今天学习了scala语言的一些基础知识,进行总结。
(1)声明值与变量
变量类型Scala解释器会自动解析,类型写不写都可以。
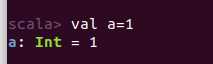
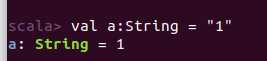
val变量:声明时必须初始化,之后不可改变(不可重新赋值)。
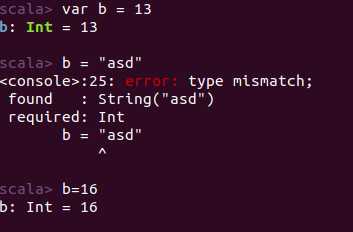
var变量:声明时可初始化,之后可以改变(重新赋值)。
(2)intersect函数:设A、B都为字符串变量,A.intersect(B)为字符串A与B相同部分。
例:

(3)运算符运算+、-、*、/、>、<
表达式a+b等价于表达式(a).+(b);
表达式a-b 等价于表达式(a).-(b);
a>b、a<b返回值为表达式真假(true或false);
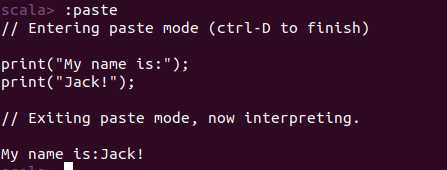
(4)多行输入统一运行方法:输入“:paste”进入多行输入模式,按键“Ctrl+D”退出多行输入模式。例如:
(5)读写文件
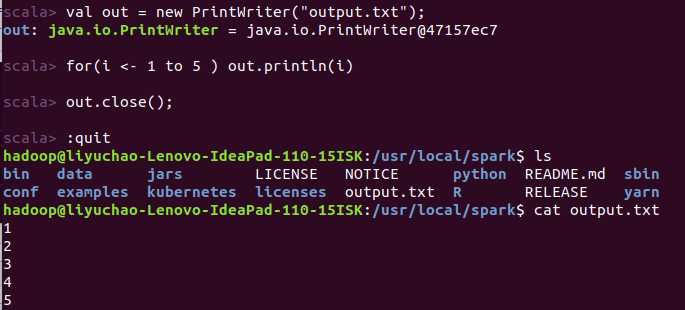
写入文件:
1 import java.io.PrintWriter; 2 val out = new PrintWrinter("output.txt")//output.txt为文件名,默认新建文档保存到进入spark前所处目录下。 3 //val out = new PrintWriter("path/output.txt")//path为指定路径,表示写入指定目录下的output.txt文档。 4 for(i <- 1 to 5)output(i) 5 out.close();//关闭输入流才可以查看到
读取文件:
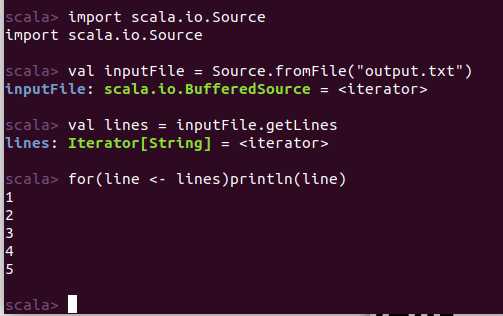
1 import scala.io.Source 2 val inputFile = Source.fromFile("output.txt")//建立输出流 3 val lines = inputFile.getLines//返回结果 4 for(line <- lines)println(line)//输出
(6)需要注意的是,在Scala中,对数组元素的应用,是使用圆括号,而不是方括号,也就是使用intValueArr(0),而不是intValueArr[0],这个和Java是不同的。
1 val myStrArr = new Array[String](3) //声明一个长度为3的字符串数组,每个数组元素初始化为null 2 myStrArr(0) = "BigData" 3 myStrArr(1) = "Hadoop" 4 myStrArr(2) = "Spark"
(7)列表的使用
注:列表中各个元素必须为同一类型
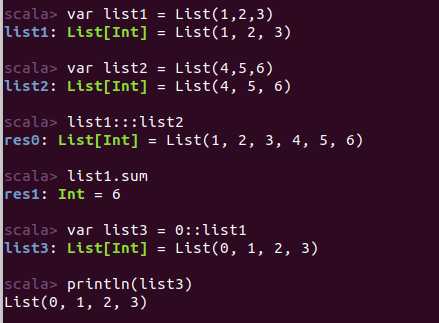
①声明列表:
1 var list1 =List(1,2,3)
②使用list.head来获取上面定义的列表的头部,list.tail获取列表的尾部。
③使用“::”在列表头部前添加新头部,如:0::list
④使用“:::”连接两个列表,如:list1:::list2
⑤使用list.sum可以求列表内数据的和(字符、字符串不可用)
示例:
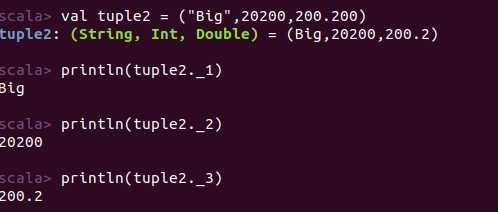
(8)元组的使用
注:元组内部各个元素可以为不同类型
定义与列表定义相同,但是可以存储不同类型元素。不可以使用“::”或“:::”
获取元组的某一元素格式为:“变量名._元素下标”(元素下标从1开始)
原文:https://www.cnblogs.com/liyuchao/p/12256522.html