公司项目测试环境调用某些接口的时候,服务器立即崩溃,并一定时间内无法提供服务。
第一反应是服务器需要升配啦,花钱解决一切!毕竟测试服务器配置确实不高,2CPU + 4Gib,能干啥?不过问题是今天突然发生的,而且说崩就崩。凭着严谨的态度,还是要刨根问底地找下问题。
free -m内存占用并不大,忘记截图了,反正看下来不是内存过高导致的崩溃
top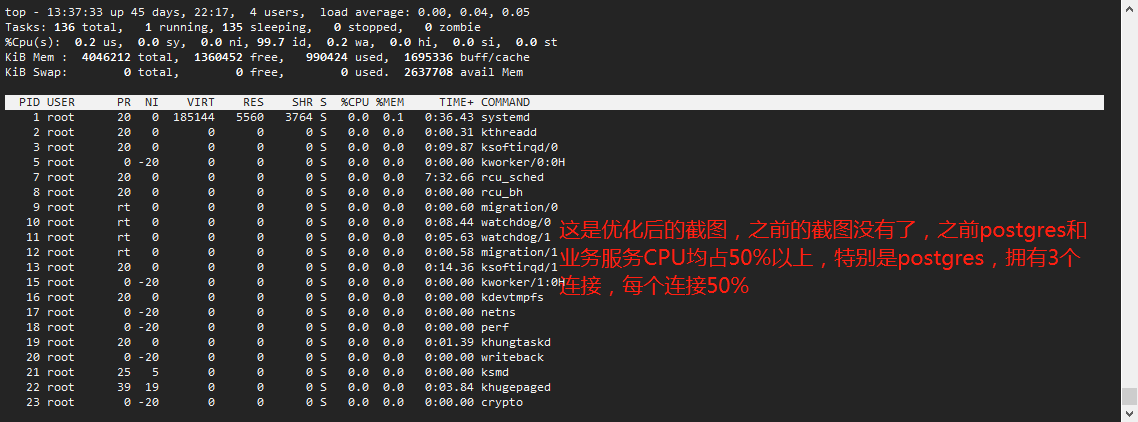
业务高峰活跃连接陡增,活跃的连接数是否比平时多很多
SELECT
COUNT(*)
FROM
pg_stat_activity
WHERE
STATE NOT LIKE '%idle';查询下来只有3个连接,所以不是连接数导致的CPU过高
如果活跃连接数的变化处于正常范围,则可能是当时有性能很差的SQL被大量执行。
select
datname,
usename,
client_addr,
application_name,
state,
backend_start,
xact_start,
xact_stay,
query_start,
query_stay,
replace(
query,
chr(10),
' '
) as query
from
(
select
pgsa.datname as datname,
pgsa.usename as usename,
pgsa.client_addr client_addr,
pgsa.application_name as application_name,
pgsa.state as state,
pgsa.backend_start as backend_start,
pgsa.xact_start as xact_start,
extract(
epoch
from
(now() - pgsa.xact_start)
) as xact_stay,
pgsa.query_start as query_start,
extract(
epoch
from
(now() - pgsa.query_start)
) as query_stay,
pgsa.query as query
from
pg_stat_activity as pgsa
where
pgsa.state != 'idle'
and pgsa.state != 'idle in transaction'
and pgsa.state != 'idle in transaction (aborted)'
) idleconnections
order by
query_stay desc
limit
5;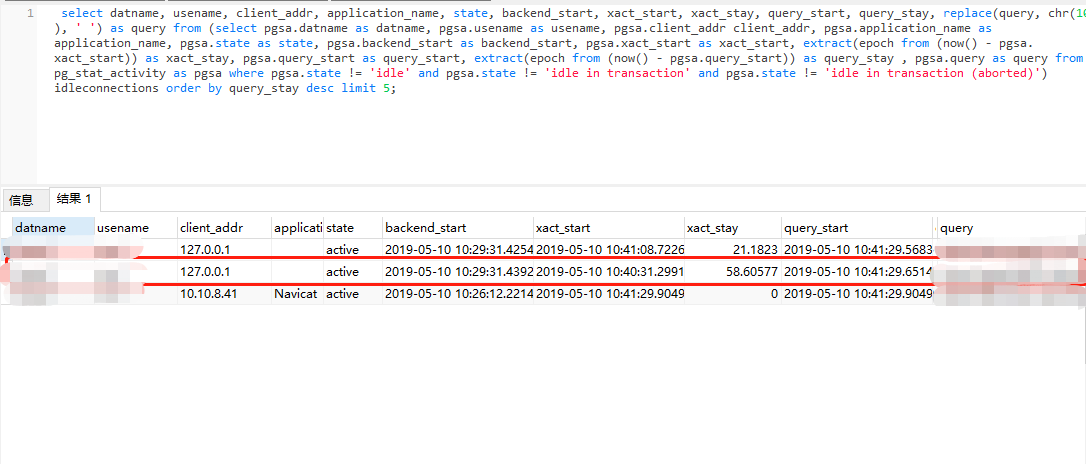
可以看到,确实有一条慢SQL,而且属于奇慢无比,执行了接近1分钟还没执行完毕,基本可以定位,是慢SQL导致的CPU占用陡增。
对于上面的方法查出来的慢SQL,首先需要做的是Kill掉他们,使业务先恢复。
select pg_cancel_backend(pid) from pg_stat_activity where query like '%<query text>%' and pid != pg_backend_pid();
select pg_terminate_backend(pid) from pg_stat_activity where query like '%<query text>%' and pid != pg_backend_pid();如果这些SQL确实是业务上必需的,则需要对他们做如下优化:
ANALYZE <table>或VACUUM ANZLYZE <table>,更新表的统计信息,使查询计划更准确。为避免对业务影响,最好在业务低峰执行。explain <query text>或explain (buffers true, analyze true, verbose true) <query text>命令,查看SQL的执行计划(前者不会实际执行SQL,后者会实际执行而且能得到详细的执行信息),对其中的Table Scan涉及的表,建立索引。在查询语句中,尽量减少不必要的子查询,公司使用的ORM框架是Spring JPA,针对一些特别慢的HQL,可以采用直接执行SQL的方式来优化查询效率。
@Query(value = "select count(*) from example_table where example_id = :exampleId", nativeQuery = true)
int exampleNativeQuery(@Param("exampleId") Long exampleId);PostgreSQL/PPAS CPU使用率高的原因及解决办法
原文:https://www.cnblogs.com/gcdd/p/12292417.html