多线程这个东西,感觉一直以来都是用一次就要学一次,今天需要将之前写的脚本改成线程池的形式又学习了一轮。为了以后方便在这直接记下来。

import threading import time import datetime # 该类是自定义的多线程类 # 多己写多线程时仿造记类实现自己的多线程类即可 class MyThread(threading.Thread): def __init__(self): threading.Thread.__init__(self) # 必须实现函数,run函数被start()函数调用 def run(self): thread_name = threading.current_thread().name print(f"开始线程: {thread_name}") self.print_time() print(f"退出线程: {thread_name}") # 可选函数,此处函数的代码可移到run函数内部,也可放到MyThread之外,无关紧要 # 线程要做的具体事务函数,我们这里就打印两轮时间 def print_time(self): count = 2 thread_name = threading.current_thread().name while count: time.sleep(1) print(f"{thread_name}: {datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S %f‘)}") count -= 1 # 该类是一个演于调用MyThread的类 # 其实其代码也完全可以放在if __name__ == "__main__"处 class TestClass(): def __init__(self): pass def main_logic(self): # 创建新线程实例 thread_1 = MyThread() thread_2 = MyThread() # 启动新线程 thread_1.start() thread_2.start() # thread_1.join()即当前线程(亦即主线程)把时间让给thread_1,待thread_1运行完再回到当前线程 # thread_2.join()即当前线程(亦即主线程)把时间让给thread_2,待thread_1运行完再回到当前线程 # join()方法非阻塞 # 如果没对某个线程使用join()方法,那么当前线程(亦即主线程)不会等待该线程执行完再结束,他会直接结束 # 在多线程的进程中,主线程的地位和其他线程的地位是平等的,不会说主线程退出了就会导致整个进程,进而导致其他线程被迫终止 # 自己把这两句join()注释掉再运行一遍,可以更好理解这里的说法 thread_1.join() thread_2.join() print("退出主线程") if __name__ == "__main__": obj = TestClass() obj.main_logic()
运行结果如下:
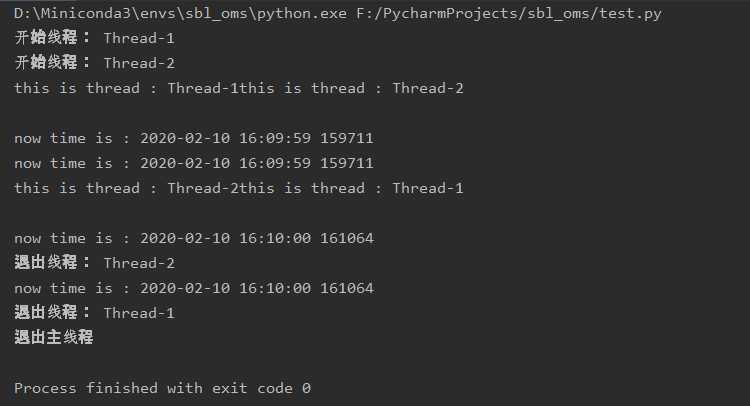
上一小结的代码运行可以成功,但在输出的时候,可以看到是很混乱的:线程1刚打印完自己的名字还没打印时间线程2就抢着打印自己的名字了。
造成这种结果的原因是,默认的多线程中,各线程之间是没有感知的。比如线程2并不知道线程1执行到了哪里(反过来亦然),是刚打印完名字还是已经打印完名字和时间还是其他什么状态,都是不知道的。
所谓同步最主要的就是使用某种方法让线程之间能在一定程度上知道对方在做什么,至少的目标是在使用共用资源时能告诉对方我正在使用你先不要用,实现这“至少”目标最常用的方法是使用锁。
Python3中锁对应的类是threading.Lock(),可通过该类的acquire()方法来获取锁,然后通过该类的release()方法来释放锁。
import sys import threading import time import datetime # 该类是自定义的多线程类 # 多己写多线程时仿造记类实现自己的多线程类即可 class MyThread(threading.Thread): def __init__(self,threading_lock): threading.Thread.__init__(self) # 同步添加处2/4:承接传进来的锁 self.threading_lock = threading_lock # 注意锁必须定义在线程类外部,不能如下在线程类内部自己定义锁 # 因为如果锁在线程类内部才定义,每个线程都是不同的线程类实例,那么各线程间的锁变量本质上就不是同一个锁变量了 # self.threading_lock = threading.Lock() # 必须实现函数,run函数被start()函数调用 def run(self): thread_name = threading.current_thread().name print(f"开始线程: {thread_name}") self.print_time() print(f"退出线程: {thread_name}") # 可选函数,此处函数的代码可移到run函数内部,也可放到MyThread之外,无关紧要 # 线程要做的具体事务函数,我们这里就打印两轮时间 def print_time(self): count = 2 thread_name = threading.current_thread().name while count: time.sleep(1) # 同步添加处3/4:要操作共用资源(这里即打印)时获取锁 self.threading_lock.acquire() print(f"this is thread : {thread_name}") print(f"now time is : {datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S %f‘)}") # 同步添加处4/4:操作完共用资源(这里即打印)后释放锁 self.threading_lock.release() count -= 1 # 该类是一个演于调用MyThread的类 # 其实其代码也完全可以放在if __name__ == "__main__"处 class TestClass(): def __init__(self): pass def main_logic(self): # 同步添加处1/4:定义一个锁对象 threading_lock = threading.Lock() # 创建新线程实例 thread_1 = MyThread(threading_lock) thread_2 = MyThread(threading_lock) # 启动新线程 thread_1.start() thread_2.start() # thread_1.join()即当前线程(亦即主线程)把时间让给thread_1,待thread_1运行完再回到当前线程 # thread_2.join()即当前线程(亦即主线程)把时间让给thread_2,待thread_1运行完再回到当前线程 # join()方法非阻塞 # 如果没对某个线程使用join()方法,那么当前线程(亦即主线程)不会等待该线程执行完再结束,他会直接结束 # 在多线程的进程中,主线程的地位和其他线程的地位是平等的,不会说主线程退出了就会导致整个进程,进而导致其他线程被迫终止 # 自己把这两句join()注释掉再运行一遍,可以更好理解这里的说法 thread_1.join() thread_2.join() print("退出主线程") if __name__ == "__main__": obj = TestClass() obj.main_logic()
使用锁后输出如下:
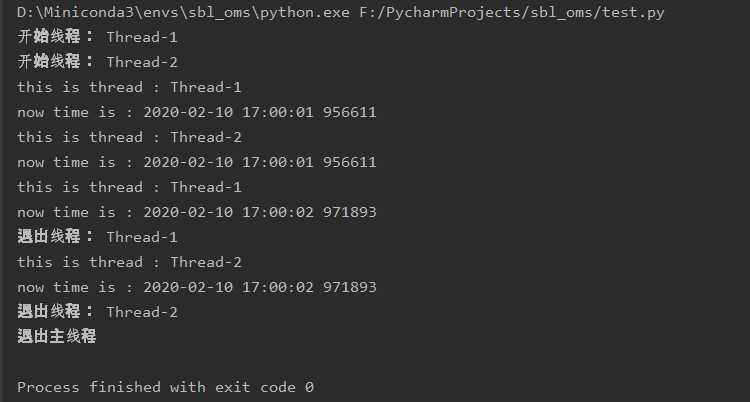
虽然在上一小节的代码注释中有说明,但一是自己踩了坑然后想了半天二是感觉应该还是比较典型的容易犯的问题,所以单独一节再强调一下。
代码注释如下:
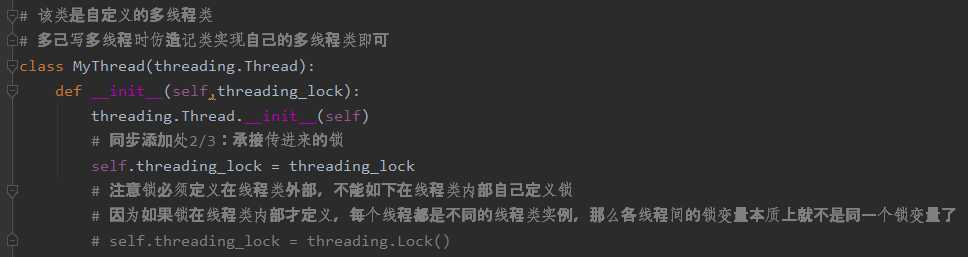
总的意思就是线程同步用的锁必须要来自线程类外部而不能是来自线程类内部的自己实例化。
举个例子,比如我们有一个类叫Test其内部有一个变量a,Test类有两个实例化对象test1和test2,那么我们知道test1.a和test2.a并不是一个变量,对test1.a的任何操作都不会影响test2.a。
所以自己print顺序混乱,使用了锁还是混乱时,就要注意是不是自己的锁是在线程类内部实例化的(不要盯着网上什么print()不是线程安全的、要用sys.stdout.write()之类的说法想半天)。
假设我们有100个任务,我们打算分10轮进行,每轮创建10个线程去处理10个任务,这是一个可行的做法,但有些粗放。
每轮创建10个线程,那么就意味着完成这100个任务前后共有100个线程的创建及消毁的动作,而如果我们创建10个线程组成线程池那么就能反复复用这10个线程,完成100个任务的前后总共只有10个线程的创建及消毁的动作。(但要注意整个过程中并不一定是每个线程都处理10个任务了,有的线程可能处理多于10个,有的线程则可能处理少于10个)
减少线程创建及消毁过程天损失的计算资源正是线程池的意义所在。
有时候我们会遇到这种情况:我们之前已经写好了一个类,但该类是单线程的我们现在机改成多线程的形式。
我们下边来看一下如何该动最少的代码,将该类改成使用线程池的形式;同时有了第二大节的知识,也直接改成线程同步的形式。
假设原始的单线程的代码形式如下:
import threading import time class TestClass(): def __init__(self): pass def main_logic(self): for i in range(4): self.do_something(i) pass def do_something(self, para): thread_name = threading.current_thread().name print(f"this is thread : {thread_name}") print(f"the parameter value is : {para}") time.sleep(1) pass if __name__ == "__main__": obj = TestClass() obj.main_logic()
执行结果如下:
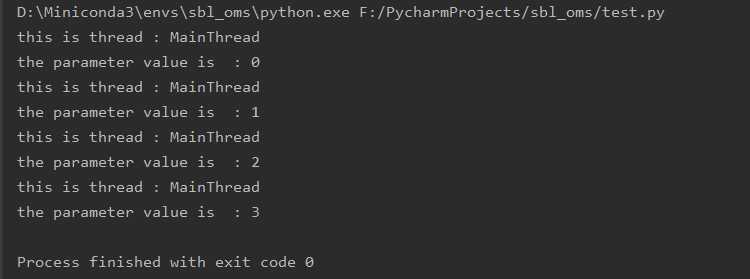
改造后代码如下:
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor # 线程池,进程池 import threading import time class TestClass(): def __init__(self): # 线程池+线程同步改造添加代码处1/5: 定义锁和线程池 # 我们第二大节中说的是锁不能在线程类内部实例化,这个是调用类不是线程类,所以可以在这里实例化 self.threadLock = threading.Lock() # 定义2个线程的线程池 self.thread_pool = ThreadPoolExecutor(2) # 定义2个进程的进程池。进程池没用写在这里只想表示进程池的用法和线程池基本一样 # self.process_pool = ProcessPoolExecutor(2) pass def main_logic(self): for i in range(4): # 线程池+线程同步改造添加代码处3/5: 注释掉原先直接调的do_something的形式,改成通过添加的中间函数调用的形式 # self.do_something(i) self.call_do_something(i) pass # 线程池+线程同步改造添加代码处2/5: 添加一个通过线程池调用do_something的中间方法。参数与do_something一致 def call_do_something(self, para): self.thread_pool.submit(self.do_something, para) def do_something(self, para): thread_name = threading.current_thread().name # 线程池+线程同步改造添加代码处4/5: 获取锁 self.threadLock.acquire() print(f"this is thread : {thread_name}") print(f"the parameter value is : {para}") # 线程池+线程同步改造添加代码处5/5: 释放锁 self.threadLock.release() time.sleep(1) pass if __name__ == "__main__": obj = TestClass() obj.main_logic()
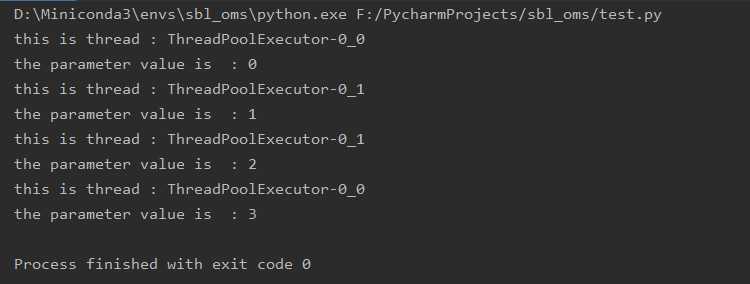
执行结果如下:
参考:
https://www.runoob.com/python3/python3-multithreading.html
https://blog.csdn.net/java_raylu/article/details/85217892
原文:https://www.cnblogs.com/lsdb/p/12291385.html
