需要依赖检查?本次这里为false
boolean needsDepCheck = (mbd.getDependencyCheck() != RootBeanDefinition.DEPENDENCY_CHECK_NONE);
if (hasInstAwareBpps || needsDepCheck) {
PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
if (hasInstAwareBpps) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
//重点来了!就是这里调用了postProcessPropertyValuesfang方法
pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvs == null) {
return;
}
}
}
}
if (needsDepCheck) {
checkDependencies(beanName, mbd, filteredPds, pvs);
}
}
applyPropertyValues(beanName, mbd, bw, pvs);
}可以看到populateBean()内部也是经过了后置处理器的处理,这里调用的是类型为InstantiationAwareBeanPostProcessor的postProcessPropertyValues()方法
接下来我们看AutoWiredAnnotationBeanPostProcessor的postProcessPropertyValues()方法里做了什么
public PropertyValues postProcessPropertyValues(
PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeanCreationException {
//第一步:
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
//第二步:
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
//返回
return pvs;
}整体也是十分的简洁,主要也是两步骤,接下来我们挨个进入
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, PropertyValues pvs) {
// Fall back to class name as cache key, for backwards compatibility with custom callers.
String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());
// Quick check on the concurrent map first, with minimal locking.
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
try {
metadata = buildAutowiringMetadata(clazz);
this.injectionMetadataCache.put(cacheKey, metadata);
}
catch (NoClassDefFoundError err) {
throw new IllegalStateException("Failed to introspect bean class [" + clazz.getName() +
"] for autowiring metadata: could not find class that it depends on", err);
}
}
}
}
return metadata;
}看起来是不是相对的眼熟,没错,之前postProcessMergedBeanDefinition()的第一步正是此方法,只不过之前缓存中没有需要查找,这里再调用的时候缓存injectionMetadataCache中已经存在,直接从缓存中换取到信息即可,
继续往下走调用metadata.inject(bean, beanName, pvs),
public void inject(Object target, String beanName, PropertyValues pvs) throws Throwable {
Collection<InjectedElement> elementsToIterate =
(this.checkedElements != null ? this.checkedElements :this.injectedElements);
if (!elementsToIterate.isEmpty()) {
boolean debug = logger.isDebugEnabled();
for (InjectedElement element : elementsToIterate) {
if (debug) {
logger.debug("Processing injected element of bean '" + beanName + "': " + element);
}
//主要再进调用
element.inject(target, beanName, pvs);
}
}这个方法内部没有做什么事情,主要是element.inject(target, beanName, pvs),再走
protected void inject(Object bean, String beanName, PropertyValues pvs) throws Throwable {
Field field = (Field) this.member;
Object value;
if (this.cached) {
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
}
else {
//组装描述类
DependencyDescriptor desc = new DependencyDescriptor(field, this.required);
desc.setContainingClass(bean.getClass());
Set<String> autowiredBeanNames = new LinkedHashSet<String>(1);
TypeConverter typeConverter = beanFactory.getTypeConverter();
try {
//重点来了 去beanFactory中获取依赖的实例
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(null, beanName, new InjectionPoint(field), ex);
}
//省略一大部分代码 ...
if (value != null) {
//重点来了!!! 在这里利用反射注入了获取到的bean
ReflectionUtils.makeAccessible(field);
field.set(bean, value);
}
}整段代码算是十分的平整,去beanFactory中获取依赖bean的实例,然后利用反射执行了注入操作,如其方法名称inject(),就是这么突然的完成了注入操作,到这里注入操作就算结束了,不过我们可以研究下是怎么从beanFactory中获取依赖bean实例的
beanFactory对依赖bean的实例的获取接下来我们看下怎么获取依赖bean的实例的,进入beanFactory.resolveDependency(),方法内部进行了类型判断,然后进入了doResolveDependency()方法
public Object doResolveDependency(DependencyDescriptor descriptor, String beanName,
Set<String> autowiredBeanNames, TypeConverter typeConverter) throws BeansException {r
//省略好多代码 主要是用resolver做一些判断处理 ...
//比较有意思,当你依赖是个集合或者map时spring的处理
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
//大部分情况走这个方法,根据指定class类型获取所有的符合条件bean存放到map中
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
//如果map中存在多条数据,说明该class类型存在多个实例,需要进一步判断
if (matchingBeans.size() > 1) {
//根据规则获取最符合的那一个bean的name
//比如使用了@Primary、@Priority注解的bean优先被获取
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(type, matchingBeans);
}
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
return null;
}
}
//这时已经拿到了最终确定的bean
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
//返回依赖的bean实例
return (instanceCandidate instanceof Class ?
descriptor.resolveCandidate(autowiredBeanName, type, this) : instanceCandidate);
}
finally {
// 只是在threadLocal中判断了下,不清楚做什么用,暂步研究
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
其中 findAutowireCandidates()作了很多的判断获取,这里不分开解析了,大概的看一下
protected Map<String, Object> findAutowireCandidates(
String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
//获取所有的当前class的bean的名称数组
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result =new LinkedHashMap<String, Object>(candidateNames.length);
// 很多的判断 ...
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
//实际的添加候选类
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
// 很多的判断
return result;
}
private void addCandidateEntry(Map<String, Object> candidates, String candidateName,
DependencyDescriptor descriptor, Class<?> requiredType) {
if (descriptor instanceof MultiElementDescriptor || containsSingleton(candidateName)) {
//往map中存放结果
//descriptor.resolveCandidate(candidateName, requiredType, this) 实际获取bean
candidates.put(candidateName, descriptor.resolveCandidate(candidateName, requiredType, this));
}
else {
candidates.put(candidateName, getType(candidateName));
}
}
public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory)
throws BeansException {
//逃不了呀,从beanFactory中获取bean
return beanFactory.getBean(beanName, requiredType);
}
自此也算是搞清楚了依赖注入是怎么回事,简单总结下,主要是利用AutoWiredAnnotationBeanPostProcessor的后置方法,后置处理器BeanProcessor在spring中的重要性毋庸置疑,它也分几种类型,在bean创建过程中的不同阶段调用不同类型的后置处理器进行处理
原文:https://www.cnblogs.com/zhmlearn/p/12247073.html
{kind=link}