存储引擎:MyISAM、InnoDB、HEAP、BOB、ARCHIVE、CSV等。
MyISAM是非事务的存储引擎,适合用于频繁查询的应用。表锁,不会出现死锁。适合小并发。
Innodb是支持事务的存储引擎,适合于插入和更新操作比较多的应用。设计合理的话是行锁(最大区别就在锁的级别上),适合大并发。
| 存储引擎 | MyISAM | InnoDB |
| 事务处理 | 不支持 | 支持 |
| 数据行锁定 | 不支持,只有表锁定 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 表空间大小 | 相对小 | 相对大 |
| 全文索引 | 支持 | 不支持 |
| COUNT问题 | 无 | 执行COUNT(*)查询时,速度慢 |
Read Uncommitted(未提交读):在Read Uncommitted级别,事务的修改,即使没有提交,对其他事务也是可见的。事务可以读取其它事务未提交的数据,这也被称为脏读(Dirty Read)。这个级别会导致很多问题,从性能上说,Read Uncommitted不会比其他级别好太多,但缺乏其他级别的很多好处。除非真的有非常必要的理由,在实际应用中一般很少使用。
Read Committed(已提交读):大多数数据库的默认隔离级别都是Read Committed(但MySQL 不是)。Read Committed满足隔离性的简单定义:一个事务开始时,只能看见已经提交的事务所作的修改。换句话说,一个事务从开始直到提交之前,所作的任何修改对其它事务是不可见的。这个级别有时候也叫做不可重复读(Nonrepeatable Read),同一条数据可能有两个事务先后进行过操作,存在先后两次读取到的数据不一致(中间存在另一个事务提交的数据)的情况。执行两次同样的查询,得到的结果不一致。
Repeatable Read(可重复读,MySQL默认隔离级别):Repeatable Read解决了不可重复读的问题。该级别保证了在同一个事务中多次读取同样的记录的结果是一致的。但是理论上,可重复读隔离级别还是无法解决另外一个幻读问题。所谓幻读,指的是当某个事务在读取某个范围内的记录时,另一个事务又在这个范围内插入了新记录,当之前的事务再次读取该范围的记录,会产生幻行。也就是说可重复读只会在修改事务有效,比如一个事务先后读取同一个范围的记录,而在这中间另一个事务对某一条记录做了修改,当前事务两次读取到的结果是一样的,但是如果是新增数据就会产生幻读的现象。为了解决在可重复读级别下发生的幻读的问题,MySQL的InnoDB和XtraDB存储引擎通过多版本并发控制机制(MVCC)解决了幻读的问题。
Serializable(可串化读):Serializable是最高的隔离级别。它通过强制事务串行执行,避免幻读问题。简单来说Serializable会在读取的每一行上加锁,所以可能导致大量的超时和锁竞争问题。实际开发中也很少用到这个隔离级别,只有在非常需要保证数据的一致性而且可以接受没有并发的情况下,才考虑采用该级别。
顺序:
解析:
为什么需要主从同步:
1. 假如网站使用单机数据库,一旦MySQL宕机,整个网站将无法访问。引入MySQL从库,意图保证网站数据库不宕机或者宕机之后能够快速恢复。
2. Master负责写操作的负载,Slave分摊读操作负载,这样一来的可以大大提高读取的效率。在一般的互联网应用中,经调查发现读/写的比例大概在 10:1左右 ,也就是说大量的数据操作是读操作,这也就是为什么我们会有多个Slave的原因。分离读和写是因为,写操作涉及到锁的问题,不管是行锁、表锁还是块锁,都是降低系统执行效率的事情。读写分离可以有效提高读的效率,保证系统的高可用性。
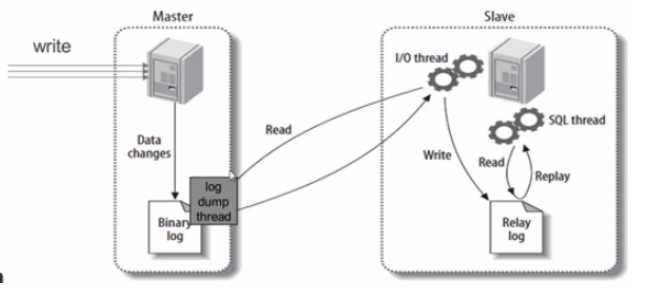
主从同步:
1.主从同步主要有三种形式:statement、row、mixed
2.过程:
MySQL主从同步是异步复制的过程,整个同步需要开启3线程
注:DQL数据查询语言,DML数据操纵语言,DDL数据定义语言,DCL数据控制语言。
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解。
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性。
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
优点:可以尽量得减少数据冗余,更新快,表体积小。
缺点:查询需要多个表进行关联,索引优化困难。
反范式:在原本已满足三范式的基础上再做调整,增加冗余字段。
优点:可以减少表关联查询,可以更好地进行索引优化。
缺点:有数据冗余以及数据异常,数据的修改需要更多的成本。
原文:https://www.cnblogs.com/helios-fz/p/12204419.html