一.准守网络爬虫的限制,合理爬取






无robots.TXT允许所有爬虫无限制爬取
![]()


二.京东页面爬取实例

爬取一个京东商品
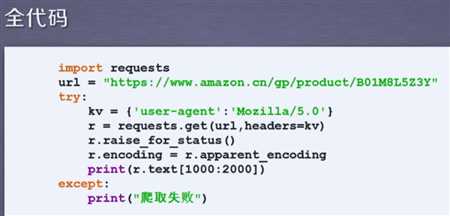
三.亚马逊实例

直接爬取是不可以的,因为有保护,把user_agent字段换成一个基本上通用的,mozilla/5.0可以认为是火狐,谷歌和ie10。
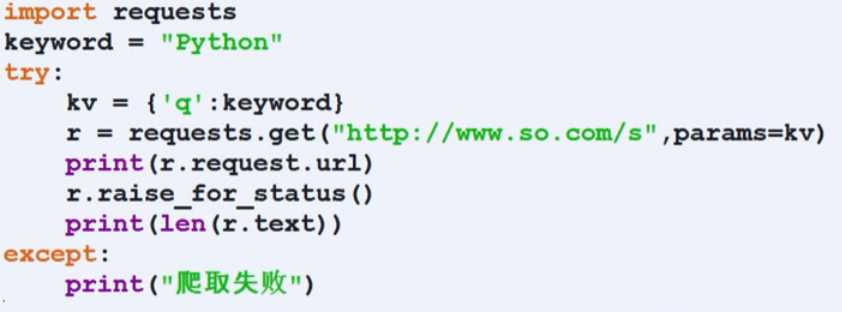
三.百度搜索关键词提交

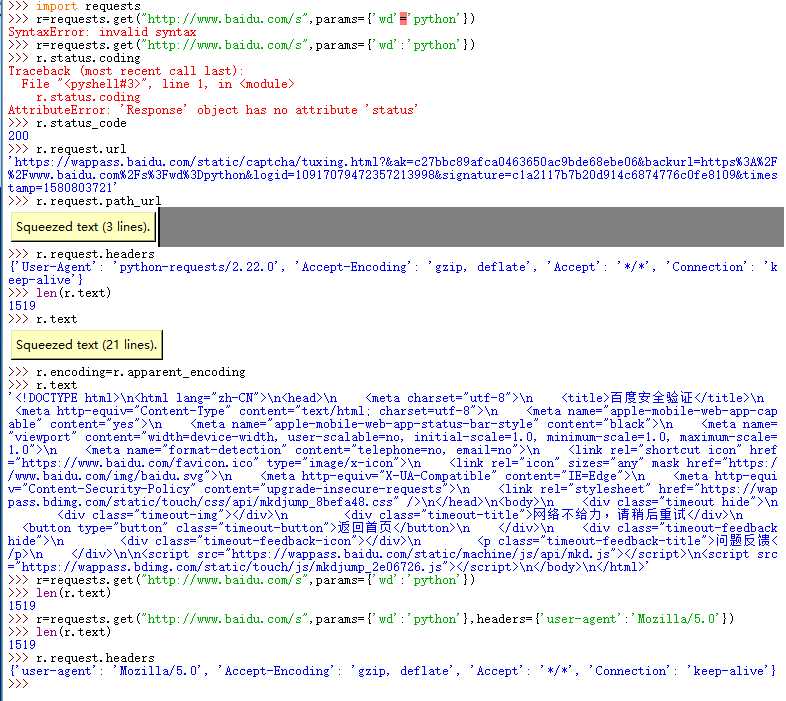
尝试失败,用浏览器能上去。1519单位是B。
后面学完之后回头看 这个样搜索也是可以的,主要是最后的URL是对的,不管怎么表示都是可以的。灵活处理即可
这个样搜索也是可以的,主要是最后的URL是对的,不管怎么表示都是可以的。灵活处理即可

360搜索好用,换成百度还是不行。其中 param参数用单引号或者双引号都行。
四.网络图片的爬取和存储


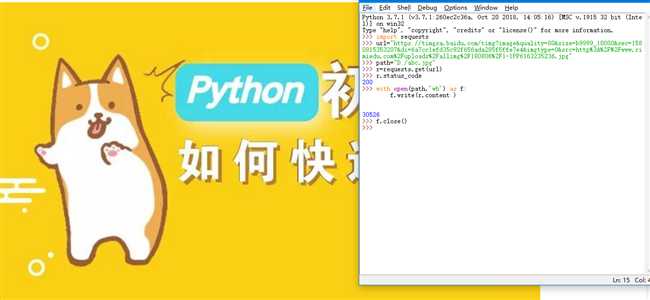
单独爬取一张照片成功。
加下来尝试执行文件的方式,
多次失败。。。。。
但是最后还是成功了。失败乃成功之母,失败促使进步。
问题出在path定义那里,注释掉的是按照视频的规则,用原名称来命名,但是看了眼我自己的URL后发现是因为按照这个规则截取的名字太鬼畜了,感觉不行,然后换成给定名称,然后就好使了。
贴上源码
1 import requests 2 import os 3 url="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1580815353207&di=6a7cc1efd35c92f656ada285f5ffe7e4&imgtype=0&src=http%3A%2F%2Fwww.rimiedu.com%2Fuploads%2Fallimg%2F180806%2F1-1PP6163235236.jpg" 4 root="G://20hanjiamooc//pachong//san//" 5 path=root+"AHA.jpg" 6 #path=root+url.split(‘/‘)[-1] 7 try: 8 if not os.path.exists(root): 9 os.mkdir(root) 10 if not os.path.exists(path): 11 12 try: 13 r=requests.get(url) 14 r.raise_for_status() 15 16 with open(path,‘wb‘) as f: 17 f.write(r.content) 18 f.close() 19 print("文件保存成功") 20 except: 21 print("网页获取失败") 22 else: 23 print("文件已存在") 24 except: 25 print("爬取失败")
五.IP地址归属地查询
www.ip138.com
![]()

text[:1000] text[-500:] text[1000:3000] 可以灵活获得内容的一部分。
六.小结:
1.网站提交都是URL连接,模仿连接就可实现爬取内容。
2.
原文:https://www.cnblogs.com/m-tech-l/p/12259693.html