1、掌握DataFrame数据结构的创建和基本性质。
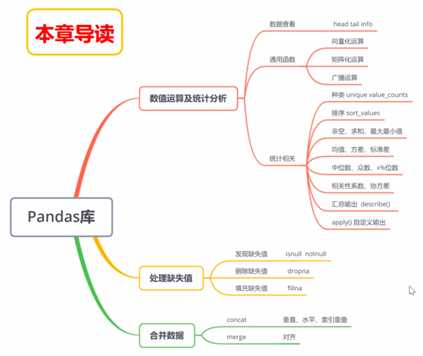
2、掌握Pandas库的数值运算和统计分析方法。
3、掌握DataFrame缺失值处理、数据集合并等操作。
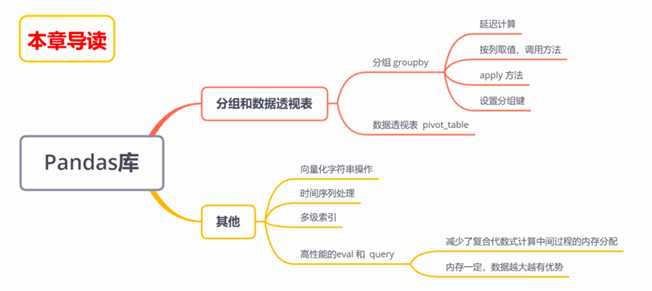
4、掌握DataFrame累计与分组操作。
5、用eval和query实现更高效的计算。
numpy的表现已经很好了,但是当我们需要处理更灵活的数据任务的时候(如为数据添加标签、 处理缺失值、分组等),numpy 的限制就非常明显了,基于numpy而创建的pandas 库提供了一种高效的带行标签和列标签的数据结构DataFrame,完美的解决了上述问题。`
Series是带标签数据的一维数组
通用结构:pd.Series(data, index=index,dtype=dtype)
-data:数据,可以是列表、字典或Numpy数组
- index:索引,为可选参数
- dtype:数据类型,为可选参数
import pandas as pd
data = pd.Series([1.5, 3, 4.5, 6])
print(data)
"""
0 1.5
1 3.0
2 4.5
3 6.0
dtype: float64
"""
# 添加index,数据类型若缺省,则会自动根据传入的数据判断
x = pd.Series([1.5, 3, 4.5, 6], index=["a", "b", "c", "d"])
print(x)
"""
a 1.5
b 3.0
c 4.5
d 6.0
dtype: float64
"""注意:①数据支持多种数据类型 ②数据类型可被强制改变
import numpy as np
import pandas as pd
x = np.arange(5)
pd.Series(x)import pandas as pd
poplation_dict = {"BeiJing": 1234,
"ShangHai": 2424,
"ShenZhen": 1303,
"HangZhou": 981}
pop1 = pd.Series(poplation_dict)
print(pop1)
"""
BeiJing 1234
ShangHai 2424
ShenZhen 1303
dtype: int64
"""
pop2 = pd.Series(poplation_dict, index=["BeiJing", "HangZhou", "c", "d"])
print(pop2)
"""
BeiJing 1234.0
HangZhou 981.0
c NaN
d NaN
dtype: float64
"""字典创建时,如果指定index,则会到字典的键中筛选,找不到的,值则为NaN
import pandas as pd
p = pd.Series(5, index=[100, 200, 300])
print(p)
"""
100 5
200 5
300 5
dtype: int64
"""DataFrame是带标签数据的多维数组
通用结构:pd.DataFrame(data, index=index, columns=columns)
- data:数据,可以为列表、字典或Numpy数组
- index:索引,为可选参数
- columns:列标签,为可选参数
import pandas as pd
poplation_dict = {"BeiJing": 1234,
"ShangHai": 2424,
"ShenZhen": 1303,
"HangZhou": 981}
pop = pd.Series(poplation_dict)
p = pd.DataFrame(pop)
print(p)
"""
0
BeiJing 1234
ShangHai 2424
ShenZhen 1303
HangZhou 981
"""
p = pd.DataFrame(pop, columns=["population"])
print(p)
"""
population
BeiJing 1234
ShangHai 2424
ShenZhen 1303
HangZhou 981
"""注意:数量不够的会自动补齐
import pandas as pd
poplation_dict = {"BeiJing": 1234,
"ShangHai": 2424,
"ShenZhen": 1303,
"HangZhou": 981}
GDP_dict = {"BeiJing": 1334,
"ShangHai": 3424,
"ShenZhen": 5303,
"HangZhou": 9681}
pop = pd.Series(poplation_dict)
gdp = pd.Series(GDP_dict)
p = pd.DataFrame({"population": pop,
"GDP": gdp,
"country": "china"})
print(p)
"""
population GDP country
BeiJing 1234 1334 China
ShangHai 2424 3424 China
ShenZhen 1303 5303 China
HangZhou 981 9681 China
"""import pandas as pd
data = [{"a": i, "b": 2*i} for i in range(3)]
p = pd.DataFrame(data)
d1 = [{"a": 1, "b": 1}, {"b": 3, "c": 4}]
p1 = pd.DataFrame(d1)
print(p)
print(p1)
"""
a b
0 0 0
1 1 2
2 2 4
a b c
0 1.0 1 NaN
1 NaN 3 4.0
"""import numpy as np
import pandas as pd
p = pd.DataFrame(np.random.randint(10, size=(3, 2)), columns=["foo", "bat"], index=["a", "b", "c"])
print(p)
"""
foo bat
a 1 3
b 0 3
c 4 6
"""原文:https://www.cnblogs.com/lyszyl/p/12289457.html