1、基本定位(6种)
from selenium import webdriver driver = webdriver.Chrome() driver.get(‘https://www.baidu.com‘) #方式一,通过id,没有id时,优先选择name ele = driver.find_element_by_id(‘kw‘) #定位id为kw的元素 print(ele) print(ele.get_attribute(‘name‘)) #获取元素的name属性的值 #方式二,class属性 ele2 = driver.find_element_by_class_name(‘s_ipt‘) #通过class属性,获取第一个。有的class的值由多个组成,用空格分隔,如a_1 a_2,这时只能输入一个 ele2_1 = driver.find_elements_by_class_name(‘s_ipt‘) #通过class属性,获取多个 #方式三,通过name属性 ele3 = driver.find_element_by_name(‘wd‘) ele3_1 = driver.find_elements_by_name(‘wd‘) #方式四,通过tag ele4 = driver.find_element_by_tag_name(‘name‘) ele4_1 = driver.find_elements_by_tag_name(‘name‘) #方式五,a标签,完全匹配链接的文本内容 ele5 = driver.find_elements_by_link_text(‘新闻‘) # 如:<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a> ele5_1 = driver.find_element_by_link_text() #方式六,a标签,部分匹配链接的文本内容 ele6 = driver.find_element_by_partial_link_text(‘新闻‘) ele6 = driver.find_elements_by_partial_link_text(‘新闻‘)
2、xpath
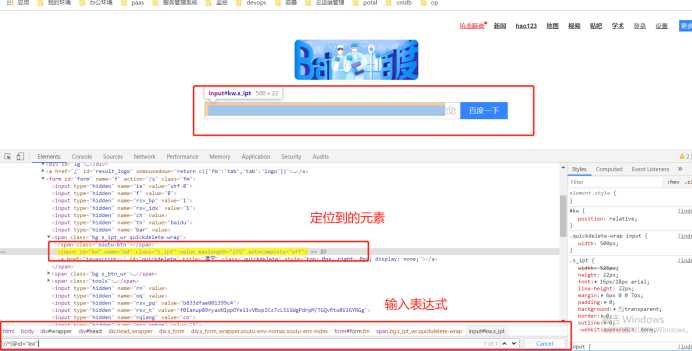
相对位置的写法,谷歌f12,ctrl+f辅助元素定位
//input[@name="wd"] //标签名称[@属性名称=属性值]
//input[@type="hidden" and @name="ie"] 用and或or连接多个条件(逻辑运算)
//div[@id="u1"]/ a[@name="tj_login" and @class="lb"] #定位百度首页的登录,/表示定位到的元素的下级(当单独定位某个元素也无法将其单独定位的话,可以使用层级定位的方式
//a[text()="登录"] 表示a标签中含有文本登录的,这里的text()是函数,可知函数的使用
//input[contains(@class,"username")] contains(@属性/text(),value) 包含函数,适用情况属性由多个组成,用空格分开(如a_1 a_2),由某一个去匹配
#方式七 xpath # 相对位置 以//开头,不依赖于页面的位置和顺序。只看整个表达式中,有没有符合表达式的元素 # 绝对位置 以/开头,非常依赖页面的位置和顺序(真正做项目,不太会使用,因为不太稳定) # 相对位置,谷歌f12,ctrl+f辅助元素定位,如://input[@name="wd"] //标签名称[@属性名称=属性值] driver.find_element_by_xpath(‘//*[@id="kw"]‘)
3、
原文:https://www.cnblogs.com/hzgq/p/12264304.html