一、Tensor
a) 张量是torch的基础数据类型
b) 张量的核心是坐标的改变不会改变自身性质。
c) 0阶张量为标量(只有数值,没有方向的量),因为它不随坐标的变化发生改变
d) 一阶张量为矢量(即向量),他也不随坐标变化而发生变化
e) 二阶张量为矩阵
f) 生成tensor时的通用参数
i. 转换数值类型:
常见生成tensor的参数:dtype。Tensor默认的分量构成为float64
比如生成由长整型构成的全为0的tensor:torch.zeros(2,3,dtype=torch.long)
ii. 指定存放容器:
参数:device。可赋值:cpu/gpu
g) 创建未初始化的张量:empty(raw, col)
h) 创建随机初始化的张量:rand(raw,col)
i) 创建分量均为0的张量:zeros(raw,col)
j) 直接根据数据创建向量:tensor(factor)。factor是一个用数字构成的list,只能写一个list,即tensor函数只能生成向量
k) 其他的张量生成函数: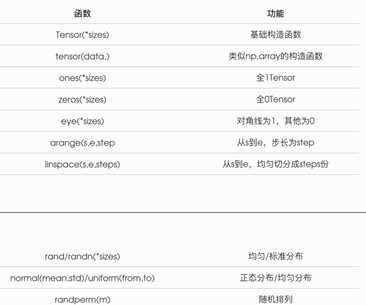
l) 获取维度信息:x.size()。输出结果为元组
m) x.new_*(size):创建一个tensor,复制x的dtype和device。星号位置可以写任意的tensor生成函数。可以赋值强行修改dtype和device
n)
*_like(tensor):创建一个size和tensor一样的张量。。星号位置可以写任意的tensor生成函数
二、算术(这里的x、y均为张量)
a) 加法:
i. x+y
ii. torch.add(x,y, result=var)。如果设定了result参数,那么加法的结果会储存在var中,此时就不用再写z=torch.add()了
iii. y.add_(x)
b) 矩阵运算:
i. torch.mul(a, b)是矩阵a和b对应位相乘,a和b的维度必须相等,比如a的维度是(1, 2),b的维度是(1, 2),返回的仍是(1, 2)的矩阵
ii. torch.mm(a, b)是矩阵a和b矩阵相乘,比如a的维度是(1, 2),b的维度是(2, 3),返回的就是(1, 3)的矩阵
c) 线代运算:
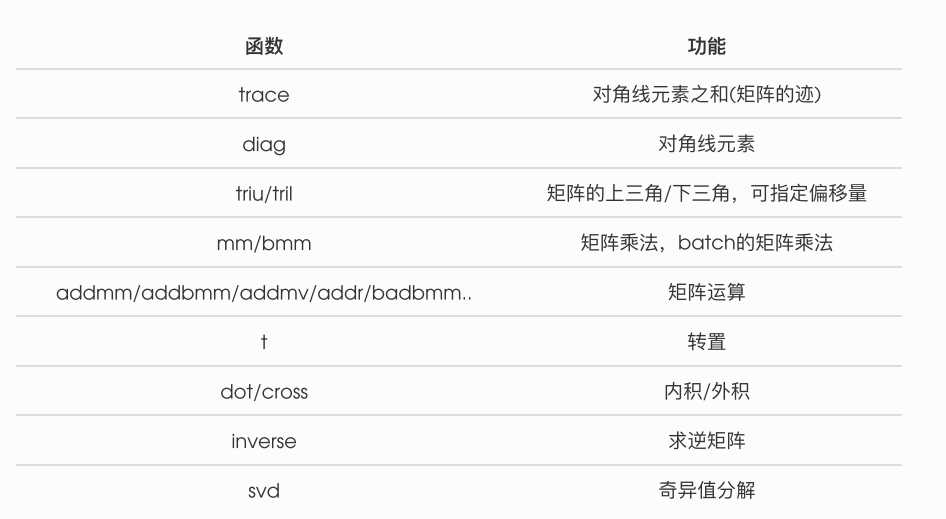
d) 非相同形状的tensor的运算处理:广播机制
i. 广播机制的定义:先适当复制元素使这两个 Tensor 形状相同后再按元素运算
ii. 由于 x 和 y 分别是1行2列和3行1列的矩阵,如果要计算 x + y ,那么 x 中第?行的2个元素被广播 (复制)到了了第二行和第三行,而 y 中第一列的3个元素被广播(复制)到了第二列。
如此,就可以对2个3行2列的矩阵按元素相加。
1 x = torch.arange(1, 3).view(1, 2) 2 print(x) 3 y = torch.arange(1, 4).view(3, 1) 4 print(y) 5 print(x + y) 6 7 tensor([[1, 2]]) 8 tensor([[1], [2], [3]]) 9 tensor([[2, 3], [3, 4], [4, 5]])
三、索引
a) 索引出来的结果与原数据共享内存,也即修改一个,另?个会跟着修改
b) X[:,0]是numpy中数组的一种写法,torch也是类似的。表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据,直观来说,X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据。
c) [m,n]:索引的数字为第m项到第n-1项
d) 其余索引: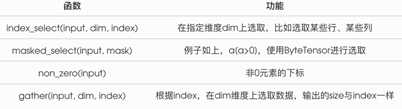
index_select():
input:要筛选的tensor
dim的参数:0或1。参数0表示按行索引,1表示按列进行索引
index:用tensor表示
例子:
import torch input_tensor = torch.tensor([1,2,3,4,5]) print(input_tensor.index_select(0,torch.tensor([0,2,4]))) input_tensor = torch.tensor([[1,2,3,4,5],[6,7,8,9,10]]) print(input_tensor.index_select(0,torch.tensor([1]))) print(input_tensor.index_select(1,torch.tensor([1])))
输出为:
tensor([1, 3, 5]) tensor([[ 6, 7, 8, 9, 10]]) tensor([[2], [7]])
四、改变tensor形状
a) tensor.view(size)
b) 注意 view() 返回的新tensor与源tensor共享内存(其实是同一个tensor),也即更改其中的?个,另外一个也会跟着改变。(顾名思义,view仅仅是改变了对这个张量的观察角度)
1 y = x.view(15) 2 z = x.view(-1, 5) # -1所指的维度可以根据其他维度的值推出来 3 print(x.size(), y.size(), z.size())
torch.Size([5, 3]) torch.Size([15]) torch.Size([3, 5])
c) 如何不影响本体改变shape呢?
使用clone()函数先对本体克隆,再使用view。使用 clone 还有一个好处是会被记录在计算图中,即梯度回传到副本时也会传到源 Tensor
x_cp = x.clone().view(15) x -= 1 print(x) print(x_cp)
tensor([[ 0.6035, 0.8110, -0.0451], [ 0.8797, 1.0482, -0.0445], [-0.7229, 2.8663, -0.5655], [ 0.1604, -0.0254, 1.0739], [ 2.2628, -0.9175, -0.2251]]) tensor([1.6035, 1.8110, 0.9549, 1.8797, 2.0482, 0.9555, 0.2771, 3.8663, 0.4345, 1.1604, 0.9746, 2.0739, 3.2628, 0.0825, 0.7749])
五、内存的使用
a) 前面提到的索引和view并不会开辟新的内存。所以一个变动其他的也会变。但是加法会开辟一个新内存
b) 使用python自带的id函数可以查看内存地址
1 x = torch.tensor([1, 2]) 2 y = torch.tensor([3, 4]) 3 id_before = id(y) 4 y = y + x 5 print(id(y) == id_before) 6 7 8 False
六、数据转换
a) item():将标量tensor转换成python number
1 x = torch.randn(1) 2 print(x) 3 print(x.item()) 4 5 tensor([2.3466]) 6 2.3466382026672363
b) 与numpy的转换
i. numpy():将tensor转化成numpy数组
1 a = torch.ones(5) 2 b = a.numpy() 3 print(a, b) 4 a += 1 5 print(a, b) 6 b += 1 7 print(a, b) 8 9 10 tensor([1., 1., 1., 1., 1.]) [1. 1. 1. 1. 1.] 11 tensor([2., 2., 2., 2., 2.]) [2. 2. 2. 2. 2.] 12 tensor([3., 3., 3., 3., 3.]) [3. 3. 3. 3. 3.]
ii. from_numpy():将numpy数组转化成tensor
1 import numpy as np 2 a = np.ones(5) 3 b = torch.from_numpy(a) 4 print(a, b) 5 a += 1 6 print(a, b) 7 b += 1
print(a, b) 8 9 10 [1. 1. 1. 1. 1.] tensor([1., 1., 1., 1., 1.], dtype=torch.float64) 11 [2. 2. 2. 2. 2.] tensor([2., 2., 2., 2., 2.], dtype=torch.float64) 12 [3. 3. 3. 3. 3.] tensor([3., 3., 3., 3., 3.], dtype=torch.float64)
iii. 根据上面的例子,我们可以发现,numpy和tensor之间的相互转换是共用内存的。一个改变,另一个也改变
iv. tensor():不共用内存将numpy转变成tensor
1 c = torch.tensor(a) #这里的a沿用ii中例子的结果 2 a += 1 3 print(a, c) 4 5 6 [4. 4. 4. 4. 4.] tensor([3., 3., 3., 3., 3.], dtype=torch.float64)
七、处理器的变化
使用to()使tensor在CPU与GPU之间相互移动
1 # 以下代码只有在PyTorch GPU版本上才会执行 2 if torch.cuda.is_available(): 3 device = torch.device("cuda") #创建device在GPU。cuda是一个英伟达开发的并行 4 y = torch.ones_like(x, device=device) # 直接创建一个在GPU上的tensor 5 x = x.to(device) #等价于 .to("cuda") 6 z = x + y 7 print(z) 8 print(z.to("cpu", torch.double)) # to()还可以同时更更改数据类型
原文:https://www.cnblogs.com/PKU-CD/p/12297941.html