import requests
import re
import xlwt
url = ‘https://news.cnblogs.com/n/recommend‘
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
def get_page(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(‘获取网页成功‘)
print(response.encoding)
return response.text
else:
print(‘获取网页失败‘)
except Exception as e:
print(e)
f = xlwt.Workbook(encoding=‘utf-8‘)
sheet01 = f.add_sheet(u‘sheet1‘, cell_overwrite_ok=True)
sheet01.write(0, 0, ‘博客最热新闻‘) # 第一行第一列
urls = [‘https://news.cnblogs.com/n/recommend?page={}‘.format(i * 1) for i in range(100)]
temp=0
num=0
for url in urls:
print(url)
page = get_page(url)
items = re.findall(‘<h2 class="news_entry">.*?<a href=".*?" target="_blank">(.*?)</a>‘,page,re.S)
print(len(items))
print(items)
for i in range(len(items)):
sheet01.write(temp + i + 1, 0, items[i])
temp += len(items)
num+=1
print("已打印完第"+str(num)+"页")
print("打印完!!!")
f.save(‘Hotword.xls‘)
爬取结果截图:

然后继续在爬取结果里面进行筛选,选出100个出现频率最高的信息热词。
Python代码:
import jieba
import pandas as pd
import re
from collections import Counter
if __name__ == ‘__main__‘:
filehandle = open("Hotword.txt", "r", encoding=‘utf-8‘);
mystr = filehandle.read()
seg_list = jieba.cut(mystr) # 默认是精确模式
print(seg_list)
# all_words = cut_words.split()
# print(all_words)
stopwords = {}.fromkeys([line.rstrip() for line in open(r‘final.txt‘,encoding=‘UTF-8‘)])
c = Counter()
for x in seg_list:
if x not in stopwords:
if len(x) > 1 and x != ‘\r\n‘:
c[x] += 1
print(‘\n词频统计结果:‘)
for (k, v) in c.most_common(100): # 输出词频最高的前两个词
print("%s:%d" % (k, v))
# print(mystr)
filehandle.close();
# seg2 = jieba.cut("好好学学python,有用。", cut_all=False)
# print("精确模式(也是默认模式):", ‘ ‘.join(seg2))
里面的那个final.txt是将那些单词比如“我们”,“什么”,“中国”,“没有”,这些句子常出现的词语频率高但是跟信息没有关系的词语,我们将他们首先排除。
final.txt:

这个txt有需要的,联系Q:893225523
运行结果:

然后将他们存入txt,导入mysql。
之后我们继续进行爬取,爬取百度百科每个热词的解释。
Python源代码:
import requests
import re
import xlwt
import linecache
url = ‘https://baike.baidu.com/‘
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
def get_page(url):
try:
response = requests.get(url, headers=headers)
response.encoding = ‘utf-8‘
if response.status_code == 200:
print(‘获取网页成功‘)
#print(response.encoding)
return response.text
else:
print(‘获取网页失败‘)
except Exception as e:
print(e)
f = xlwt.Workbook(encoding=‘utf-8‘)
sheet01 = f.add_sheet(u‘sheet1‘, cell_overwrite_ok=True)
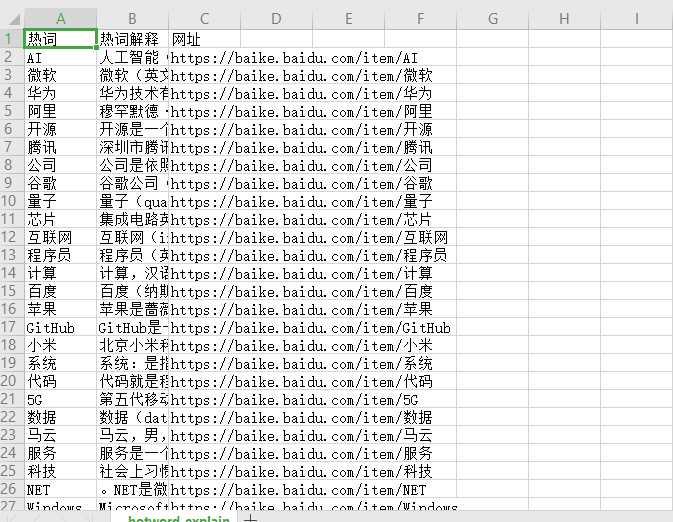
sheet01.write(0, 0, ‘热词‘) # 第一行第一列
sheet01.write(0, 1, ‘热词解释‘) # 第一行第二列
sheet01.write(0, 2, ‘网址‘) # 第一行第三列
fopen = open(‘C:\\Users\\hp\\Desktop\\final_hotword2.txt‘, ‘r‘,encoding=‘utf-8‘)
lines = fopen.readlines()
urls = [‘https://baike.baidu.com/item/{}‘.format(line) for line in lines]
i=0
for url in urls:
print(url.replace("\n", ""))
page = get_page(url.replace("\n", ""))
items = re.findall(‘<meta name="description" content="(.*?)">‘,page,re.S)
print(items)
if len(items)>0:
sheet01.write(i + 1, 0,linecache.getline("C:\\Users\\hp\\Desktop\\final_hotword2.txt", i+1).strip())
sheet01.write(i + 1, 1,items[0])
sheet01.write(i + 1, 2,url.replace("\n", ""))
i+= 1
print("总爬取完毕数量:" + str(i))
print("打印完!!!")
f.save(‘hotword_explain.xls‘)
刚开始我爬取的时候,在确定正则表达式正确的情况下,爬取结果一直都是乱码。然后加上 response.encoding = ‘utf-8‘,就OK了。
爬取结果:
将其存入数据库。
之后打开eclipse,用javaweb实现数据可视化和热词目录。
jsp源代码:
<%@ include file="left.jsp"%>
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
<script src="https://cdn.staticfile.org/echarts/4.3.0/echarts.min.js"></script>
<script src="js/jquery-1.5.1.js"></script>
<script src="js/echarts-all.js"></script>
</head>
<body>
<div style="position:absolute;left:400px;top:20px;">
<div id="main" style="width: 1000px;height:400px;"></div>
</div>
</body>
<script type="text/javascript">
var myChart = echarts.init(document.getElementById(‘main‘));
var statisticsData =[];
myChart.showLoading();
$.ajax({
type : "post",
async : true, //异步请求(同步请求将会锁住浏览器,其他操作须等请求完成才可执行)
url : "servlet?method=find", //请求发送到Servlet
data : {},
dataType : "json", //返回数据形式为json
//7.请求成功后接收数据name+num两组数据
success : function(result) {
//result为服务器返回的json对象
if (result) {
//8.取出数据存入数组
for (var i = 0; i <result.length; i++) {
var statisticsObj = {name:‘‘,value:‘‘}; //因为ECharts里边需要的的数据格式是这样的
statisticsObj.name =result[i].hotwords;
statisticsObj.value =result[i].num;
//alert( statisticsObj.name);
//alert(statisticsObj.value);
statisticsData.push(statisticsObj);
}
//alert(statisticsData);
//把拿到的异步数据push进我自己建的数组里
myChart.hideLoading();
//9.覆盖操作-根据数据加载数据图表
var z1_option = {
title : {
text:‘热词图‘
},
series: [{
type: ‘wordCloud‘,
gridSize: 20,
sizeRange: [12, 50],
rotationRange: [-90, 90],
shape: ‘pentagon‘,
textStyle: {
normal: {
color: function() {
return ‘rgb(‘ + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(‘,‘) + ‘)‘;
}
},
emphasis: {
shadowBlur: 10,
shadowColor: ‘#333‘
}
},
data: statisticsData
}]
};
myChart.setOption(z1_option, true);
}
},
})
</script>
</html>
dao层代码:
package com.hotwords.dao;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import com.hotwords.entity.entity;
public class dao {
public List<entity> list1(){
List<entity> list =new ArrayList<entity>();
try {
// 加载数据库驱动,注册到驱动管理器
Class.forName("com.mysql.jdbc.Driver");
// 数据库连接字符串
String url = "jdbc:mysql://localhost:3306/xinwen?useUnicode=true&characterEncoding=utf-8";
// 数据库用户名
String username = "root";
// 数据库密码
String password = "893225523";
// 创建Connection连接
Connection conn = DriverManager.getConnection(url, username,
password);
// 添加图书信息的SQL语句
String sql = "select * from final_hotword";
// 获取Statement
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
entity book = new entity();
book.setHotwords(resultSet.getString("热词"));
book.setNum(resultSet.getString("次数"));
list.add(book);
}
resultSet.close();
statement.close();
conn.close();
}catch (Exception e) {
e.printStackTrace();
}
return list;
}
//
public List<entity> list2(){
List<entity> list =new ArrayList<entity>();
try {
// 加载数据库驱动,注册到驱动管理器
Class.forName("com.mysql.jdbc.Driver");
// 数据库连接字符串
String url = "jdbc:mysql://localhost:3306/xinwen?useUnicode=true&characterEncoding=utf-8";
// 数据库用户名
String username = "root";
// 数据库密码
String password = "893225523";
// 创建Connection连接
Connection conn = DriverManager.getConnection(url, username,
password);
// 添加图书信息的SQL语句
String sql = "select * from website";
// 获取Statement
Statement statement = conn.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
entity book = new entity();
book.setHotwords(resultSet.getString("热词"));
book.setExplain(resultSet.getString("解释"));
book.setWebsite(resultSet.getString("网址"));
list.add(book);
}
resultSet.close();
statement.close();
conn.close();
}catch (Exception e) {
e.printStackTrace();
}
return list;
}
}
servlet层:
package com.hotwords.servlet;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import com.hotwords.dao.dao;
import com.hotwords.entity.entity;
import com.google.gson.Gson;
/**
* Servlet implementation class servlet
*/
@WebServlet("/servlet")
public class servlet extends HttpServlet {
private static final long serialVersionUID = 1L;
dao dao1=new dao();
/**
* @see HttpServlet#HttpServlet()
*/
public servlet() {
super();
// TODO Auto-generated constructor stub
}
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
String method=request.getParameter("method");
if("find".equals(method))
{
find(request, response);
}else if("find2".equals(method))
{
find2(request, response);
}
}
private void find(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException {
request.setCharacterEncoding("utf-8");
List<entity> list =new ArrayList<entity>();
HttpSession session=request.getSession();
String buy_nbr=(String) session.getAttribute("userInfo");
entity book = new entity();
List<entity> list2=dao1.list1();
System.out.println(list2.size());
// String buy_nbr=(String) session.getAttribute("userInfo");
// System.out.println(buy_nbr);
Gson gson2 = new Gson();
String json = gson2.toJson(list2);
System.out.println(json);
// System.out.println(json);
// System.out.println(json.parse);
response.setContentType("text/html;charset=UTF-8");
response.getWriter().write(json);
}
private void find2(HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException {
request.setCharacterEncoding("utf-8");
request.setAttribute("list",dao1.list2());
request.getRequestDispatcher("NewFile1.jsp").forward(request, response);
}
}
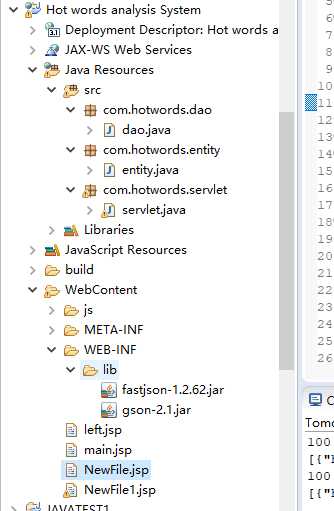
项目结构:
记得一定要加上 echars-all.js要不热词图不能显示。
运行结果:


那么基本功能就完成了,但是那个导出word还没有实现。
原文:https://www.cnblogs.com/jccjcc/p/12342171.html