应用:用于二分类问题,能得出概率值。
输入与线性回归相同:![]() (单个样本)
(单个样本)
Sigmoid函数:能够将输入转化为0-1之间的一个值(转化为一个分类问题)
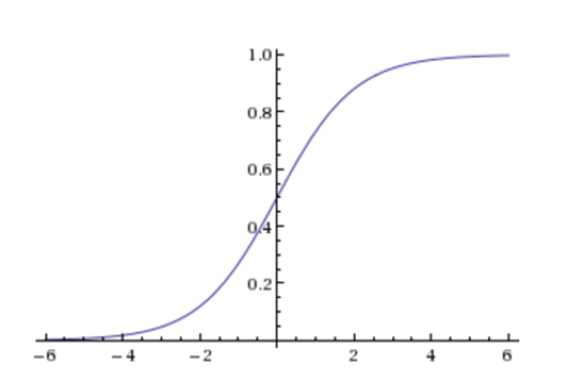
逻辑回归公式:
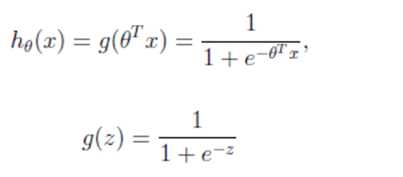
输出:[0,1]区间的概率值,默认0.5作为阀值
注:g(z)为sigmoid函数,z表示线性回归的结果
与线性回归原理相同,但由于是分类问题,损失函数不一样,只能通过梯度下降更新权重。
对数似然损失函数:
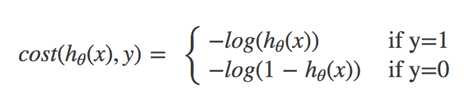
y代表回归结果属于0或1
当y=1时:
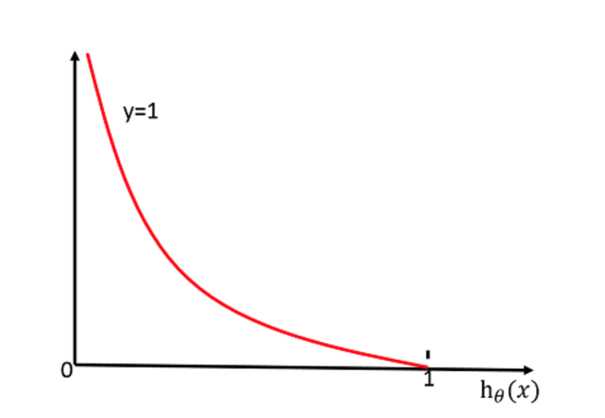
当y=0时:
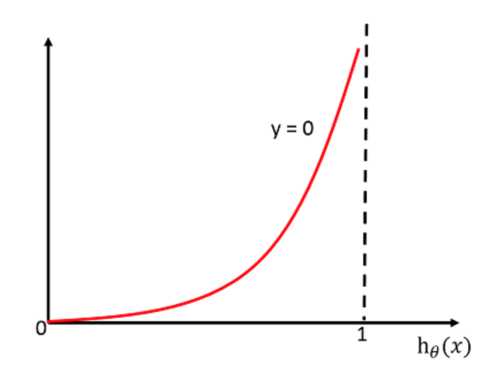
完整的损失函数:
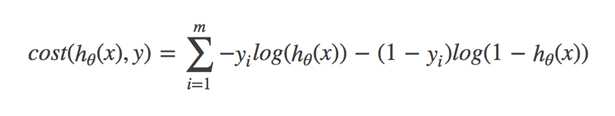
所有样本损失值乘以0/1后的差求和(类似于信息熵的求法)
cost损失的值越小,那么预测的类别准确度更高。
损失函数比较:
均方误差:不存在多个局部级低点,只有一个最小值。
对数似然损失:有多个局部最小值(两个改善方式:① 多次随机初始化,多次比较最小值结果。② 求解过程中调整学习率 )
sklearn.linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression(penalty=‘l2’, C = 1.0)
良/恶性乳腺癌肿瘤预测
数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/
breast-cancer-wisconsin.names 查看说明
breast-cancer-wisconsin.data
数据描述:
(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值。
(2)包含16个缺失值,用”?”标出。
恶性类别的数量少,所以判定恶性的概率值。
分类流程:
① 获取数据
② 数据缺失值处理、标准化
③ 估计器流程
pd.read_csv(‘ ‘,names=column_names)
column_names:指定类别名字,[‘Sample code number‘,‘Clump Thickness‘, ‘Uniformity of Cell Size‘,‘Uniformity of Cell Shape‘,‘Marginal Adhesion‘,‘Single Epithelial Cell Size‘,‘Bare Nuclei‘,‘Bland Chromatin‘,‘Normal Nucleoli‘,‘Mitoses‘,‘Class‘]
return:数据
replace(to_replace=’’,value=):返回数据
dropna():返回数据
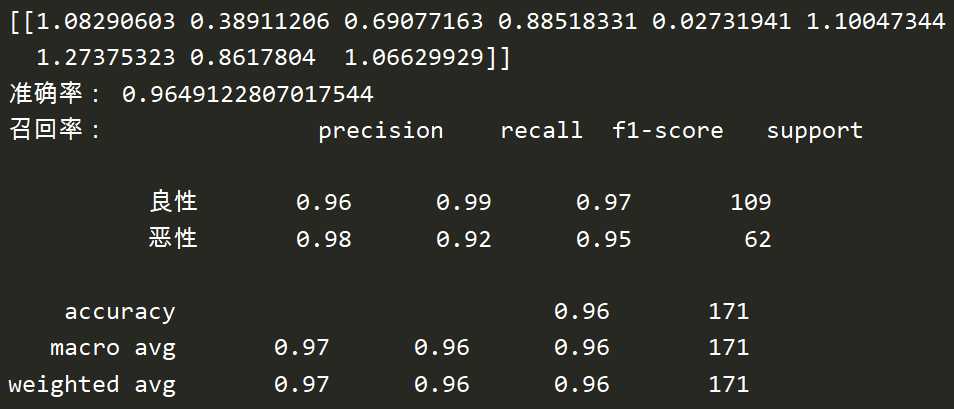
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report def logistic(): """ 逻辑回归根据细胞特征做二分类进行预测 :return: None """ # 读取数据 column = [‘Sample code number‘,‘Clump Thickness‘, ‘Uniformity of Cell Size‘,‘Uniformity of Cell Shape‘,‘Marginal Adhesion‘,‘Single Epithelial Cell Size‘,‘Bare Nuclei‘,‘Bland Chromatin‘,‘Normal Nucleoli‘,‘Mitoses‘,‘Class‘] data = pd.read_csv("./data/breast-cancer-wisconsin.data", names=column) # 处理缺失值:替换后用平均值填充或删除 data = data.replace(to_replace=‘?‘, value=np.nan) data = data.dropna() # 进行数据分割 x_train, x_test, y_train, y_test = train_test_split(data[column[1: 10]], data[column[10]], test_size=0.25) # 进行标准化 # 这里的目标值不需要处理,因为是个分类问题 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 逻辑回归预测 lr = LogisticRegression() lr.fit(x_train, y_train) print(lr.coef_) # 权重参数 print("准确率:", lr.score(x_test, y_test)) print("召回率:", classification_report(y_test, lr.predict(x_test), labels=[2,4], target_names=[‘良性‘, ‘恶性‘])) return None if __name__ == ‘__main__‘: logistic()
其他案例:上下文广告点击 https://www.kaggle.com/c/avito-context-ad-clicks
小结
优点:适合需要得到一个分类概率的场景
缺点:
朴素贝叶斯有先验概率,属于生成模型;逻辑回归是判别模型;
逻辑回归解决办法:1V1,1Vall
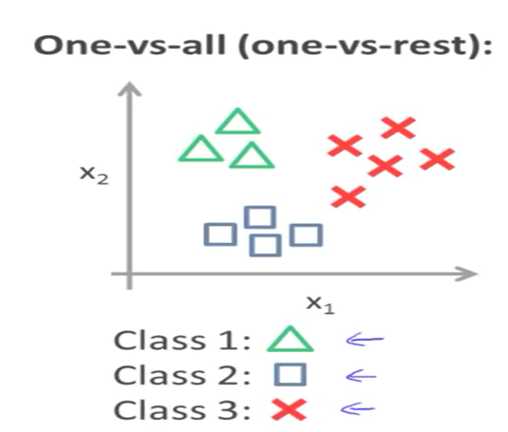
softmax方法:逻辑回归在多分类问题上的推广(详见神经网络部分)
二、
1、
原文:https://www.cnblogs.com/ysysyzz/p/12267472.html