利用pc编写python爬取大学排名的数据,如图:
import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def fillUnivList(ulist, html): soup = BeautifulSoup(html, "html.parser")#bs4的html解析器 for tr in soup.find(‘tbody‘).children: if isinstance(tr, bs4.element.Tag):# bs4.element.Tag是标签类型 tds = tr(‘td‘)#将所有的td标签存为一个列表类型 ulist.append([tds[0].string, tds[1].string, tds[2].string]) def printUnivList(ulist, num): print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "所在地区")) for i in range(num): u = ulist[i] print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1], u[2])) def main(): uinfo = [] url = ‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html‘ html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) main()
代码主要利用了BeautifulSoup库来对response对象进行解析,并通过对指定标签的子标签的遍历得到需要的数据。
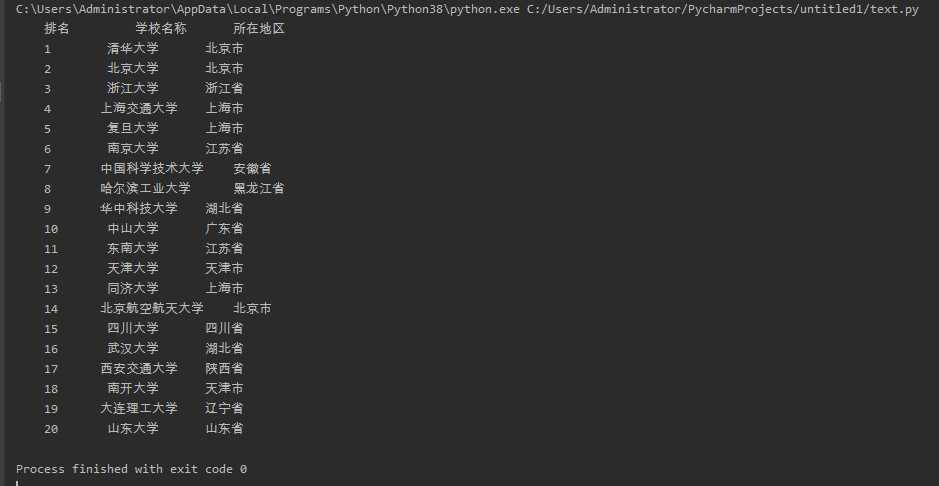
结果截图:
原文:https://www.cnblogs.com/123456www/p/12274783.html