基本信息:2014 nips 6500+
目标公式:$ p(y_t|v, y_1, . . . , y_{ t−1}) $
参数:$y_t$是生成的翻译文本,$v$是表达输入文本的定长向量
模型架构:用多层LSTM将输入序列$A,B,C,<EOS>$生成$v$ , 而后再利用另一个LSTM生成翻译文本。
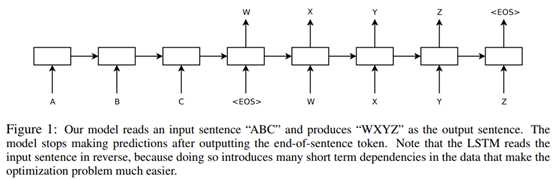
基本信息:2015 ICLR 6900+
提出问题:encoder-decoder模型,对于越长的文本翻译效果越差
解决方案:decoder时期的每个$h_j$都和encoder部分所有$h_i$得到加权值$α_i$,而后再$α_i$乘以对应的$h_i$求和,得到新表示的$c_i$。以上方法能够有重点的关注和解码部分最相关的部分。
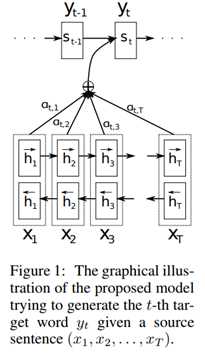
基本信息:2015 EMNLP 1800+
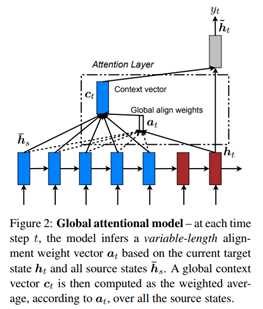
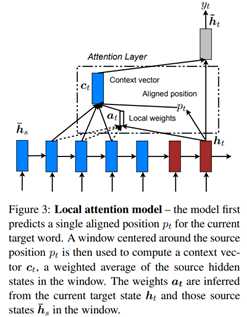
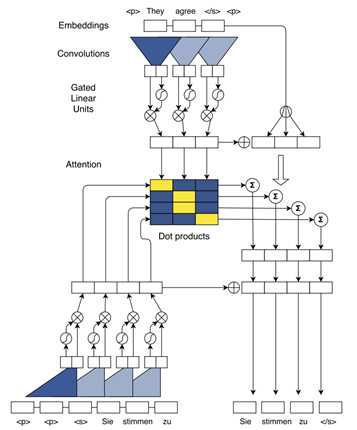
基本信息:2017 arXiv 600+
参考:https://www.cnblogs.com/AntonioSu/p/12019534.html
原文:https://www.cnblogs.com/AntonioSu/p/12263328.html