爬取的网站:
http://sohu.com/c/8/1463?spm=smpc.null.side-nav.16.1581303075427Zowrm4P
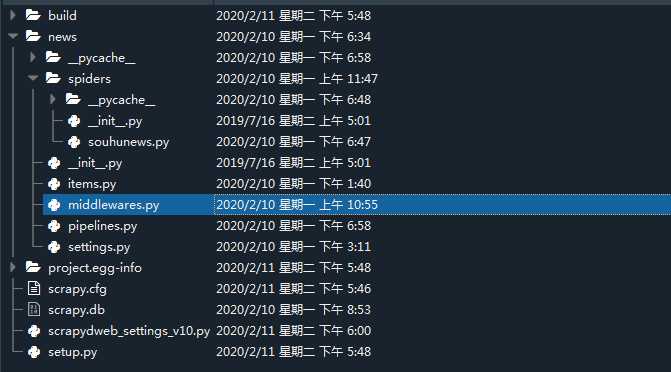
最终文件结构
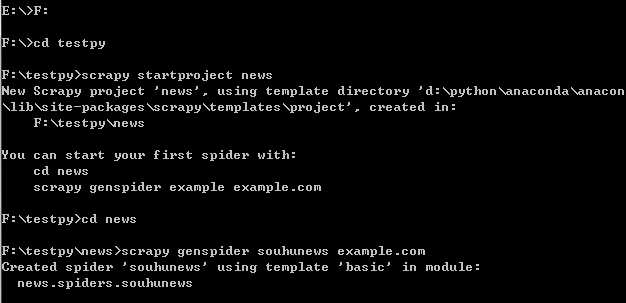
首先在命令提示符中创建基本爬虫文件结构
修改news\ news\spiders\souhunews.py文件:
# -*- coding: utf-8 -*- import scrapy from news.items import NewsItem import sqlite3 import smtplib from email.mime.text import MIMEText class SouhunewsSpider(scrapy.Spider): name = ‘souhunews‘ allowed_domains = [‘sohu.com‘] start_urls = [‘‘‘http://sohu.com/c/8/1463? spm=smpc.null.side-nav.16.1581303075427Zowrm4P‘‘‘] def parse(self, response): conn = sqlite3.connect(‘scrapy.db‘) c = conn.cursor() try: c.execute(‘DROP TABLE books‘) except: pass c.execute(‘‘‘CREATE TABLE books(title text primary key,link text,fro text)‘‘‘) conn.commit() conn.close() it = [] for x in response.xpath("//div[@data-role=‘news-item‘]"): item = NewsItem() item[‘link‘] = x.css("h4>a::attr(href)").get() item[‘title‘] = x.xpath("h4/a/text()").get() item[‘fro‘] = x.xpath("div/span[@class=‘name‘]/a/text()").get() yield item
修改news\ news\items.py文件:
import scrapy class NewsItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() link = scrapy.Field()#链接 title = scrapy.Field()#标题 fro = scrapy.Field()#来源
修改news\ news\pipelines.py文件:
import sqlite3 import smtplib from email.mime.text import MIMEText class NewsPipeline(object): def __init__(self): pass def process_item(self, item, spider): return item class SQLitePipeline(object): #打开数据库 def open_spider(self, spider): db_name = spider.settings.get(‘SQLITE_DB_NAME‘, ‘scrapy.db‘) self.db_conn = sqlite3.connect(db_name) self.db_cur = self.db_conn.cursor() #关闭数据库 def close_spider(self, spider): self.db_conn.commit() self.db_conn.close() conn = sqlite3.connect(r‘E:\testpy\news\scrapy.db‘) c = conn.cursor() c.execute(‘‘‘SELECT * FROM books‘‘‘) data = c.fetchall() conn.commit() conn.close() txt = ‘‘ for d in data: txt = txt+‘‘‘<p>标题:{}</p><p><a href = ‘{}‘>链接</a></p><p>来源:{}</p>‘‘‘.format(d[0],d[1],d[2]) #邮件模块 user = ‘#########@qq.com‘ pwd = ‘#############‘#注意不是密码 to = ‘#############@qq.com‘ msg = MIMEText(txt,‘html‘,‘utf-8‘) msg[‘Subject‘] = ‘News‘ msg[‘From‘] = user msg[‘To‘] = to s = smtplib.SMTP() s.connect(‘smtp.qq.com‘,25) s.login(user,pwd) s.sendmail(user,to,msg.as_string()) s.quit() #对数据进行处理 def process_item(self, item, spider): self.insert_db(item) return item #插入数据 def insert_db(self, item): values = ( (item[‘title‘][2:-2]).strip(), item[‘link‘][2:], item[‘fro‘] ) sql = ‘INSERT INTO books VALUES(?,?,?)‘ self.db_cur.execute(sql, values)
在news\ news\settings.py文件中添加代码(是添加不是替换):
ITEM_PIPELINES = { ‘news.pipelines.SQLitePipeline‘: 400, }#对应管道中的SQLite数据库操作 SQLITE_DB_NAME = ‘scrapy.db‘
最后命令提示符中输入
scrapy crawl souhunews
pip install scrapyd
pip install scrapyd-client
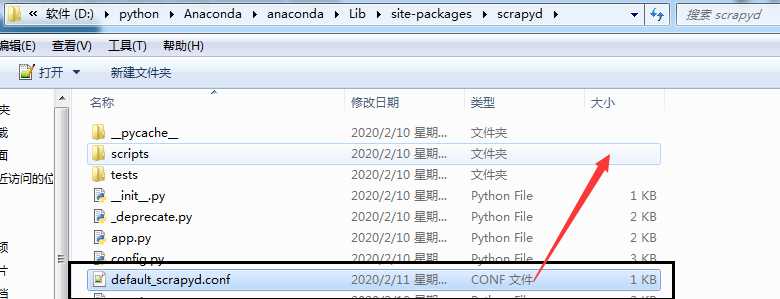
安装完,在命令提示符中启动scrapyd,然后打开default_scrapyd.conf文件修改里面参数 bind_address = 0.0.0.0
打开两个命令提示符端口,一个窗口县启动scrapyd,输入scrapyd命令(这一步很重要,不然后面会报Deploy failed错误)
修改news\ news\scrapy.cfg文件
[settings] default = news.settings [deploy:demo] url = http://localhost:6800/ project = news
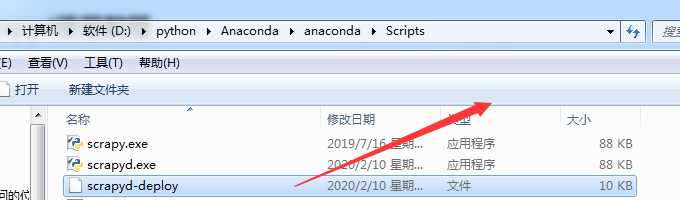
定位文件scrapyd-deploy文件位置,在其所在文件夹内,创建scrapyd-deploy.bat文件,内容是(里面位置信息自己修改)
@echo off
"D:\python\Anaconda\anaconda\python.exe" "D:\python\Anaconda\anaconda\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
命令提示符内定位到news文件夹,然后输入:
scrapyd-deploy demo -p souhunews
url http://localhost:6800/daemonstatus.json -d project=news -d spider = souhunews
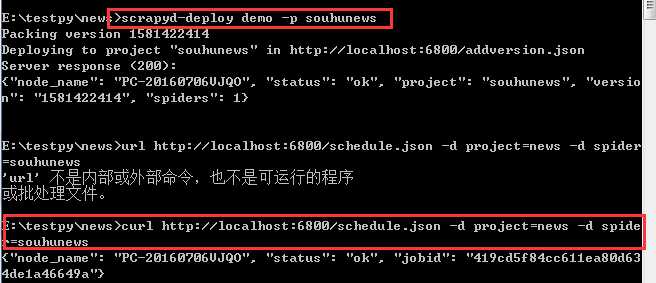
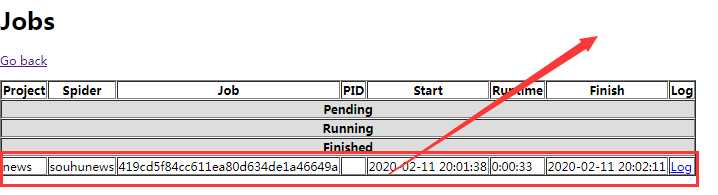
然后查看网页127.0.0.1:6800
确保scrapyd启动的情况下,在命令提示符中输入scrapydweb
修改news\scrapydweb_settings_v10.py,
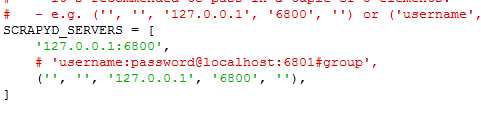
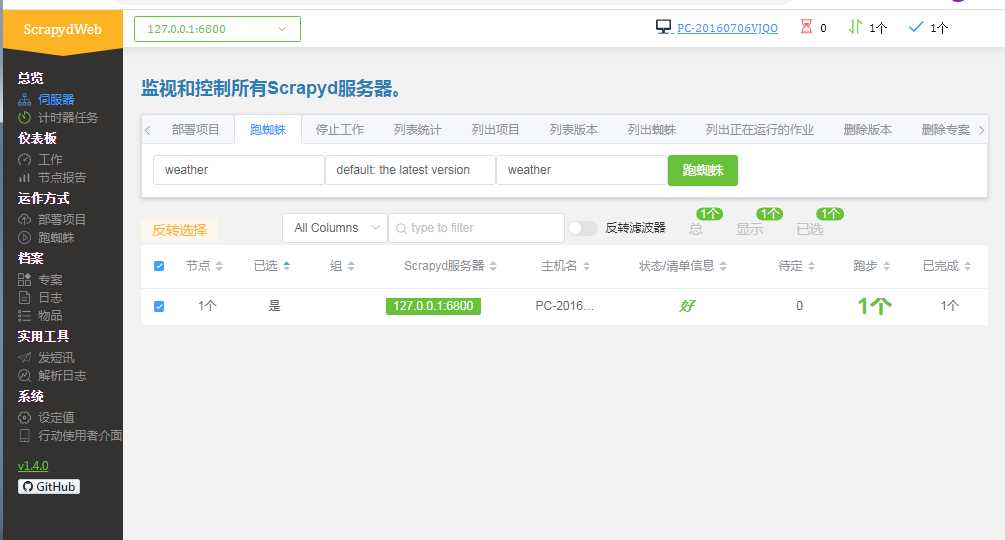
命令提示符内重新输入:scrapydweb,然后访问http://127.0.0.1:5000
后面自己看:https://github.com/my8100/files/blob/master/scrapydweb/README.md
最后发现一个问题,每次邮件发的内容都一样,可能是数据库的原因。
https://www.jianshu.com/p/ddd28f8b47fb
https://www.jianshu.com/p/060ffe018491
https://www.cnblogs.com/du-jun/p/10515376.html
https://scrapyd.readthedocs.io/en/stable/
https://www.jianshu.com/p/1df101fe6408
https://github.com/my8100/files/blob/master/scrapydweb/README.md
原文:https://www.cnblogs.com/puddingsmall/p/12296415.html