DStreams或离散流是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象。DStream中的每个RDD都包含来自特定间隔的数据,如下图所示:

在DStream上执行的任何操作都转换为对基础RDD的操作。举例来说, 在基础案例WordCount中,flatMap操作应用于LinesDStream中的每个RDD以生成DStrem的wordsRDD。如下图所示:
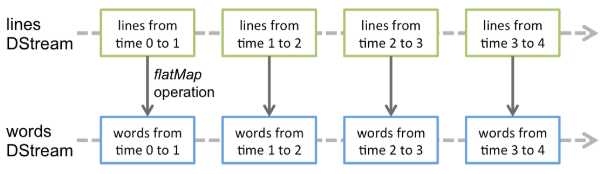
这些基础的RDD转换由Spark引擎计算。DStream操作隐藏了大多数的细节,并为开发人员提供了更高级别的API,以方便使用。
输入DStream是表示从流源接收的输入数据流的DStream。在https://www.cnblogs.com/yszd/p/10673277.html第三章的案例中,lines输入DStream代表从netcat服务器接收的数据流。每个输入DStream【文件流除外】都与一个Receiver对象关联,该对象从源接收数据并将其存储在Spark的内存中以进行处理。
1.基本来源
可直接在StreamingContext API中获得的来源。例如:文件系统和套接字连接。
2.高级来源
可以通过其他实用程序获得诸如Kafka、Flume、Kinesis等来源。它们需要针对额外的依赖项进行连接。
注意,要是在流应用程序中并行接收多个数据流,则可以创建多个输入DStream。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark工作程序/执行程序是一项长期运行的任务,它占用了分配给Spark Streaming应用程序的资源。因此,必须为Spark Streaming应用程序分配足够的内核【或者线程,若本地执行】,以处理接收到的数据并运行接收器。
1.在本地运行Spark Streaming程序时,请勿使用local或者local[1]作为主URL。这两种方式均意味着仅有一个线程用于本地运行任务。如果要基于接收器的输入DStream,则将使用单个线程来运行接收器,而不会留下任何线程来处理接收到的数据。因此,在本地运行时使用local[n]作为主URL,其中n>要运行的接收器数。
2.为了将逻辑扩展到在集群上运行,分配给Spark Streaming应用程序的内核数必须大于接收器数。
要从与HDFS API兼容的任何文件系统【即HDFS,S3,NFS等】上的文件中读取数据,可以通过:
StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
文件流不需要运行接收器,因此无需分配任何内核来接收文件数据。
对于简单的文本文件,最简单的方法是:
StreamingContext.textFileStream(dataDirectory)
Spark Streaming将监控目录dataDirectory并处理在该目录中创建的所有文件。
1.可以监控一个简单的目录,例如:hdfs://namenode:8040/logs/。发现后,将直接处理该路径下的所有文件。
2.模式匹配,例如:hdfs://namenode:8040/logs/2017/*。在此,DStream将包含与模式匹配的目录中的所有文件。匹配的是目录。
3.所有的文件必须使用相同的数据格式。
4.根据文件的修改时间而非创建时间,将其视为时间段的一部分。
5.处理后,在当前窗口中对文件的更改将不会导致重新读取该文件。也就是说,忽略更新。
6.目录下的文件越多,扫描更改所需的时间就越长,即使未修改任何文件。
7.如果使用通配符来标示目录,例如:http://namenode:8040/logs/2016_*,则重命名整个目录以匹配路径会将目录添加到受监控目录列表中。流中仅包含目录中修改时间在当前窗口内的文件。
8.调用FileSystem.setTimes()修复时间戳是一种在以后的窗口中拾取文件的方法,即使其内容没有更改。
HDFS之类的完整文件系统往往会在创建输出流后立即对其文件设置修改时间。当打开文件时,甚至在完全写入数据之前,该文件也可能不在DStream之中,将忽略同一窗口中对该文件的更新。也就是说,更改可能会丢失,流中将会忽略数据。为了确保在窗口中可以接收到更改,请将文件写入到一个不受监控的目录,然后关闭输出流后立即将其重命名为目标目录。如果重命名的文件在创建窗口期间显示在扫描的目标目录中,则将提取新数据。
相反,由于实际复制了数据,因此诸如Amazon S3和Azure存储之类的对象存储通常具有较慢的重命名操作。此外,重命名的对象可能具有将重命名时间作为其修改时间的功能,因此可能不被视为原始创建时间所暗示的窗口部分。需要对目标对象存储进行详细的测试,以验证存储的时间戳行为与Spark Streaming期望是否一致。直接写入目标目录可能是通过所选对象存储流传输数据的适当策略。
可以使用通过自定义接收器接收的数据流来创建DStream。
RDD队列作为流
为了使用测试数据测试Spark Streaming应用程序,还可以使用基于RDD队列创建DStream:
streamingContext.queueStream(queueOfRDDs
推送到队列中的每个RDD将被视为DStream中的一批数据,并像流一样进行处理。
原文:https://www.cnblogs.com/yszd/p/12246439.html