newff(n.neurons, learning.rate.global, momentum.global, error.criterium, Stao, hidden.layer, output.layer, method)
"LMS":Least Mean Squares
"LMLS":Least Mean Logarithm Squared
"TAO":TAO Error
"ADAPTgd": Adaptative gradient descend.(自适应的梯度下降方法)
"ADAPTgdwm": Adaptative gradient descend with momentum.(基于动量因子的自适应梯度下降方法)
"BATCHgd": BATCH gradient descend.(批量梯度下降方法)
"BATCHgdwm": BATCH gradient descend with momentum.(基于动量因子的批量梯度下降方法)
train(net, P, T, Pval=NULL, Tval=NULL, error.criterium="LMS", report=TRUE, n.shows, show.step, Stao=NA, prob=NULL, n.threads=0L)
library(AMORE)
# P is the input vector
P <- matrix(sample(seq(-1,1,length=1000), 1000, replace=FALSE), ncol=1)
# The network will try to approximate the target P^2
target <- P^2
# We create a feedforward network, with two hidden layers.
# The first hidden layer has three neurons and the second has two neurons.
# The hidden layers have got Tansig activation functions and the output layer is Purelin.
net <- newff(n.neurons=c(1,3,2,1), learning.rate.global=1e-2, momentum.global=0.5,
error.criterium="LMS", Stao=NA, hidden.layer="tansig",
output.layer="purelin", method="ADAPTgdwm")
result <- train(net, P, target, error.criterium="LMS", report=TRUE, show.step=100, n.shows=5 )
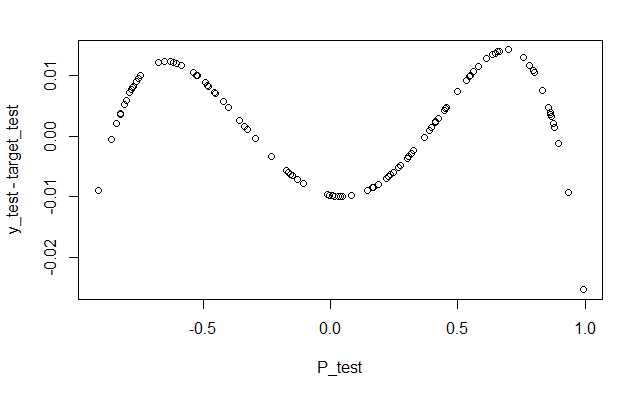
P_test <- matrix(sample(seq(-1,1,length=1000), 100, replace=FALSE), ncol=1)
target_test <- P_test^2
y_test <- sim(result$net, P_test)
plot(P_test,y_test-target_test,lty=1)
index.show: 1 LMS 0.0893172434474773
index.show: 2 LMS 0.0892277761187557
index.show: 3 LMS 0.000380711026069436
index.show: 4 LMS 0.000155618390342181
index.show: 5 LMS 9.53881309223154e-05
原文:https://www.cnblogs.com/dingdangsunny/p/12325437.html