1.创建一个爬虫项目:scrapy startproject mySpider
2.创建一个爬虫脚本:scrapy genspider itcast itcast.cn
3.如图:在spiders文件夹中刚刚创建好的有itcast.py文件
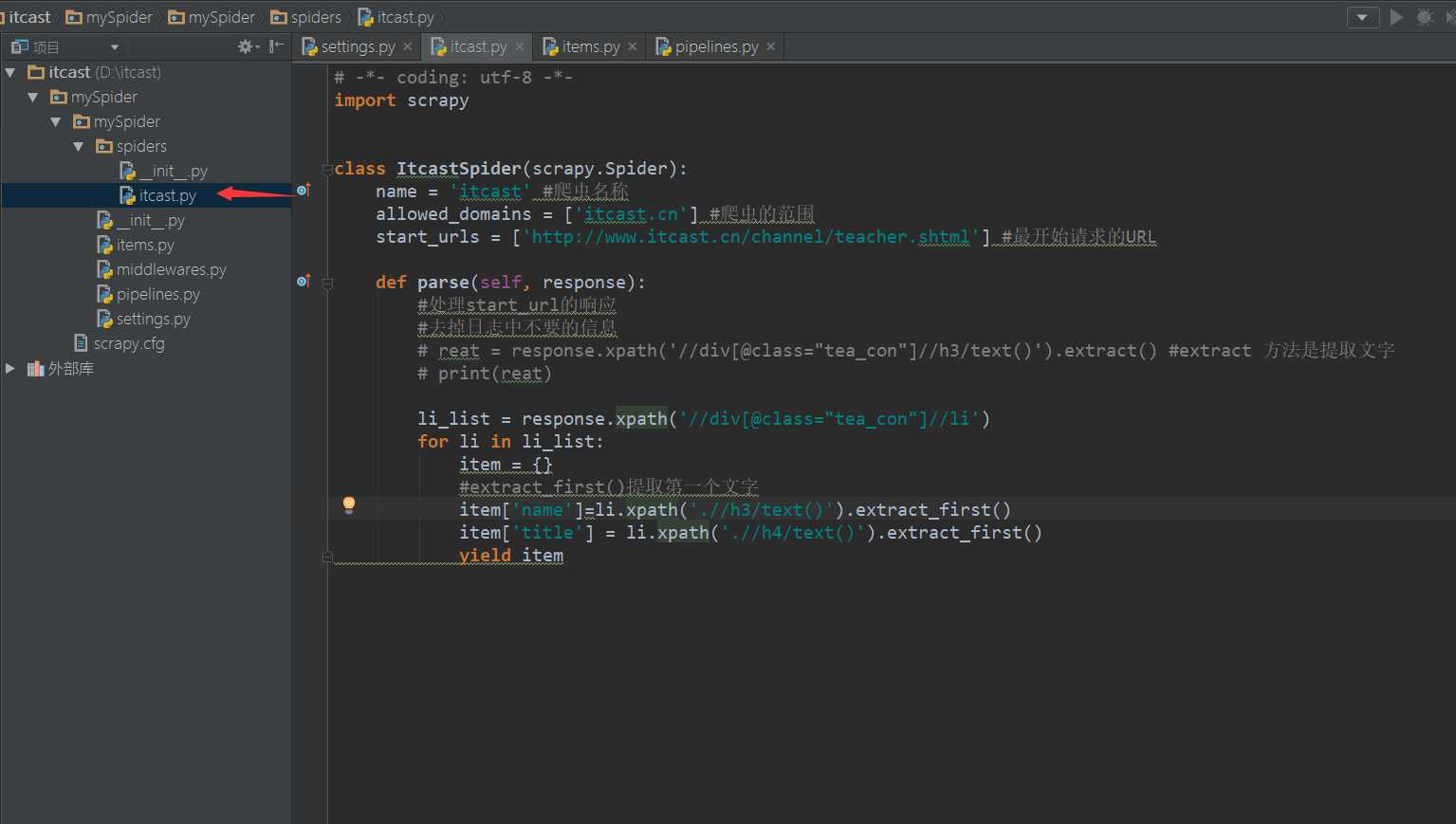
其中:
extracr()方法提取响应中的文字,extract_first()方法是提取响应中第一个文字 yield 返回一个生成器,减少内存占用
4.spiders文件夹中有pipelines.py文件
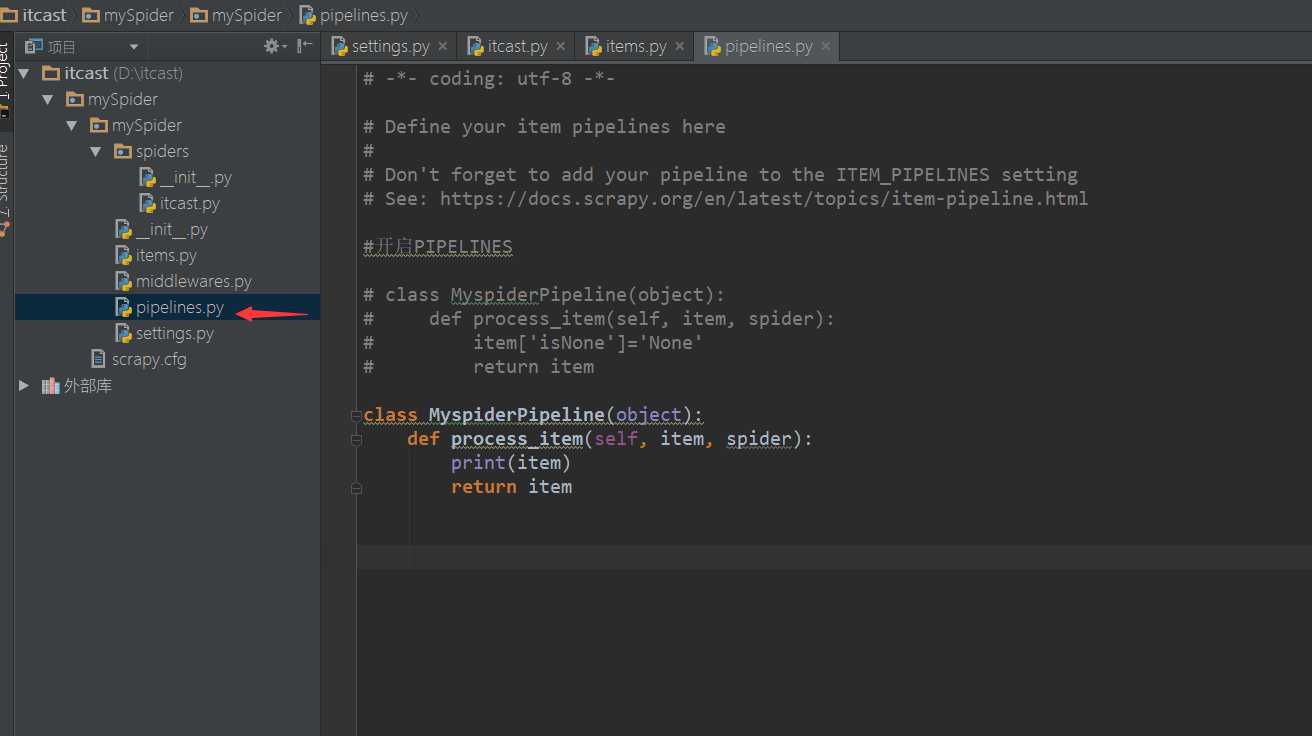
pipelines.py主要是处理itacst.py 返回的生成器
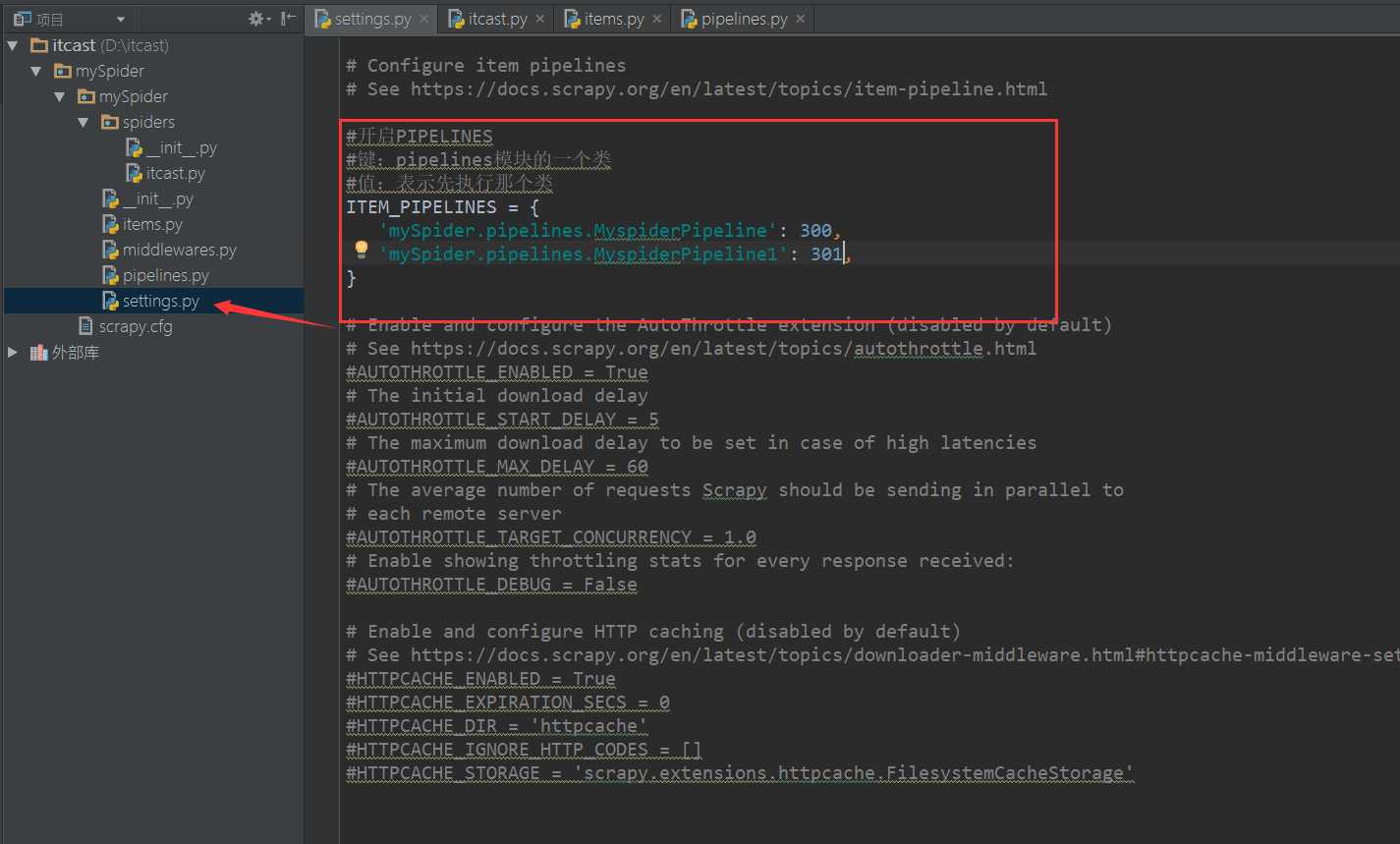
5.开启pipelines
原文:https://www.cnblogs.com/PlusBGM/p/12292438.html