理解决策树
决策树是随机森林的基本构成要素,而且是一种直观的模型。我们可以将决策树视为一系列关于数据的是/否问题,从而最终得出一个预测类别(或回归情况下的连续值)。 这是一个可解释的模型,因为它非常像我们人类进行分类的过程:在我们做出决定之前(在理想世界中),我们会对可用数据进行一系列的询问。
决策树的技术细节在于如何形成关于数据的问题。在CART算法中,通过确定问题(称为节点的分裂)来构建决策树,这些问题在得到应答时会导致基尼不纯度(Gini Impurity)的最大减少。这意味着决策树试图形成包含来自单个类的高比例样本(数据点)的节点,这个过程通过在能将数据干净地划分为不同类的特征中找到适当的值来实现。
可视化决策树
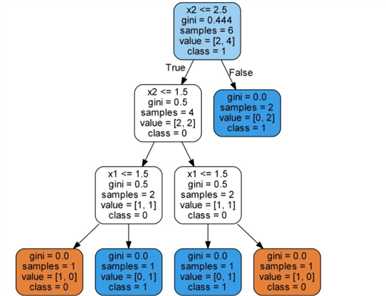
简单的决策树
除叶子节点(彩色终端节点)外,所有节点都有5个部分:
叶节点中不再提问,因为这里已经产生了最终的预测。要对某个新数据点进行分类,只需沿着树向下移动,使用新点的特征来回答问题,直到到达某个叶节点,该叶节点对应的分类就是最终的预测。
原文:https://www.cnblogs.com/xpb0329/p/12313291.html