
1 import numpy as np 2 from sklearn.cluster import KMeans 3 4 5 def loadData(filePath): 6 fr = open(filePath, ‘r+‘) 7 lines = fr.readlines() 8 retData = [] 9 retCityName = [] 10 for line in lines: 11 items = line.strip().split(",") 12 retCityName.append(items[0]) 13 retData.append([float(items[i]) for i in range(1, len(items))]) 14 return retData, retCityName 15 16 17 if __name__ == ‘__main__‘: 18 data, cityName = loadData(‘city.txt‘) 19 km = KMeans(n_clusters=4) 20 label = km.fit_predict(data) 21 expenses = np.sum(km.cluster_centers_, axis=1) 22 # print(expenses) 23 CityCluster = [[], [], [], []] 24 for i in range(len(cityName)): 25 CityCluster[label[i]].append(cityName[i]) 26 for i in range(len(CityCluster)): 27 print("Expenses:%.2f" % expenses[i]) 28 print(CityCluster[i])
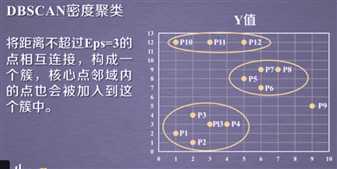
注:采用曼哈顿距离
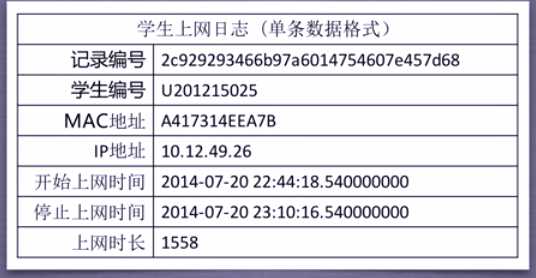
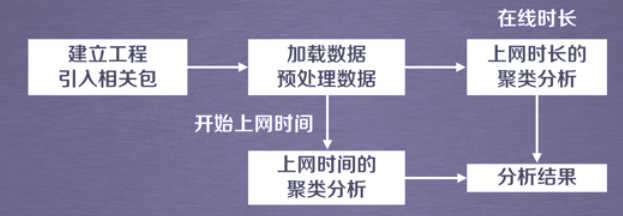

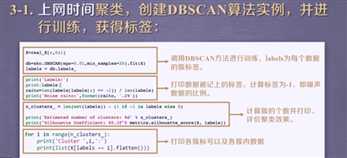

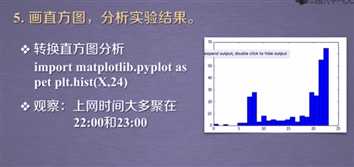


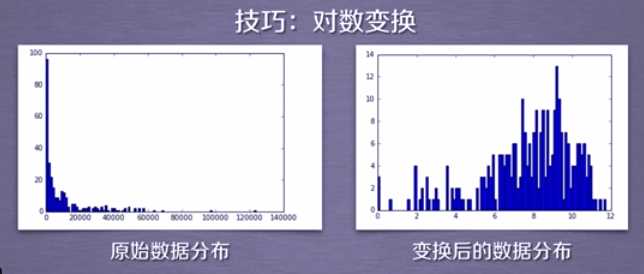
import numpy as np import sklearn.cluster as skc from sklearn import metrics import matplotlib.pyplot as plt mac2id = dict() onlinetimes = [] f = open(‘TestData.txt‘, encoding=‘utf-8‘) for line in f: mac = line.split(‘,‘)[2] onlinetime = int(line.split(‘,‘)[6]) starttime = int(line.split(‘,‘)[4].split(‘ ‘)[1].split(‘:‘)[0]) if mac not in mac2id: mac2id[mac] = len(onlinetimes) onlinetimes.append((starttime, onlinetime)) else: onlinetimes[mac2id[mac]] = [(starttime, onlinetime)] real_X = np.array(onlinetimes).reshape((-1, 2)) X = real_X[:, 0:1] db = skc.DBSCAN(eps=0.01, min_samples=20).fit(X) labels = db.labels_ print(‘Labels:‘) print(labels) raito = len(labels[labels[:] == -1]) / len(labels) print(‘Noise raito:‘, format(raito, ‘.2%‘)) n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) print(‘Estimated number of clusters: %d‘ % n_clusters_) print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels)) for i in range(n_clusters_): print(‘Cluster ‘, i, ‘:‘) print(list(X[labels == i].flatten())) plt.hist(X, 24)
原文:https://www.cnblogs.com/nishida-rin/p/12257473.html