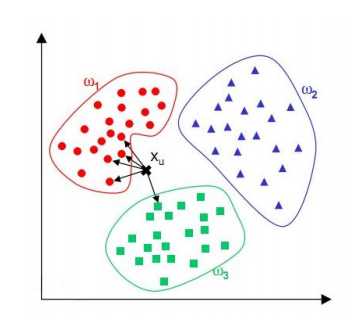
区别在于假设某一特征的所有属于某个类别的观测值符合特定分布,如,分类问题的特征包括人的身高,身高符合高斯分布,这类问题适合高斯朴素贝叶斯。
在sklearn库中,可以使用sklearn.naive_bayes.GaussianNB创建一个高斯朴素贝叶斯分类器,其参数有:
• priors :给定各个类别的先验概率。如果为空,则按训练数据的实际情况进行统计;如果给定先验概率,则在训练过程中不能更改。
朴素贝叶斯的使用
例1:导入 numpy 库,并构造训练数据 X 和 y。
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> Y = np.array([1, 1, 1, 2, 2, 2])
使用 import 语句导入朴素贝叶斯分类器。
>>> from sklearn.naive_bayes import GaussianNB
使用默认参数,创建一个高斯朴素贝叶斯分类器,并将该分类器赋给变量clf。
>>> clf = GaussianNB(priors=None)
类似的,使用 fit() 函数进行训练,并使用 predict() 函数进行预测,得到预测结果为 1。(测试时可以构造二维数组达到同时预测多个样本的目的)
>>> clf.fit(X, Y)
>>> print(clf.predict([[-0.8, -1]]))
[1]