seq2seq模型:(编码器 + 解码器)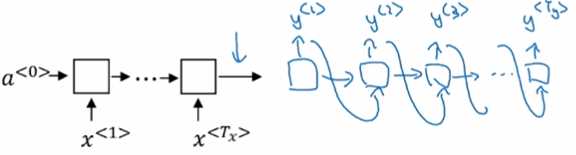
Image captioning模型: (AlexNet + 解码器)
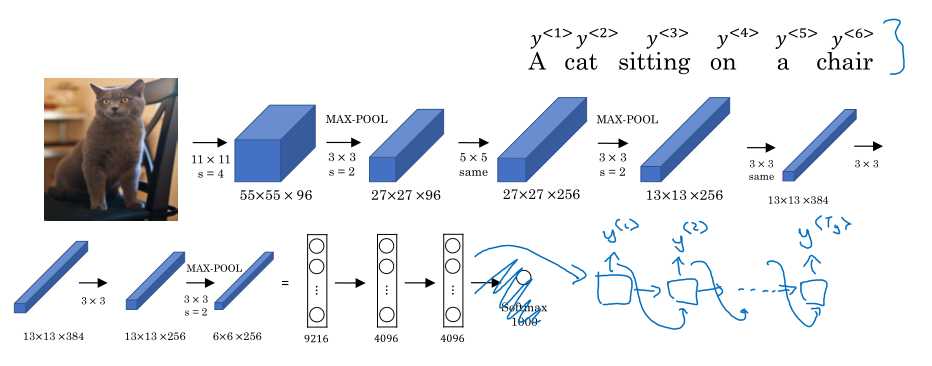
虽然简单粗暴,但是确实有效。
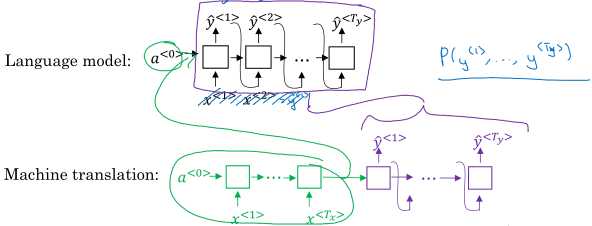
前面讲的语言模型可以给出文本的分布\( P(y^{<1>}, \dots, y^{<T_y>}) \),而机器翻译模型相当于给出条件概率分布\( P(y^{<1>}, \dots, y^{<T_y>} | x^{<1>}, \dots, x^{<T_x>}) \). 所以机器翻译的这种模型也称作条件语言模型(conditional language model)。
从条件概率分布得到最后的翻译结果时又存在一个问题,理论上的优化问题:
\( \arg\max_{y^{<1>}, \dots, y^{<T_y>}} P(y^{<1>}, \dots, y^{<T_y>}|x) \)
假如词典有10000词,文本长10词,共有\(10000^{10}\)种结果,注意在生成翻译结果的时候是一个词一个词的确定,因为前一个时间步的输出要作为下一个时间步的输入,所以这个问题解的搜索空间非常大。不同的翻译结果正确的程度不一样,例如:

你可能觉得只要按照贪婪算法每个词选择概率最大的就好,但这种做法是把各个词看作独立,所以贪婪算法并不是最优。
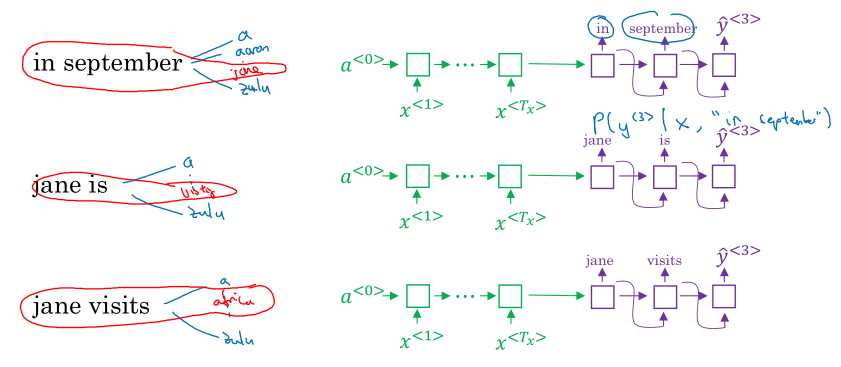
解决前面说的这一问题,可以采用波束搜索(beam search)。
波束搜索的想法是(假设波束宽度\( B\)):
这样每一步都保留\{B\}个词,所以要保留\(B\)个模型的副本。如果波束宽度\(B=1\),就等价于贪婪算法进行搜索。
对波束搜索做一些改进:
原来目标是
\( \begin{gathered} \arg\max_y \prod_{t=1}^{T_y}P(y^{<t>} | x, y^{<1>}, \dots, y^{<t-1>}) \end{gathered} \)
当文本很长时,一个问题是概率值会非常小,有可能会溢出,另一个问题是模型可能更倾向于输出较短的结果,所以改进之后的目标是:
\( \begin{gathered} \frac{1}{T_y^{\alpha}} \arg\max_y \sum_{t=1}^{T_y}\log P(y^{<t>} | x, y^{<1>}, \dots, y^{<t-1>}) \end{gathered} \)
加入了对数运算和归一化,可取\(\alpha=0.7\)作软化处理。
而波束搜索的波束宽度是一个超参数,\(B\)越大,结果越好,但速度更慢;\(B\)越小,速度更快,但结果差一些。
当机器翻译同时使用RNN和波束搜索时,如果最后结果不好,需要进行误差分析,下面介绍方法来分辨到底是RNN的问题还是波束搜索的问题。
在开发集(验证集)上找一些表现比较差的例子 \(\hat{y}\),同时我们有人工翻译的结果 \(y^{*}\),我们利用训练好的模型分别计算\(P(y^{*}|x)\)和\( P(\hat{y}|x) \),这个多说一下,因为输入这个样本之后,输出的每个时间步都有10000词的概率分布,所以可以计算这两种结果的条件概率。
因为波束搜索的目标就是\( \arg\max_y P(y|x) \),如果搜索结果不满足,那一定是波束搜索的问题,而如果是第二种情况,人工翻译的结果在模型看来概率更低,那一定是模型的问题。下面就是列表格进行误差统计:

根据统计的结果来确定是改进波束搜索还是RNN。
语音识别可以用准确率来度量结果的好坏,而机器翻译可能有很多结果都是正确的,所以需要一个新的单一实数指标来度量。
这个Bleu还挺复杂的,我不太感兴趣,直接放这里吧。
将文本拆成一元词组、二元词组等等,然后统计其机器翻译结果中的频次和在人工翻译结果中的频次,计算公式(假设取到四元词组):
\( \begin{gathered} p_n = \frac{\sum_{ngram\in \hat{y}} count_{clip}(ngram) } { \sum_{ngram\in \hat{y}} count(ngram) } \end{gathered} \)
\( \begin{gathered} \text{Bleu score} = \text{BP} \exp{\frac{1}{4} \sum_{n=1}^4 P_n} \end{gathered} \)
其中BP是惩罚较短翻译结果的因子:

以二元词组为例

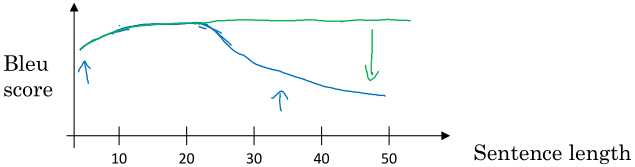
还是机器翻译问题,我们继续从人类的工作方式寻求启发。像前面那种编码器-解码器结构虽然看起来不错了,机器翻译对于长文本的翻译表现还是不行,如下图的蓝线,那咋办呢?注意力机制来了,加了注意力机制之后就是绿线了。
直观理解上,我们人类翻译时不是看完全部文本之后,记住所有内容再翻译,而是选择那些有帮助的上下文边看边翻译。注意力机制就是要学习一个权重,用它来衡量翻译当前词时,其他词的作用。
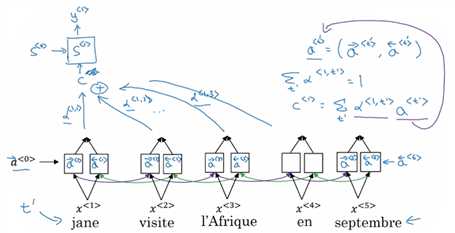
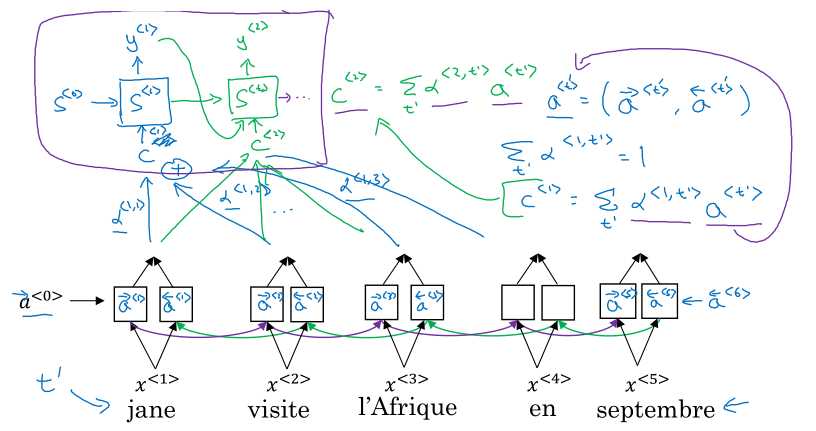
如上图,我们使用双向RNN,计算正向和反向的激活值\( \overrightarrow{a}^{<t‘>}, \overrightarrow{a}^{<t‘>} \)。在翻译第一个词时,要综合多个时间步的激活值计算:
\( \begin{gathered} c^{<1>} = \sum_{t‘} \alpha^{<1,t‘>}a^{<t‘>} \end{gathered} \)
其中\(\alpha^{<1,t‘>}\)就表示翻译第一个词时应当对第\(t‘\)个词施加的注意力,注意力总和为1.
然后翻译第二个词也类似:
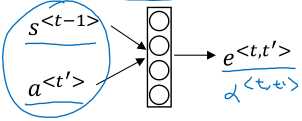
注意力的计算公式为:
\( \begin{gathered} \alpha^{<t,t‘>} = \frac{\exp(e^{<t,t‘>})}{\sum_{t‘=1}^{T_x} \exp(e^{<t,t‘>})} \end{gathered} \)
其中\( e^{<t,t‘>} \)不是指数,而是一个中间量,使用神经网络预测,同时使用softmax确保总和为1.
没什么好讲的,只是两种应用,以后你都会的。
原文:https://www.cnblogs.com/tofengz/p/12266099.html