四、逻辑回归
逻辑回归是属于机器学习里面的监督学习,它是以回归的思想来解决分类问题的一种非常经典的二分类分类器。由于其训练后的参数有较强的可解释性,在诸多领域中,逻辑回归通常用作baseline模型,以方便后期更好的挖掘业务相关信息或提升模型性能。
1、逻辑回归思想
当一看到“回归”这两个字,可能会认为逻辑回归是一种解决回归问题的算法,然而逻辑回归是通过回归的思想来解决二分类问题的算法。
逻辑回归的基本思想:将样本所属正例的概率作为模型的输出,根据此概率值对样本的类别进行预测:
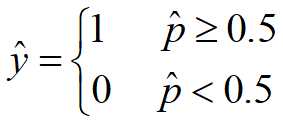
解释说明:逻辑回归是将样本特征和样本所属类别的概率联系在一起,假设现在已经训练好了一个逻辑回归的模型为 f(x) ,模型的输出是样本 x 的标签是 1 的概率,则该模型可以表示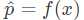 。若得到了样本 x 属于标签 1 的概率后,很自然的就能想到当
。若得到了样本 x 属于标签 1 的概率后,很自然的就能想到当 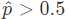 时 x 属于标签 1 ,否则属于标签 0 。所以就有:
时 x 属于标签 1 ,否则属于标签 0 。所以就有:
![]()
(其中 ?![]() 为样本 x 根据模型预测出的标签结果,标签 0 和标签 1 所代表的含义是根据业务决定的,比如在癌细胞识别中可以使 0 代表良性肿瘤, 1 代表恶性肿瘤)。
为样本 x 根据模型预测出的标签结果,标签 0 和标签 1 所代表的含义是根据业务决定的,比如在癌细胞识别中可以使 0 代表良性肿瘤, 1 代表恶性肿瘤)。
由于概率是 0 到 1 的实数,所以逻辑回归若只需要计算出样本所属标签的概率就是一种回归算法,若需要计算出样本所属标签,则就是一种二分类算法。
2、概率计算
那么逻辑回归中样本所属标签的概率怎样计算呢?
分析:
线性回归输出为的值域是(-∞,+∞)
概率的值域是(0,1)
关键:找到一个函数σ将线性回归得到的(-∞,+∞)的实数转换成(0,1)的概率值。
逻辑回归中样本所属标签的概率其实和线性回归有关系,学习了线性回归的同学肯定知道线性回归无非就是训练出一组参数![]() 和 b 来拟合样本数据,线性回归的输出为
和 b 来拟合样本数据,线性回归的输出为![]() 。不过
。不过![]()