开始学习爬虫,根据视频学习,由中国大学MOOC中北京理工大学 嵩天老师《Python网络爬虫与信息处理课程》
一.规则
能力:定向网络数据爬取和网页解析的基本能力。
每个单元20-40分钟讲解时间。总体时间并不是很长。



IDE介绍与讲解:
IDLE:特点:自带,默认,常用,入门。 有交互式和文件式两种方式。适用于入门,功能简单直接,代码300行以内的。
sublime text:特点:专为程序员开发的第三方专用编程工具,有专业编程体验,多种编程风格,工具非注册免费用,
Wing:特点:公司维护,收费,调试功能更丰富,版本控制与同步,适合多人开发。几千行代码开发。
VS+PTVS。微软提供win环境下的工具。
pycharm,社区版免费。适合复杂工程。
开始正式内容:
单元一:request库入门
一.Request库安装
1.cmd中输入pip install requests.等待安装成功,
遇到的问题:提示pip不是内部命令。解决方案:在用户环境变量的path中添加D:\Python\Scripts。
D:\Python\ 这是你的安装目录, \Scripts重点是这个后缀。而且注意是用户变量,不是系统变量,我是现在系统变量中添加,还是不能使用后又在用户变量中添加,然后可以运行,可以简单地输入pip验证是否成功。
2.打开idle,操作步骤如下。
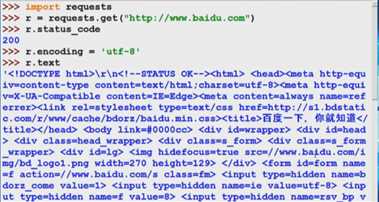
干货:

下面六个函数最后都是调用request函数,可以认为,request库只有一个函数就是request函数。
二.get方法
1.get函数
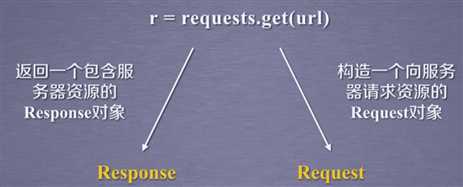
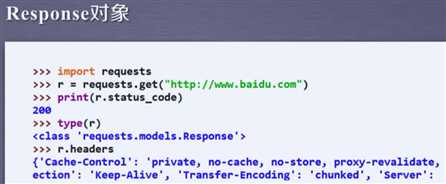
 这是很重要的属性。务必要牢记。
这是很重要的属性。务必要牢记。
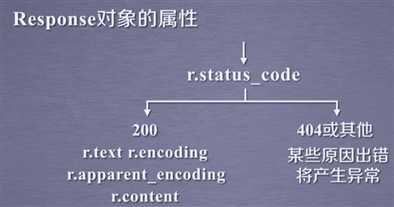

一般apparent_encoding更准确。
此部分小结:一般用r=request.get(url)就能获取页面全部信息,然后通过上面五个属性对它有更好的理解。
三.爬取网页的通用代码框架

框架:
raise_for_status检测status_code属性,不是200就返回错误,这个框架是为了访问页面更稳定更可靠。
四.HTTP协议与request库方法




两个图片对比看。方法对应,功能一致
HTTP用URL做定位,通过六个方法对资源进行管理。
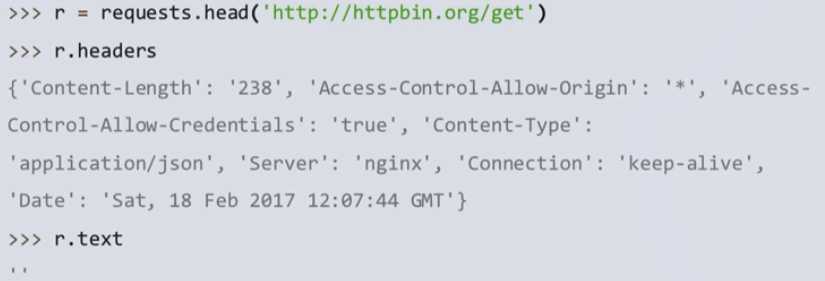
1.head方法可以用很少的网络流量获取页面的概括信息,text可能因为数据太多无法显示。
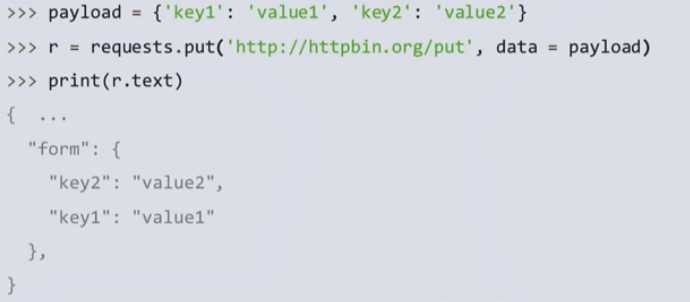
2.post方法,上传的数据会自动判断类型并放在对应存储区。


3.put方法与post方法不同在会把原来的数据覆盖掉。

五.request库主要方法解析

**kwargs讲解:
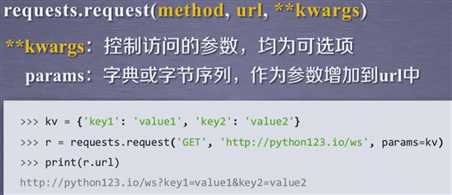
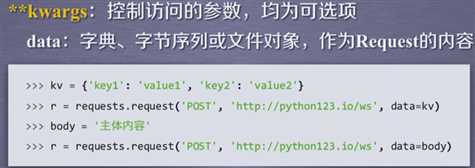

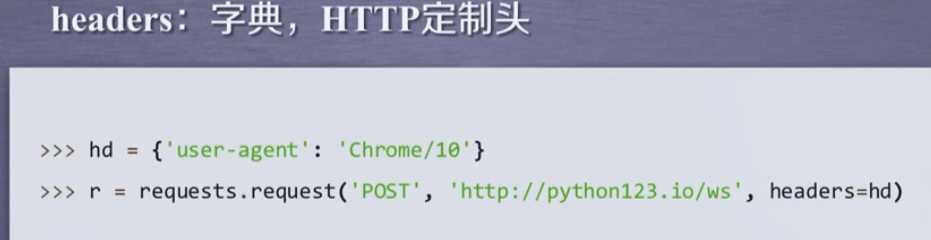
高级功能:
向连接提供某一个文件

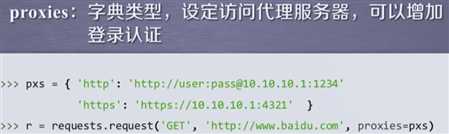 poxies可以设定代理服务器,隐藏源IP地址。
poxies可以设定代理服务器,隐藏源IP地址。
不具体讲解的高级参数
小结: 1.重点get与head的使用。
2.代码框架的使用,应对异常处理很重要。

1 importinrequests 2 importin函数time 3 4 defingethtmldata(url): 5 try: 6 r=requests.get(url) 7 r.raise_for_status() 8 r.encoding=r.apparent_encoding 9 return "success" 10 except: 11 return "fail" 12 url1="http://www.baidu.com" 13 14 if __name__ == "__main__": 15 start_time=time.perf_counter() 16 for i in range(10): 17 gethtmldata(url1) 18 end_time=time.perf_counter() 19 time_use=end_time-start_time 20 print("爬取的网站是{},所用时间为{}".format(url1,time_use),"s") 21 #爬取10次百度首页,遇到问题在print函数,点号打成逗号,造成语法错误, 22 #这段程序仿照mooc评论下的答案写成,任务要求是写出一段求多次爬取某个网站所用时间。 23 #之后想再加上进度条来展示进度
到此第一部分对request库了解完成,后续继续跟进老师教学进度进行学习。
原文:https://www.cnblogs.com/m-tech-l/p/12252002.html