scala> val df = spark.read.json("file:///usr/local/spark/sparklab/employee.json") df: org.apache.spark.sql.DataFrame = [age: bigint, id: bigint ... 1 more field] scala> df.show() +----+---+-----+ | age| id| name| +----+---+-----+ | 36| 1| Ella| | 29| 2| Bob| | 29| 3| Jack| | 28| 4| Jim| | 28| 4| Jim| |null| 5|Damon| |null| 5|Damon| +----+---+-----+
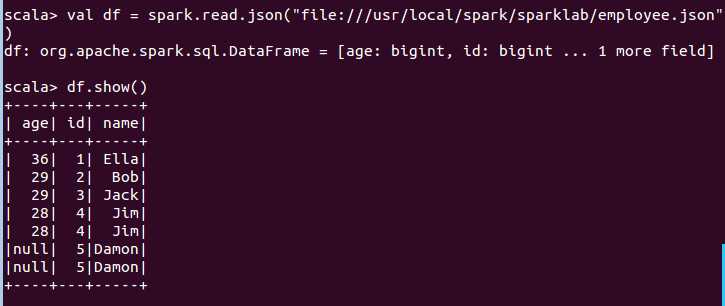
scala> df.distinct().show() +----+---+-----+ | age| id| name| +----+---+-----+ | 36| 1| Ella| | 29| 3| Jack| |null| 5|Damon| | 29| 2| Bob| | 28| 4| Jim| +----+---+-----+
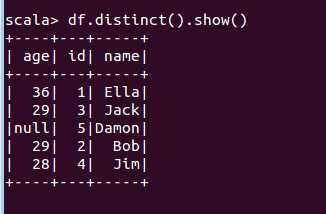
scala> df.drop("id").show() +----+-----+ | age| name| +----+-----+ | 36| Ella| | 29| Bob| | 29| Jack| | 28| Jim| | 28| Jim| |null|Damon| |null|Damon| +----+-----+
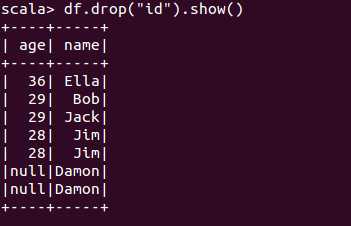
scala> df.filter(df("age") > 30 ).show() +---+---+-----+ |age| id| name| +---+---+-----+ | 36| 1| Ella| +---+---+-----+
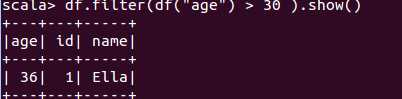

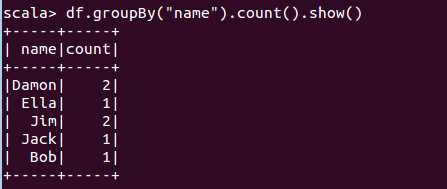
scala> df.groupBy("name").count().show()
+-----+-----+
| name|count|
+-----+-----+
|Damon| 2|
| Ella| 1|
| Jim| 2|
| Jack| 1|
| Bob| 1|
+-----+-----+
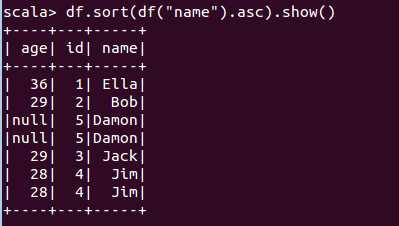
(7) 取出前 3 行数据;
df.take(3) 或 scala> df.head(3
8) 查询所有记录的 name 列,并为其取别名为 username;
df.select(df("name").as("username")).show()
(9) 查询年龄 age 的平均值;
df.agg("age"->"avg")
(10) 查询年龄 age 的最小值。
df.agg("age"->"min")
原文:https://www.cnblogs.com/xuange1/p/12287438.html