事务
事务就是一组数据库操作,要么全部执行成功,要么全部执行失败,在MySQL中,事务是依靠存储引擎层实现的。
ACID(Atomicity,Consistency,Isolation,Durability)
原子性是指事务是不可再分的,是最小的工作单元。
一致性是指数据的完整性必须保持一致。
隔离性则是指多个用户并发访问数据库时,必须为每个用户开启一个事务,这些事务相互之间不受影响相互隔离。
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
隔离级别
首先需要清楚的一点是,隔离得越严实,效率就会越低,因此许多时候是在这两者时间找寻平衡点。
隔离级别包括以下四个:
读未提交(READ UNCOMMITTED):是指一个事务未提交时,做的变更能被其他事务看到。
读提交(READ COMMITTED):是指一个事务提交之后,做的变更能被其他事务看到。
可重复读(REAPEATABLE READ):是指一个事务执行过程看到的数据,总是和这个事务启动时看到的数据是一致的,并且,未提交的变更对于其他事务也是不可见的。
串行化(SERIALIZABLE):是指对于同一行记录,写会对其加写锁,读会对其加读锁,当出现读写锁冲突的时候,后访问的事务必须等前一个事务完成才能继续执行。这也是级别最高的隔离级别。
煮个栗子
先假设数据表T中只有一列,其中一行值为1,那么对于不同的隔离级别,表格中的V1V2V3的值就会有不同。
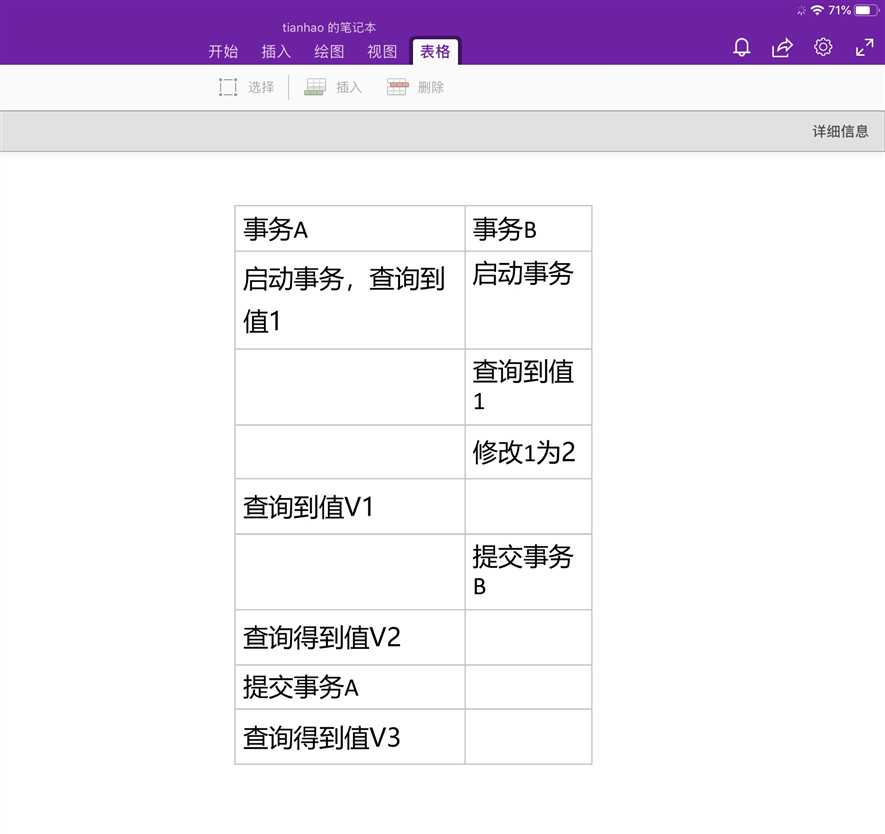
1,对于读未提交,那么B虽然没有提交但是B做的修改可以被A看到,所以V1查出来是就是修改后的2了,那么自然V2也是2,V3也是2;
2,对于读提交,那么B在没提交之前做的修改A都是看不到的,所以V1仍然是1,但是在查V2之前B提交了,所以V2等于2,V3也等于2;
3,对于可重复读,意味着一个事务执行期间看到的值都是一样的,在启动时查询到的值为1,那么在A未提交前看到的都是1,所以V1V2都是1,V3为2;
4,对于串行化,因为A在B之前查询到1,所以在B进行修改时,并不能继续往下,而是必须等待A执行结束,所以V1V2都是1,V3为2;
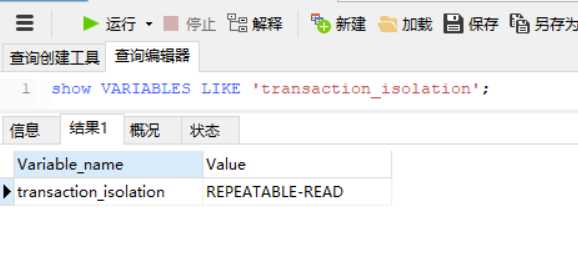
查询自己数据库的隔离级别:
SHOW VARIABLES LIKE ‘transaction_isolation‘;
事务隔离的实现:
在MySQL中,实际上每一条记录在更新的时候都会同时记录一条回滚的记录,记录上最新的值,通过回滚能找到前一个状态下的值,在不同的时刻
启动的事务就会有不同的read-view,同一条记录在系统中可以存在很多个版本。煮个栗子:(图片来自丁奇的MySQL45讲)
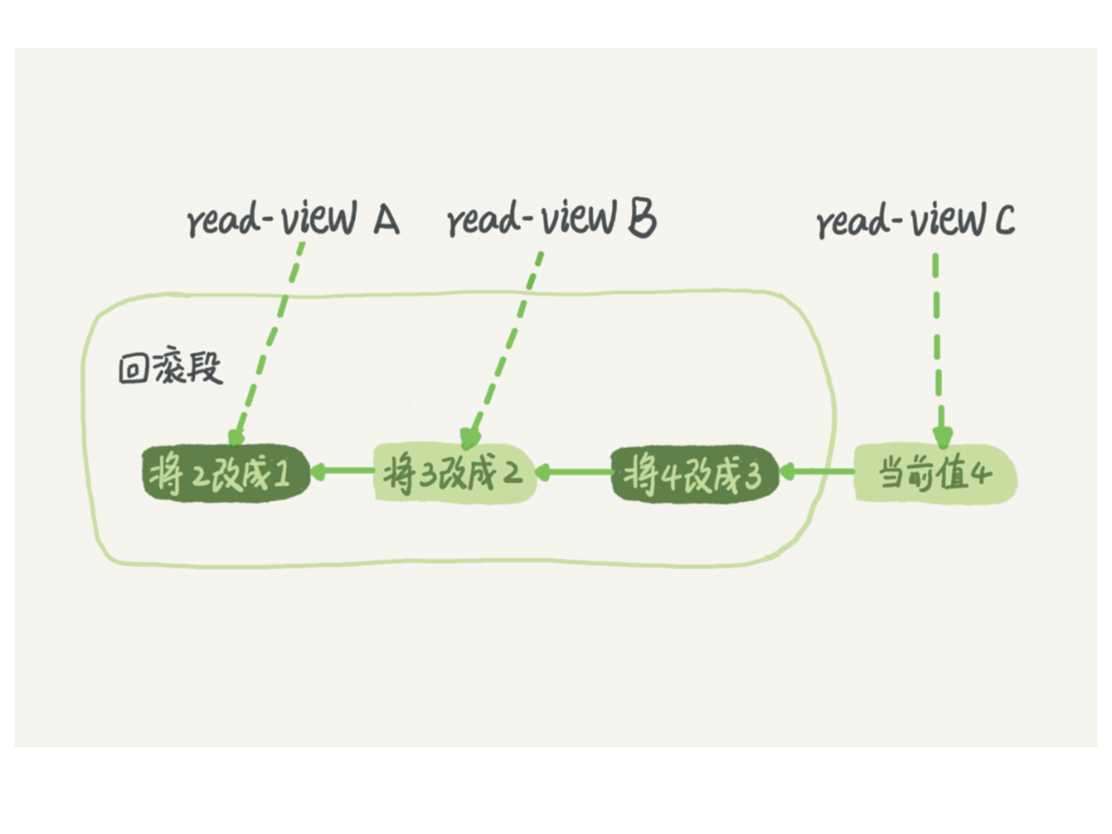
从左往右看,就是1按顺序被修改为2,3,4,在回滚日志中能看到上图这样的记录,
在视图A,B,C里面,此记录的值是1,2,4。此时即使有另一个事务正在将4再改成5,这个事务跟read-viewA,B,C对应的事务不会冲突的。
详细的原理本人还没有进行深入了解,如果日后学到了再补上。
事务的启动方式:
显式启动:start transaction/begin,配套提交语是commit,回滚是rollback
将自动提交关闭即set autocommit=0,意味着如果你执行一个select语句,这个事务就启动了,并不会自动提交,直到手动commit或者rollback,
或者断开连接。这种自然是不好的,因为客户端如果跟MySQL一直是长连接,那么就导致长事务,长事务会导致系统里面有许多老的事务视图。
且这些事务视图可以访问数据库中的任何数据,事务提交之前的所有的回滚记录都会得到保留,占用大量存储空间。除此之外,长事务也占用
锁资源,对库的性能有很大影响。
原文:https://www.cnblogs.com/Yintianhao/p/12293616.html