聚集索引与非聚集索引
如果表的存储引擎配置的是MyISAM,那么在对应的磁盘路径下会生成.frm(存储的是表结构定义的一些数据)和.MYD(存储的表数据)和.MYI(存储的是索引的数据),这个时候表数据和索引是分开存储在两个文件中的,称为非聚集索引
如果表的存储引擎配置的是InnoDB,那么在对应的磁盘路径下会生成.frm(存储的是表结构定义的一些数据)和.ibd(存储的是索引和数据文件的合集),这个时候表数据和主键索引是存储在一起的,所以InnoDB的主键索引称为聚集索引
注意:innodb表必须有主键(数据文件都是基于主键索引组织的,没有主键,mysql会想办法帮我们搞定,所以主键必须要有)
MyISAM的B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址(指向存放数据的物理块的指针)。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的,且MYISAM引擎中可以不设主键
InnoDB的B+Tree的叶子节点上的data(主键索引:存放的是数据本身),(非主键索引:存放的是主键值,通过非主键索引也叫二级索引查询时,首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块)
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别,我们假想一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。
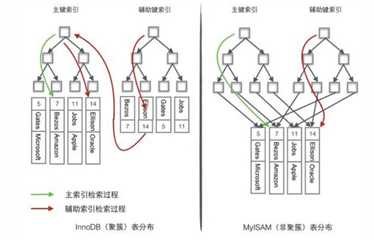
我们重点关注聚簇索引,看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
磁盘IO与预读
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
以MySQL的B+树为例,简单说下几种常见场景下,数据的定位过程。
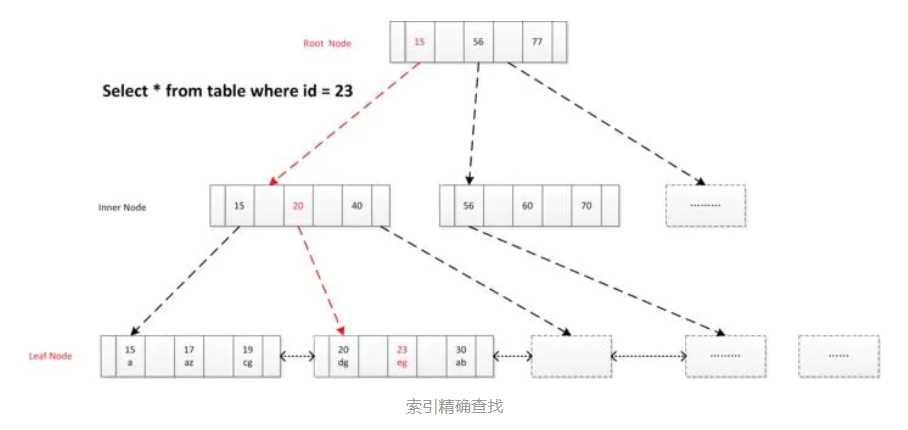
第一种场景:索引精确查找
注意:B+树的非叶子节点一般是常驻内存的
select * from user_info where id = 23 ;
确定定位条件, 找到根节点Page No, 根节点读到内存(如果内存中存在就不需要从磁盘读到内存), 逐层向下查找, 读取叶子节点Page,通过 二分查找找到记录或未命中。
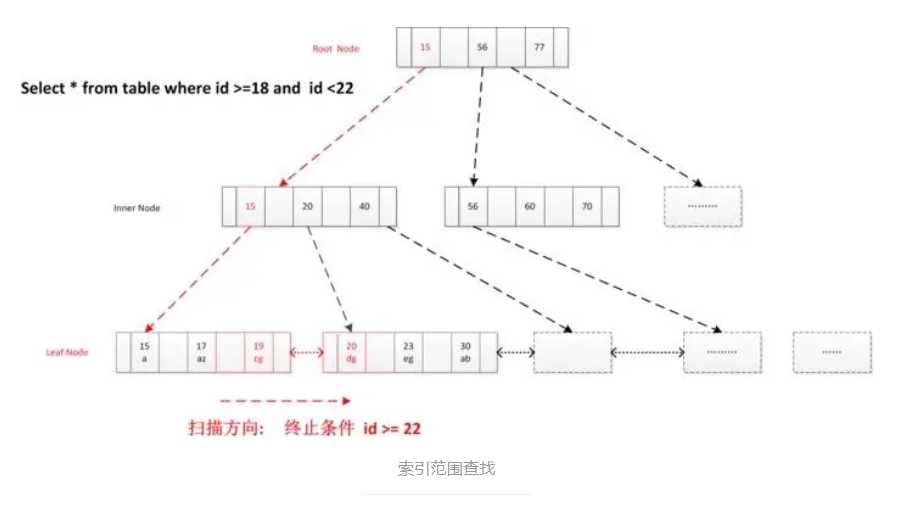
第二种场景:索引范围查找
注意:叶子节点是根据键值从左到右顺序递增的,节点之间是有双向指针的,在加上磁盘io预读机制,所以读取速度是很快的
select * from user_info where id >= 18 and id < 22 ;
读取根节点至内存, 确定索引定位条件id=18, 找到满足条件第一个叶节点, 顺序扫描所有结果, 直到终止条件满足id >=22。
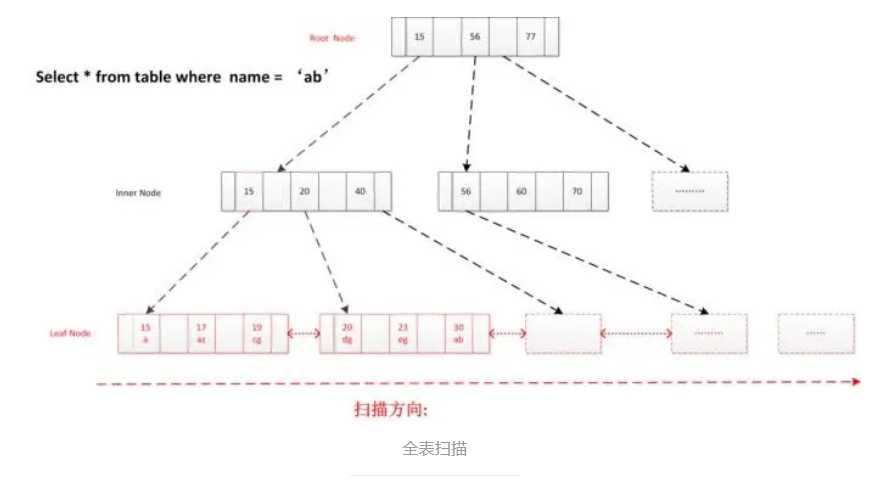
第三种场景:全表扫描
注意:由于name列没有添加索引,所以查询name会进行全表扫描(InnoDB引擎的表主键索引是和数据存储在一起的,数据在磁盘中的存储数据是根据主键值排序的)
select * from user_info where name = ‘abc‘ ;
直接读取叶节点头结点, 顺序扫描, 返回符合条件记录, 到最终节点结束
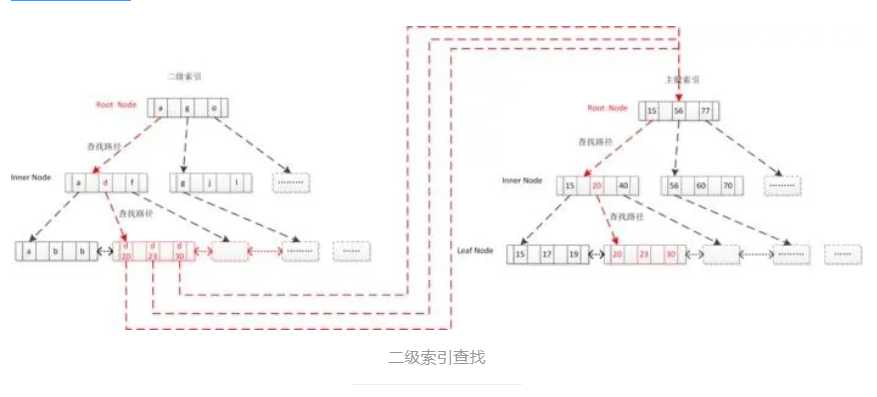
第四中场景:二级索引查找
create table table_x(int id primary key, varchar(64) name , key sec_index(name) ) ; select * from table_x where name = ‘d‘ ;
通过二级索引查出对应主键,拿主键回表查主键索引得到数据, 二级索引可筛选掉大量无效记录,提高效率
原文:https://www.cnblogs.com/blwy-zmh/p/12109040.html