shoes表结构

在此表中,shoes_name可能有重复,本篇博客记录如何去除重复数据。
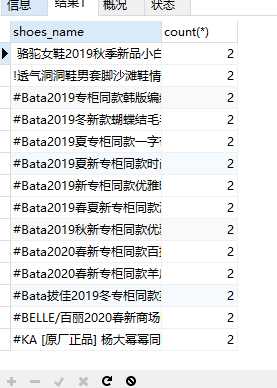
1.首先要知道哪些数据是重复的, 可用group by 聚集函数找到:
SELECT shoes_name,count(*) from shoes GROUP BY shoes_name having COUNT(*)>1
注:having 一般和group连用,用来限制查到的结果,这里的意思是将shoes表按shoes_name组,count(*)计算每组的条数,hiving限制显示条数大于1的结果,即有重复的数据。
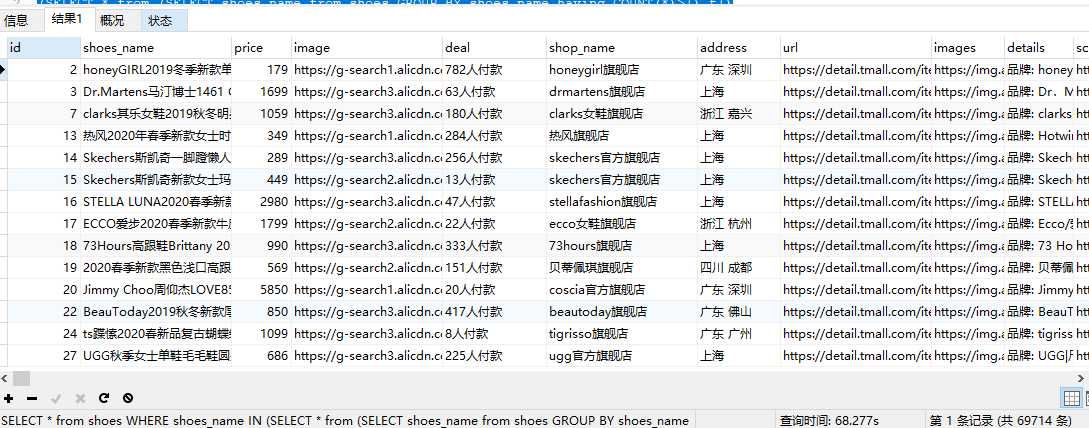
2.根据第一步中获得的shoes_name来获得所有重复的数据
SELECT * from shoes WHERE shoes_name IN( SELECT * from ( SELECT shoes_name from shoes GROUP BY shoes_name having COUNT(*)>1) t1 )
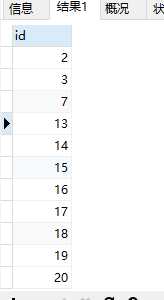
3.因为删除时我们要保留id最小的数据行,所以我们要查找最小的id。
SELECT id from shoes WHERE id in ( SELECT * from ( select MIN(id) from shoes GROUP BY shoes_name having COUNT(*)>1 )t2 )
4.删除这些重复数据,只保留最小的table_id
DELETE from shoes where shoes_name IN( SELECT * from( SELECT shoes_name FROM shoes GROUP BY shoes_name having COUNT(*)>1 )t1 ) AND id not IN( SELECT * from ( select MIN(id) from shoes GROUP BY shoes_name having COUNT(*)>1 )t2 )
原文:https://www.cnblogs.com/qilin20/p/12335742.html