BIO:默认,同步阻塞IO流, 每个获取的连接都需要创建一个新的处理线程,故需要100个处理线程,服务端还需要一个1个Accept线程来接受连接请求;所以当连接建立后,将这个连接的IO读写放到一个专门的处理线程,所以当建立100个连接时,通常会产生1个Accept线程 + 100个处理线程。
NIO: 同步非阻塞IO流, NIO通过事件来触发。
a.NIO有Selector,通过while循环检查或系统调用通知,检查多个channel的状态是否可读写,所以可以用1个线程管理多个channel。NIO在处理IO的读写时,当从网卡缓冲区读或写入缓冲区,这个过程是串行的,所以用太多线程处理IO事件其实也没什么意义,连接事件由于通常处理比较快,用1个线程去处理就可以。
b.IO事件呢,通常会采用cpu core数+1或cpu core数 * 2,这个的原因是IO线程通常除了从缓冲区读写外,还会做些比较轻量的例如解析协议头等,这些是可以并发的,为什么不只用1个线程处理,是因为当并发的IO事件非常多时,1个线程的效率不足以发挥出多core的CPU的能力,从而导致这个地方成为瓶颈,这种在分布式cache类型的场景里会比较明显,按照这个,也就更容易理解为什么在基于Netty等写程序时,不要在IO线程里直接做过多动作,而应该把这些动作转移到另外的线程池里去处理,就是为了能保持好IO事件能被高效处理。 从上面可以看出,对于大多数需要建立大量连接,但并发读写并不会同时的场景而言,NIO的优势是非常明显的。
LB 即LoadBlance(负载均衡,如nginx)
长连接建立后一般不会断开,也就是某个client会固定请求到某台server,随着扩容缩容、服务器上下线,会负载不均衡。####(不是很懂,先扔着) 5. 在基于Netty实现FrameDecoder时,下面两种代码的表现会有什么不同? 第一种的处理方式可以有效减少IO线程池和业务处理线程池的上下文切换,从而提高IO线程的处理效率。
####6. 用Executors.newCachedThreadPool创建的线程池,在运行的过程中有可能产生的风险是?
阿里规范不建议这么做, Executors.newCachedThreadPool()会一直创建大量线程直到OOM.
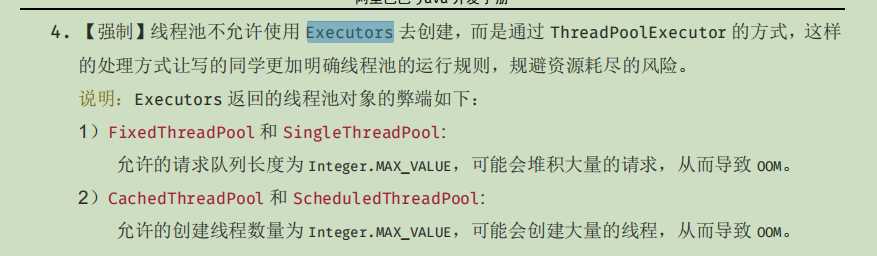
####7. new ThreadPoolExecutor(10,100,10,TimeUnit.MILLISECONDS,new LinkedBlockingQueue(10));一个这样创建的线程池,当已经有10个任务在运行时,第11个任务提交到此线程池执行的时候会发生什么,为什么? 此题考查ThreadPoolExecutor的workQueue [工作、阻塞队列]的简单用法, 所以应该第11个任务会加进队列中,而非开启第11个线程来处理。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
workQueue如下: 1) 同步阻塞队列:core-》max-》超出max后直接抛异常 , 2) 链表阻塞队列:先core-》队列-》max-》再抛异常,速度快点; 3)数组,有界; 4)延迟队列:用于定时任务 5)优先级..
####8. 实现一个自定义的ThreadFactory的作用通常是?
public class ThreadFactoryMain implements ThreadFactory{
private final String groupName;
private AtomicInteger nextId = new AtomicInteger(1);
public ThreadFactoryMain(String groupName) {
this.groupName = "ThreadFactoryMain -" + groupName + "-worker-";
}
@Override
public Thread newThread(@NotNull Runnable r) {
String threadName = groupName + nextId.incrementAndGet(); // 名称中添加一个自增的id
Thread thread = new Thread(null,r,threadName,0);
return thread;
}
}
———————————————
原文链接:https://blog.csdn.net/z69183787/article/details/91126481
考查JUC包, 也就是Java并发控制的常见机制
java的JUC包里的不管是BlockingQueue的实现,还是各种类似CountDownLatch、CyclicBarrier,都可以用来实现线程的交互。
CountDownLatch: 倒计数门闩,https://www.cnblogs.com/zhazhaacmer/p/11365805.html CyclicBarrier: 循环栅栏,维持最低的线程并发量 BlockingQueue: 阻塞队列,常见三类使用方式,阻塞式、超时式、查询完直接返回式对资源取拿 参考:https://blog.csdn.net/zhou920786312/article/details/100175698
####10. 为什么ConcurrentHashMap可以在高并发的情况下比HashMap更为高效? 分段式锁 参考:https://snailclimb.gitee.io/javaguide/#/docs/java/Multithread/%E5%B9%B6%E5%8F%91%E5%AE%B9%E5%99%A8%E6%80%BB%E7%BB%93?id=%e4%ba%8c-concurrenthashmap
####11. AtomicInteger、AtomicBoolean这些类之所以在高并发时高效,共同的原因是? CAS+volatile机制,例如AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。 参考:https://snailclimb.gitee.io/javaguide/#/docs/java/Multithread/Atomic?id=1-atomic-%e5%8e%9f%e5%ad%90%e7%b1%bb%e4%bb%8b%e7%bb%8d
####12. 请合理的使用Queue来实现一个高并发的生产/消费的场景,给些核心的代码片段。
例如通常可能会借助LinkedBlockingQueue来实现简单的生产/消费, 或者使用BlockingQueue阻塞队列来对ftp线程池的线程进行管理,频繁的存取和释放.
定时任务,QuartZ
或者使用JUC的CyclicBarrier: 循环栅栏,维持最低的线程并发量
ps -ef | grep java
jinfo -flags
jstat -gc pid 5000
jstat -gcutil [pid] [频率,例如多少毫秒一次] [多少次]
【刷面试题】阿里毕玄:来测试下你的Java编程能力 - 题解 01-15
原文:https://www.cnblogs.com/zhazhaacmer/p/12249964.html